标签:
只有当查询优化,索引优化,库表结构优化齐头并进时,才能实现mysql高性能。
在尝试编写快速的查询之前,需要清楚一点,真正重要是响应时间。
通常来说,查询的生命周期大致可以按照顺序来看:从客户端,到服务器,然后再服务器上进行解析,生成执行计划,执行,并返回结果给客户端。
其中"执行"可以认为是整个生命周期最重要的阶段,这其中包括了大量为了检索数据到存储引擎的调用以及调用后的数据处理,包括排序,分组等。
对于一个查询的全部生命周期,上面列的并不完整。这里我们只是想说:了解查询的生命周期,清楚查询的时间消耗情况对于优化查询有很大的意义。
慢查询基础:优化数据访问
1.是否向数据库请求了不需要的数据
2.mysql是否扫描额外的纪录
查询是否扫描了过多的数据。最简单的衡量查询开销三个指标如下:
响应时间。
扫描的行数。
返回的行数。
没有哪个指标能够完美地衡量查询的开销,但它们大致反映了mysql在内部执行查询时需要多少数据,并可以推算出查询运行的时间。
这三个指标都会记录到mysql的慢日志中,所以检查慢日志记录是找出扫描行数过多的查询的好办法。
响应时间:
是两个部分之和:服务时间和排队时间。
服务时间是指数据库处理这个查询真正花了多长时间。
排队时间是指服务器因为等待某些资源而没有真正执行查询的时间。---可能是等io操作完成,也可能是等待行锁,等等。
扫描的行数和返回的行数:
分析查询时,查看该查询扫描的行数是非常有帮助的。这在一定程度上能够说明该查询找到需要的数据的效率高不高。
扫描的行数和访问类型:
在expain语句中的type列反应了访问类型。访问类型有很多种,
从全表扫描(ALL)到
索引扫描(index)到
范围扫描()到
唯一索引查询 到
常数引用等。这里列的这些,速度由慢到快,扫描的行数也是从小到大。
如果发现查询需要扫描大量的数据但只返回少数的行,那么通常可以尝试下面的技巧去优化它:
使用索引覆盖扫描。
改变库表结构。例如使用单独的汇总表。
重写这个复杂的查询。让mysql优化器能够以更优化的方式执行这个查询。
重构查询的方式:
1.一个复杂查询 or 多个简单查询
设计查询的时候一个需要考虑的重要问题是,是否需要将一个复杂的查询分成多个简单的查询。
2.切分查询
有时候对于一个大查询我们需要“分而治之”,将大查询切分为小查询,每个查询功能完全一样,只完成一小部分,每次
只返回一小部分查询结果。
3.分解关联查询
select * from tag
join tag_post on tag_post.tag_id = tag.id
join post on tag_post.post_id = post.id
where tag.tag = ‘mysql‘
可以分解成下面这些查询来代替:
> select * from tag where tag = ‘mysql‘
> select * from tag_post where tag_id = 1234
> select * from post where post_id in (123, 456, 567, 9098, 8904)
优势:
让缓存的效率更高。
将查询分解后,执行单个查询可以减少锁的竞争。
在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
查询本身效率也可能会有所提升。
可以减少冗余记录的查询,
更进一步,这样做相当于在应用中实现了哈希关联,而不是使用mysql的嵌套循环关联。
查询执行的基础:
当希望mysql能够以更高的性能运行查询时,最好的办法就是农清楚mysql是如何优化和查询的。
一旦理解这一点,很多查询优化工作实现上就是遵循一些原则让优化器能够按照预想的合理的方式运行。
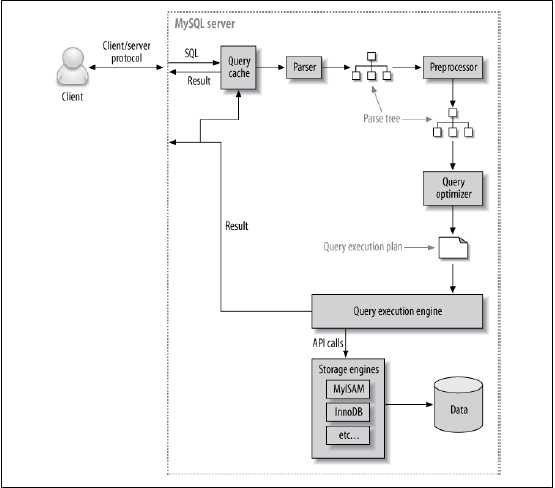
1.客户端发送一条查询给服务器
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段。
3.服务器进行SQL解析,预处理,再由优化器生成对应的执行计划,
4.mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5.将结果返回给客户端。
标签:
原文地址:http://www.cnblogs.com/w2154/p/4691015.html