标签:数据库分页查询 mysql分页查询 oracle分页查询 sqlserver分页查询
MySql:
MySQL数据库实现分页比较简单,提供了 LIMIT函数。一般只需要直接写到sql语句后面就行了。
LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数。例如:
select * from table LIMIT 10; #返回前10行
select * from table LIMIT 0,10; #返回前10行
select * from table limit 5,10; #返回第6-15行数据 第一个参数是指要开始的地方,第二个参数是指每页显示多少条数据;注意:第一页用0表示
Oracle:
考虑mySql中的实现分页,select * from 表名 limit 开始记录数,显示多少条;就可以实现我们的分页效果。
但是在oracle中没有limit关键字,但是有 rownum字段
rownum是一个伪列,是oracle系统自动为查询返回结果的每行分配的编号,第一行为1,第二行为2,以此类推。。。。
第一种:
其中最内层的查询SELECT * FROM TABLE_NAME表示不进行翻页的原始查询语句。ROWNUM <= 40和RN >= 21控制分页查询的每页的范围。
上面给出的这个分页查询语句,在大多数情况拥有较高的效率。分页的目的就是控制输出结果集大小,将结果尽快的返回。在上面的分页查询语句中,这种考虑主要体现在WHERE ROWNUM <= 40这句上。
选择第21到40条记录存在两种方法,一种是上面例子中展示的在查询的第二层通过ROWNUM <= 40来控制最大值,在查询的最外层控制最小值。而另一种方式是去掉查询第二层的WHERE ROWNUM <= 40语句,在查询的最外层控制分页的最小值和最大值。
第二种:
红色部分:按照工资降序排序并查询所有的信息。
棕色部分:得到红色部门查询的值,并查询出系统的rownum并指定上别名。这一句就比较关键,起了一个过渡的作用,首先要算出rownum来对红色部分指定上序号,也可以为蓝色外面部分用到这个变量。指定上查询的开始记录数和结束记录的条件。
蓝色部分:指定记录从第几条开始到第几条结束,取出棕色部门的值来作为查询条件的变量
总结:绝大多数的情况下,第一个查询的效率比第二个高得多。
SqlServer:
分页方案一:(利用Not In和SELECT TOP分页)
语句形式:
SELECT TOP 页大小 * FROM TestTable WHERE (ID NOT IN (SELECT TOP 页大小*页数 id FROM 表 ORDER BY id)) ORDER BY ID
分页方案二:(利用ID大于多少和SELECT TOP分页)
语句形式:
SELECT TOP 页大小 * FROM TestTable WHERE (ID > (SELECT MAX(id) FROM (SELECT TOP 页大小*页数 id FROM 表 ORDER BY id) AS T)) ORDER BY ID
分页方案三:(利用SQL的游标存储过程分页)
@sqlstr nvarchar(4000), --查询字符串
@currentpage int, --第N页
@pagesize int --每页行数
as
set nocount on
declare @P1 int, --P1是游标的id
@rowcount int
exec sp_cursoropen @P1 output,@sqlstr,@scrollopt=1,@ccopt=1,@rowcount=@rowcount output
select ceiling(1.0*@rowcount/@pagesize) as 总页数--,@rowcount as 总行数,@currentpage as 当前页
set @currentpage=(@currentpage-1)*@pagesize+1
exec sp_cursorfetch @P1,16,@currentpage,@pagesize
exec sp_cursorclose @P1
set nocount off
其它的方案:如果没有主键,可以用临时表,也可以用方案三做,但是效率会低。
建议优化的时候,加上主键和索引,查询效率会提高。
通过SQL 查询分析器,显示比较:结论是:
分页方案二:(利用ID大于多少和SELECT TOP分页)效率最高,需要拼接SQL语句
分页方案一:(利用Not In和SELECT TOP分页) 效率次之,需要拼接SQL语句
分页方案三:(利用SQL的游标存储过程分页) 效率最差,但是最为通用
在实际情况中,要具体分析。
====================================================================
数据库分页大全(oracle利用解析函数row_number高效分页)
Mysql分页采用limt关键字
select * from t_order limit 5,10; #返回第6-15行数据 第一个参数是指要开始的地方,第二个参数是指每页显示多少条数据;注意:第一页用0表示。
select * from t_order limit 5; #返回前5行
select * from t_order limit 0,5; #返回前5行
Mssql 2000分页采用top关键字(20005以上版本也支持关键字rownum)
Select top 10 * from t_order where id not in (select id from t_order where id>5 ); //返回第6到15行数据
其中10表示取10记录 5表示从第5条记录开始取
Oracle分页
①采用rownum关键字(三层嵌套)
SELECT * FROM ( SELECT A.*,ROWNUM num FROM ( SELECT * FROM t_order ) A WHERE ROWNUM<=15 ) WHERE num>=5;--返回第5-15行数据
②采用row_number解析函数进行分页(效率更高)
SELECT xx.* FROM( SELECT t.*,row_number() over(ORDER BY o_id)AS num FROM t_order t )xx WHERE num BETWEEN 5 AND 15; --返回第5-15行数据
解析函数能用格式
函数() over(pertion by 字段 order by 字段);
Pertion 按照某个字段分区
Order 按照勒个字段排序
数据库表结构及记录如下:
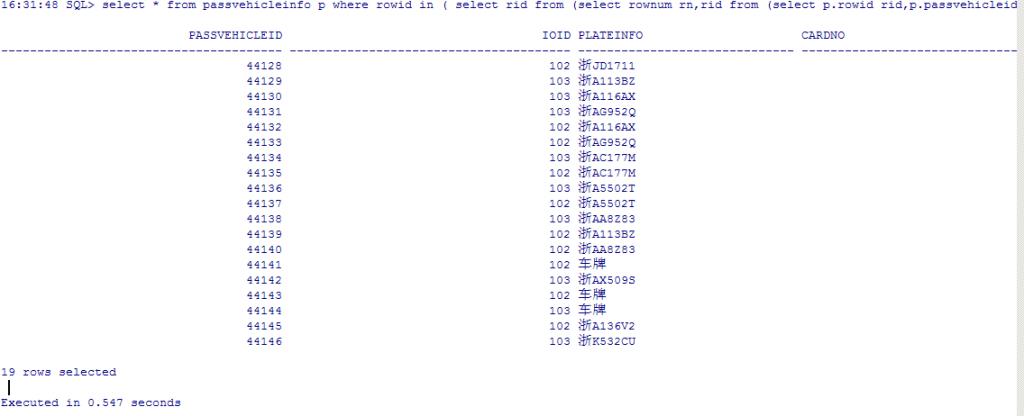
1.根据rowid来分:
16:31:48 SQL> select * from passvehicleinfo p where rowid in ( select rid from (select rownum rn,rid from (select p.rowid rid,p.passvehicleid from passvehicleinfo p order by p.passvehicleid desc) view1 where rownum<10000) view2 where rn >9980)order by p.passvehicleid asc;
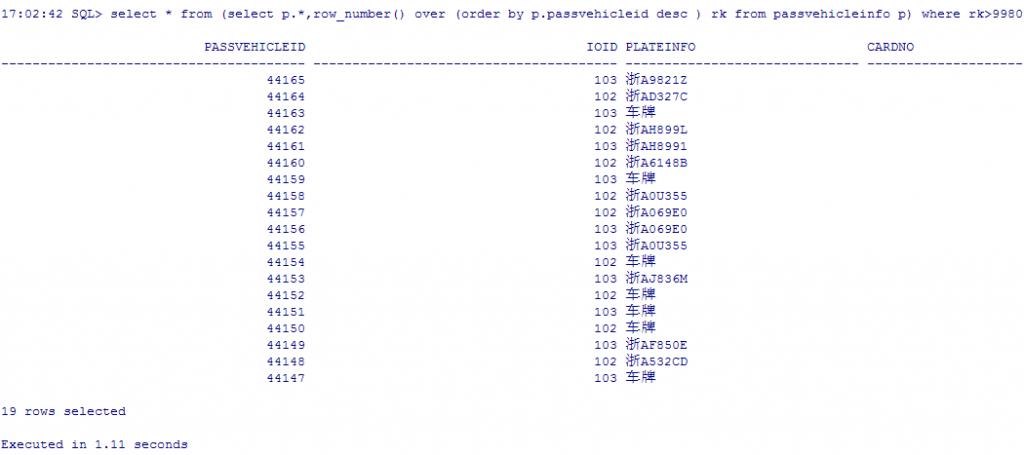
 2.按分析函数来分
2.按分析函数来分
17:02:42 SQL> select * from (select p.*,row_number() over (order by p.passvehicleid desc ) rk from passvehicleinfo p) where rk>9980 and rk<10000;
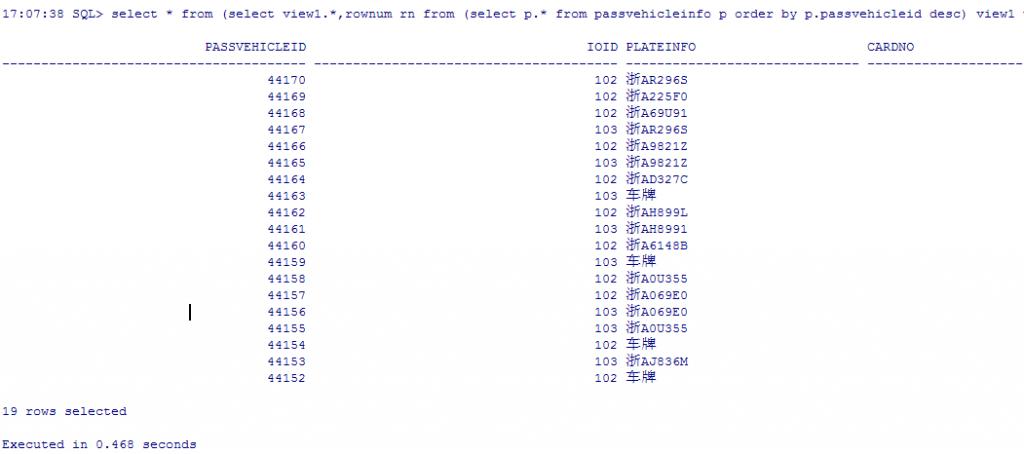
 3.按rownum来分
3.按rownum来分
17:07:38 SQL> select * from (select view1.*,rownum rn from (select p.* from passvehicleinfo p order by p.passvehicleid desc) view1 where rownum<10000) view2 where rn>9980;
 下面最主要介绍第三种:按rownum来分
下面最主要介绍第三种:按rownum来分
1. rownum 分页
SELECT * FROM emp;
2. 显示rownum[oracle分配的]
SELECT e.*, ROWNUM rn FROM (SELECT * FROM emp) e;
rn相当于Oracle分配的行的ID号
3.挑选出6—10条记录
先查出1-10条记录
SELECT e.*, ROWNUM rn FROM (SELECT * FROM emp) e WHERE ROWNUM <= 10;
如果后面加上rownum>=6是不行的,
4. 然后查出6-10条记录
SELECT * FROM (SELECT e.*, ROWNUM rn FROM (SELECT * FROM emp) e WHERE ROWNUM <= 10) WHERE rn >= 6;
5. 几个查询变化
a. 指定查询列,只需要修改最里层的子查询
只查询雇员的编号和工资
SELECT * FROM (SELECT e.*, ROWNUM rn FROM (SELECT ename, sal FROM emp)
e WHERE ROWNUM <= 10) WHERE rn >= 6;
b. 排序查询,只需要修改最里层的子查询
工资排序后查询6-10条数据
SELECT * FROM (SELECT e.*, ROWNUM rn FROM (SELECT ename, sal FROM emp ORDER
by sal) e WHERE ROWNUM <= 10) WHERE rn >= 6;
在显示记录条目时往往要用到分页,一种常用的办法是利用各种数据库自带的定位接口对原始查询语句进行改写,从而只取出特定范围的某些记录。不同的数据库,查询定位接口是不一样的,下面做一汇总:
|
数据库 |
分页查询语句 |
说明 |
|
MySql |
"QUERY_SQL limit ?,?" |
使用limit关键字,第一个"?"是起始行号, 第二个"?"是返回条目数 |
|
Oracle |
SELECT * FROM |
结合rownum关键字,利用嵌套三层select 语句实现。第一个"?"表示终止行号, 第二个"?"表示其实行号 |
|
Sql Server |
尚无通用语句 | 可使用top n来返回前n条记录或使用存储过程 |
|
DB2 |
假设查询语句:select t1.* from t1 order by t1.id; 分页语句可为: "select * from ( select rownumber() over (order by t1.id) as row_, t1.* from t1 order by t1.id) as temp_ where row_ between ?+1 and ?" |
返回两个"?"之间的记录 |
|
InterBase |
“QUERY_SQL row ? to ?” | 返回两个"?"之间的记录 |
| PostgreSQL | “QUERY_SQL limit ? offset ?” |
第一个"?"为起始行号,第二个"?"代表 返回记录数 |
SQL
Server
关于分页 SQL 的资料许多,有的使用存储过程,有的使用游标。本人不喜欢使用游标,我觉得它耗资、效率低;使用存储过程是个不错的选择,因为存储过程是颠末预编译的,执行效率高,也更灵活。先看看单条 SQL 语句的分页 SQL 吧。
方法1:
适用于 SQL Server 2000/2005
SELECT TOP 页大小 * FROM table1 WHERE id NOT IN ( SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id ) ORDER BY id
方法2:
适用于 SQL Server 2000/2005
SELECT TOP 页大小 * FROM table1 WHERE id > ( SELECT ISNULL(MAX(id),0) FROM ( SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY
id ) A ) ORDER BY id
方法3:
适用于 SQL Server 2005
SELECT TOP 页大小 * FROM ( SELECT ROW_NUMBER() OVER (ORDER BY id) AS RowNumber,* FROM table1 ) A WHERE RowNumber > 页大小*(页数-1)
说明,页大小:每页的行数;页数:第几页。使用时,请把“页大小”以及“页大小*(页数-1)”替换成数码。
MYSQL
SELECT * FROM TT LIMIT 1,20
SELECT * FROM TT LIMIT 21,30
/*
如果你是几千上万数据,就直接使用mysql自带的函数 limit的普通用法就ok了,如果是100万以上的数据,可能就要讲方法了,下面我们来做个百万级数据的分页查询语句.
mysql> select * from news where id>=(select id from news limit 490000,1) limit 10; //0.18 sec //很 明显,这 种方式胜出 .
mysql> select * from news limit 490000,10 //0.22 sec;
*/
以下的文章主要介绍的是MySQL分页的实际操作方案,其实关于实现MySQL分页的最简单的方法就是利用利用mysql数据库的LIMIT函数,LIMIT [offset,] rows可以从MySQL数据库表中第M条记录开始检索N条记录的语句为:
例如从表Sys_option(主键为sys_id)中从第10条记录开始检索20条记录,语句如下:
Oracle
Oracle的分页查询语句基本上可以按照这篇了,下一篇文章会通过例子来申述。下面简单讨论一下多表联合的情况。对最多见的等值表连接查询,CBO 一般可能会采用两种连接方式NESTED LOOP以及HASH JOIN(MERGE JOIN效率比HASH
JOIN效率低,一般CBO不会考虑)。在这里,由于使用了分页,因此指定了一个归回的最大记载数,NESTED LOOP在归回记载数跨越最大值时可以顿时遏制并将结果归回给中心层,而HASH JOIN必需处理完所有成集(MERGE JOIN也是)。那么在大部分的情况下,对分页查询选择NESTED LOOP作为查询的连接方法具有较高的效率(分页查询的时候绝大部分的情况是查询前几页的数据,越靠后面的页数访问概率越小)。
因此,如果不介意在体系中使用HINT的话,可以将分页的查询语句改写为:
SELECT /*+ FIRST_ROWS */ * FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM TABLE_NAME) A
WHERE ROWNUM <= 40
)
WHERE RN >= 21
oracle,mysql,SqlServer三种数据库的分页查询总结
标签:数据库分页查询 mysql分页查询 oracle分页查询 sqlserver分页查询
原文地址:http://blog.csdn.net/sh_king/article/details/47170633