标签:
XML 技术概述
XML是一种通用的数据交换格式。为实现计算机之间的文档交换而设计的文档内容编写规范,语法与HTML相似;XML的作用:统一信息的结构,实现不同系统之间的相互通信;目前许多系统的配置文件都使用XML格式;配置文件就是记录应用程序的配置信息的文件.
XML 文档结构
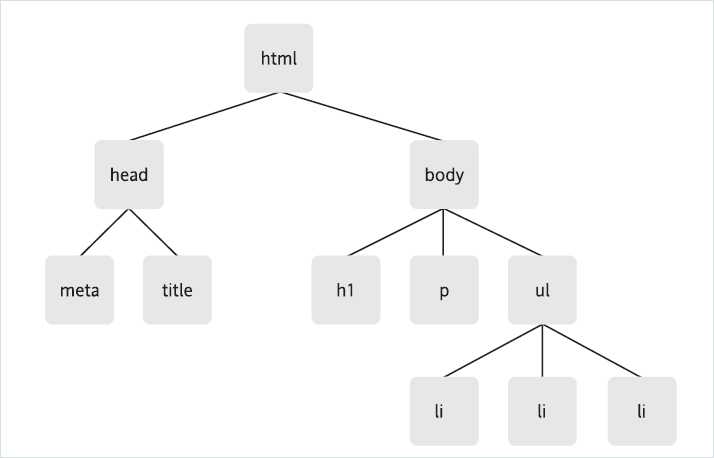
<?xml version="1.0" ?> //可通过在XML文档声明中指定encoding属性来说明该XML文档所使用的字符编码方式: <?xml version="1.0" encoding="GB2312" ?> //encoding属性默认的设置是Unicode编码,如果文档中的字符是以UTF-8或者是UTF-16作为编码,则可以不设置这个属性。
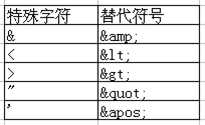
(1)<!DOCTYPE 文档类型名称 SYSTEM "DTD文件的URL">
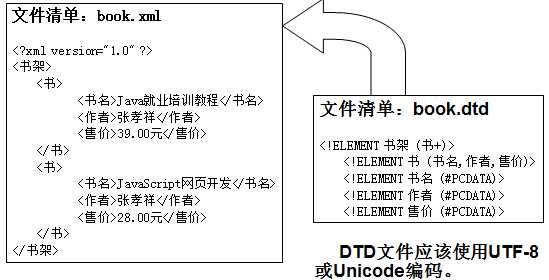
例如:<!DOCTYPE 书架 SYSTEM "book.dtd">
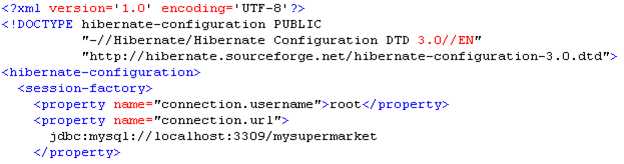
(2)<!DOCTYPE 文档类型名称 PUBLIC "DTD名称" "DTD文件的URL">
例如:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
//在XML文档中直接嵌入DTD定义语句: <?xml version="1.0" encoding="UTF-8" standalone="yes"?> <!DOCTYPE 根元素名 [ DTD定义语句 …… ]> //引入外部DTD文件的同时加入DTD定义语句: <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd" [ !ENTITY copyright SYSTEM "http://www.it315.org/copyright.xml" ]>
//在XML文档中直接嵌入DTD的例子 <?xml version="1.0" encoding="UTF-8" standalone="yes"?> <!DOCTYPE 书架 [ <!ELEMENT 书架 (书+)> <!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)> ]> <书架> <书> <书名>Java就业培训教程</书名> <作者>张孝祥</作者> <售价>39.00元</售价> </书> ... </书架>
DTD 的语法细节:
1)元素定义
<!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)>
2)属性定义
//XML 文档中可以为元素设置属性 //语法格式: <!ATTLIST 元素名 属性名1 属性类型 设置说明 属性名2 属性类型 设置说明 …… > //举例: <!ATTLIST 商品 类别 CDATA #REQUIRED 颜色 CDATA #IMPLIED > //应用: <商品 类别="服装" 颜色="黄色">…</商品> <商品 类别="服装">…</商品>

设置说明:1>#REQUIRED:必须设置该属性;2>#IMPLIED:可以设置也可以不设置;3>#FIXED:说明该属性的取值固定为一个默认值,在 XML 文件中不能为该属性设置其它值,但需要为该属性提供这个默认值(直接使用默认值:在 XML 中可以设置该值也可以不设置该属性值,若没设置则使用默认值)。
CDATA//表示属性值为普通文本字符串。 ENUMERATED //属性的类型可以是一组取值的列表,在 XML 文件中设置的属性值只能是这个列表中的某个值 <?xml version = "1.0" encoding="GB2312" standalone="yes"?> <!DOCTYPE 购物篮 [ <!ELEMENT 肉 EMPTY> <!ATTLIST 肉 品种 ( 鸡肉 | 牛肉 | 猪肉 | 鱼肉 ) "鸡肉"> ]> <购物篮> <肉 品种="鱼肉"/> <肉 品种="牛肉"/> <肉/> </购物篮> //表示属性的设置值将用于唯一标识一个 XML 文件中的某个元素,这种 ID 类型的属性通常由 XML 文件的解析处理程序或脚本语言使用;ID 属性的值只能由字母,数字或下划线开始,不能出现空白字符 ID <?xml version = "1.0" encoding="GB2312" standalone = "yes"?> <!DOCTYPE 联系人列表[ <!ELEMENT 联系人列表 ANY> <!ELEMENT 联系人(姓名,EMAIL)> <!ELEMENT 姓名(#PCDATA)> <!ELEMENT EMAIL(#PCDATA)> <!ATTLIST 联系人 编号 ID #REQUIRED> ]> <联系人列表> <联系人 编号="1"> <姓名>张三</姓名> <EMAIL>zhang@it315.org</EMAIL> </联系人> <联系人 编号="2"> <姓名>李四</姓名> <EMAIL>li@it315.org</EMAIL> </联系人> </联系人列表> IDREF和IDREFS NMTOKEN和NMTOKENS NOTATION ENTITY和ENTITYS
3)实体定义
实体的根本作用是为一段文本内容创建一个别名,以后在XML文档中就可以多次引用这个别名,XML解析器程序将把XML文档中出现的别名引用转变成其所对应的文本内容。在DTD定义中,一条<!ENTITY …>语句用于定义一个实体。实体可分为两种类型:引用实体和参数实体。
//引用实体主要在 XML 文档中被应用 //语法格式: <!ENTITY 实体名称 “实体内容” >:直接转变成实体内容 <!ENTITY 实体名称 SYSTEM “外部XML文档的URL” >:被替换成外部 XML 文档中的内容 引用方式: &实体名称; 举例: <!ENTITY copyright “I am a programmer"> …… ©right; //参数实体被 DTD 文件自身使用 //语法格式: <!ENTITY % 实体名称 "实体内容" > 引用方式: %实体名称; 举例1: <!ENTITY % TAG_NAMES "姓名 | EMAIL | 电话 | 地址"> <!ELEMENT 个人信息 (%TAG_NAMES; | 生日)> <!ELEMENT 客户信息 (%TAG_NAMES; | 公司名)> 举例2: <!ENTITY % common.attributes ‘id ID #IMPLIED account CDATA #REQUIRED‘ > ... <!ATTLIST purchaseOrder %common.attributes;> <!ATTLIST item %common.attributes;>

文件清单:xmlbook.xsd <?xml version="1.0" encoding="UTF-8" ?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name=‘书架‘ > <xs:complexType> <xs:sequence maxOccurs=‘unbounded‘ > <xs:element name=‘书‘ > <xs:complexType> <xs:sequence> <xs:element name=‘书名‘ type=‘xs:string‘ /> <xs:element name=‘作者‘ type=‘xs:string‘ /> <xs:element name=‘售价‘ type=‘xs:string‘ /> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
文件清单:xmlbook.xml <?xml version="1.0" encoding="UTF-8"?> <书架 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="xmlbook.xsd"> <书> <书名>JavaScript网页开发</书名> <作者>张孝祥</作者> <售价>28.00元</售价> </书> </书架>
名称空间
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name=‘书架‘> ...
基本格式: xmlns:前缀名称="URI" 举例: < it315:书架 xmlns:it315="http://www.it315.org/xmlbook/schema"> <it315:书> <it315:书名>JavaScript网页开发</it315:书名> <it315:作者>张孝祥</it315:作者> <it315:售价>28.00元</it315:售价> </it315:书> <书架> 在任何元素中声明的名称空间,只对该元素及其中嵌套的所有子孙元素有效,声明名称空间的元素自身上也可以使用代表该名称空间的前缀。 QName(Qualified Name,限定名)是指用冒号(:)把前缀与本地部分进行分隔的名称,即被限定在了某个名称空间中的名称。
默认名称空间 基本格式: xmlns="URI" 举例: <书架 xmlns="http://www.it315.org/xmlbook/schema"> <书> <书名>JavaScript网页开发</书名> <作者>张孝祥</作者> <售价>28.00元</售价> </书> <书架>
属性的名称空间问题
XML实例文档中通常只需要将元素限定于该模式文档的名称空间中,而不需要将该元素的属性限定于名称空间中。
例子:
<xi:include xmlns:xi="http://www.w3.org/2001/XInclude" href="http://example.com/std/defs" parse="xml" />
例子:
<x xmlns="http://www.w3.org" xmlns:n1="http://www.w3.org"> <good a="1" n1:a="2" /> </x>
xml:space和xml:lang属性
例子:
<网址 xml:space="preserve"> www.it315.org </网址>
xml:lang属性用于设置元素的本地化语言信息,ISO-639规范中规定了代表各个国家和地区的本地化语言的名称,例如“en” 表示英文、“la”表示拉丁文、“zh”表示中文、“zh-CN” 表示中文(中国)、“zh-TW” 表示中文(台湾地区)。
例子:
<product xml:lang="zh-CN" release-date="2002-08-18"/> <product xml:lang=“en-US" release-date=" 8/18/2002"/>
在某个元素中设置了xml:space和xml:lang属性,嵌套在该元素中的子孙元素都将沿袭其设置结果。
使用名称空间引入XML Schema文档
文件清单:xmlbook.xml <?xml version="1.0" encoding="UTF-8"?> <书架 xmlns="http://www.it315.org/xmlbook/schema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.it315.org/xmlbook/schema http://www.it315.org/xmlbook.xsd" > <书> <书名>JavaScript网页开发</书名> <作者>张孝祥</作者> <售价>28.00元</售价> </书> </书架>
schemaLocation属性的设置值中包含有两个部分,第一个部分就是名称空间的URI,第二个部分就是该名称空间所标识的XML Schema文件的位置或URL地址,这两个部分之间用空格分隔。
文件清单:xmlbook.xml <?xml version="1.0" encoding="UTF-8"?> <书架 xmlns="http://www.it315.org/xmlbook/schema" xmlns:demo="http://www.it315.org/demo/schema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.it315.org/xmlbook/schema http://www.it315.org/xmlbook.xsd http://www.it315.org/demo/schema http://www.it315.org/demo.xsd"> <书> <书名>JavaScript网页开发</书名> <作者>张孝祥</作者> <售价 demo:币种=”人民币”>28.00元</售价> </书> </书架>
不使用名称空间引入XML Schema文档
文件清单:xmlbook.xml <?xml version="1.0" encoding="UTF-8"?> <书架 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="xmlbook.xsd"> <书> <书名>JavaScript网页开发</书名> <作者>张孝祥</作者> <售价>28.00元</售价> </书> </书架>
DOM4J 解析 XML 文档
//1.读取XML文件,获得document对象. SAXReader reader = new SAXReader(); Document document = reader.read(new File("input.xml")); //2.解析XML形式的文本,得到document对象. String text = "<members></members>"; Document document = DocumentHelper.parseText(text); //3.主动创建document对象. Document document = DocumentHelper.createDocument(); //创建根节点 Element root = document.addElement("members");
节点相关
//1.获取文档的根节点. Element rootElm = document.getRootElement(); //2.取得某节点的单个子节点. //"member"是节点名 Element memberElm=root.element("member"); //3.取得节点的文字 String text=memberElm.getText(); //也可以: //这个是取得根节点下的name字节点的文字. String text=root.elementText("name"); //4.取得某节点下名为"member"的所有字节点并进行遍历. List nodes = rootElm.elements("member"); for (Iterator it = nodes.iterator(); it.hasNext();) { Element elm = (Element) it.next(); // do something } //5.对某节点下的所有子节点进行遍历. for(Iterator it=root.elementIterator();it.hasNext();){ Element element = (Element) it.next(); // do something } //6.在某节点下添加子节点. Element ageElm = newMemberElm.addElement("age"); //7.设置节点文字. ageElm.setText("29"); //8.删除某节点. //childElm是待删除的节点,parentElm是其父节点 parentElm.remove(childElm); //9.添加一个CDATA节点. Element contentElm = infoElm.addElement("content"); contentElm.addCDATA(diary.getContent());
属性相关
//1.取得某节点下的某属性 Element root=document.getRootElement(); //属性名name Attribute attribute=root.attribute("size"); //2.取得属性的文字 String text=attribute.getText(); //这个是取得根节点下name字节点的属性firstname的值. String text2 =root.element("name").attributeValue("firstname"); //3.遍历某节点的所有属性 Element root=document.getRootElement(); for(Iterator it=root.attributeIterator();it.hasNext();){ Attribute attribute = (Attribute) it.next(); String text=attribute.getText(); System.out.println(text); } //4.设置某节点的属性和文字. newMemberElm.addAttribute("name", "sitinspring"); //5.设置属性的文字 Attribute attribute=root.attribute("name"); attribute.setText("sitinspring"); //6.删除某属性 //属性名name Attribute attribute=root.attribute("size"); root.remove(attribute);
将文档写入XML文件
//1.文档中全为英文,不设置编码,直接写入的形式. XMLWriter writer = new XMLWriter(new FileWriter("output.xml")); writer.write(document); writer.close(); //2.文档中含有中文,设置编码格式写入的形式. OutputFormat format = OutputFormat.createPrettyPrint(); // 指定XML编码 format.setEncoding("GBK"); XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format); writer.write(document); writer.close();
字符串与XML的转换
//1.将字符串转化为XML String text = "<members> <member>sitinspring</member></members>"; Document document = DocumentHelper.parseText(text); //2.将文档或节点的XML转化为字符串. SAXReader reader = new SAXReader(); Document document = reader.read(new File("input.xml")); Element root=document.getRootElement(); String docXmlText=document.asXML(); String rootXmlText=root.asXML(); Element memberElm=root.element("member"); String memberXmlText=memberElm.asXML();
标签:
原文地址:http://www.cnblogs.com/Vae1990Silence/p/4696788.html