标签:
最新在公司做一个项目,需要一些文章类的数据,当时就想到了用网络爬虫去一些技术性的网站爬一些,当然我经常去的就是博客园,于是就有下面的这篇文章。
我需要把我从博客园爬取的数据,保存起来,最好的方式当然是保存到数据库中去了,好了我们先建一个数据库,在来一张表,保存我们的数据,其实都很简单的了啊,如下图所示
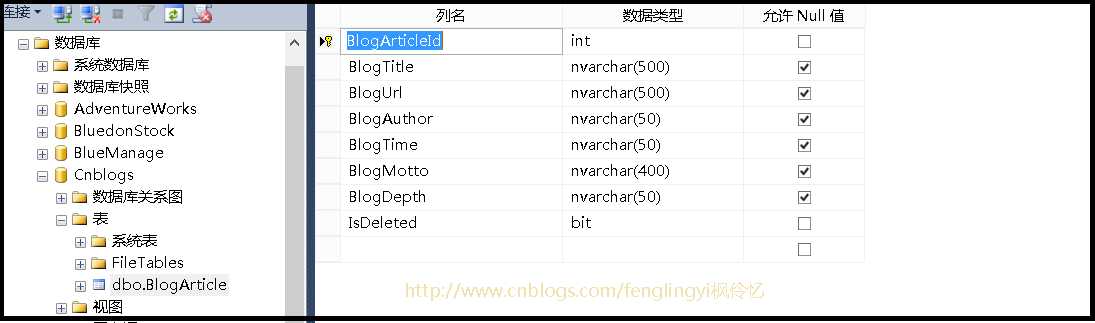
BlogArticleId博文自增ID,BlogTitle博文标题,BlogUrl博文地址,BlogAuthor博文作者,BlogTime博文发布时间,BlogMotto作者座右铭,BlogDepth蜘蛛爬虫爬取的深度,IsDeleted是否删除。
数据库表也创建好了,我们先来一个数据库的帮助类。

/// <summary>
/// 数据库帮助类
/// </summary>
public class MssqlHelper
{
#region 字段属性
/// <summary>
/// 数据库连接字符串
/// </summary>
private static string conn = "Data Source=.;Initial Catalog=Cnblogs;User ID=sa;Password=123";
#endregion
#region DataTable写入数据
public static void GetData(string title, string url, string author, string time, string motto, string depth, DataTable dt)
{
DataRow dr;
dr = dt.NewRow();
dr["BlogTitle"] = title;
dr["BlogUrl"] = url;
dr["BlogAuthor"] = author;
dr["BlogTime"] = time;
dr["BlogMotto"] = motto;
dr["BlogDepth"] = depth;
//2.0 将dr追加到dt中
dt.Rows.Add(dr);
}
#endregion
#region 插入数据到数据库
/// <summary>
/// 插入数据到数据库
/// </summary>
public static void InsertDb(DataTable dt)
{
try
{
using (System.Data.SqlClient.SqlBulkCopy copy = new System.Data.SqlClient.SqlBulkCopy(conn))
{
//3.0.1 指定数据插入目标表名称
copy.DestinationTableName = "BlogArticle";
//3.0.2 告诉SqlBulkCopy对象 内存表中的 OrderNO1和Userid1插入到OrderInfos表中的哪些列中
copy.ColumnMappings.Add("BlogTitle", "BlogTitle");
copy.ColumnMappings.Add("BlogUrl", "BlogUrl");
copy.ColumnMappings.Add("BlogAuthor", "BlogAuthor");
copy.ColumnMappings.Add("BlogTime", "BlogTime");
copy.ColumnMappings.Add("BlogMotto", "BlogMotto");
copy.ColumnMappings.Add("BlogDepth", "BlogDepth");
//3.0.3 将内存表dt中的数据一次性批量插入到OrderInfos表中
copy.WriteToServer(dt);
dt.Rows.Clear();
}
}
catch (Exception)
{
dt.Rows.Clear();
}
}
#endregion
}
来个日志,方便我们查看,代码如下。
/// <summary>
/// 日志帮助类
/// </summary>
public class LogHelper
{
#region 写入日志
//写入日志
public static void WriteLog(string text)
{
//StreamWriter sw = new StreamWriter(AppDomain.CurrentDomain.BaseDirectory + "\\log.txt", true);
StreamWriter sw = new StreamWriter("F:" + "\\log.txt", true);
sw.WriteLine(text);
sw.Close();//写入
}
#endregion
}
我的网络蜘蛛爬虫,用的一个第三方类库,代码如下。
 AddUrlEventArgs.cs BloomFilter.cs CrawlErrorEventArgs.cs CrawlExtension.cs CrawlMaster.cs CrawlSettings.cs CrawlStatus.cs DataReceivedEventArgs.cs SecurityQueue.cs UrlInfo.cs UrlQueue.cs
AddUrlEventArgs.cs BloomFilter.cs CrawlErrorEventArgs.cs CrawlExtension.cs CrawlMaster.cs CrawlSettings.cs CrawlStatus.cs DataReceivedEventArgs.cs SecurityQueue.cs UrlInfo.cs UrlQueue.cs这些工作都准备完成后,终于要来我们的重点了,我们都知道控制台程序非常不稳定,而我们的这个从博客园上面爬取文章的这个事情需要长期的进行下去,这个需要 很稳定的进行下去,所以我想起了windows服务,创建好我们的windows服务,代码如下。
using Feng.SimpleCrawler;
using Feng.DbHelper;
using Feng.Log;
using HtmlAgilityPack;
namespace Feng.Demo
{
/// <summary>
/// windows服务
/// </summary>
partial class FengCnblogsService : ServiceBase
{
#region 构造函数
/// <summary>
/// 构造函数
/// </summary>
public FengCnblogsService()
{
InitializeComponent();
}
#endregion
#region 字段属性
/// <summary>
/// 蜘蛛爬虫的设置
/// </summary>
private static readonly CrawlSettings Settings = new CrawlSettings();
/// <summary>
/// 临时内存表存储数据
/// </summary>
private static DataTable dt = new DataTable();
/// <summary>
/// 关于 Filter URL:http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
/// </summary>
private static BloomFilter<string> filter;
#endregion
#region 启动服务
/// <summary>
/// TODO: 在此处添加代码以启动服务。
/// </summary>
/// <param name="args"></param>
protected override void OnStart(string[] args)
{
ProcessStart();
}
#endregion
#region 停止服务
/// <summary>
/// TODO: 在此处添加代码以执行停止服务所需的关闭操作。
/// </summary>
protected override void OnStop()
{
}
#endregion
#region 程序开始处理
/// <summary>
/// 程序开始处理
/// </summary>
private void ProcessStart()
{
dt.Columns.Add("BlogTitle", typeof(string));
dt.Columns.Add("BlogUrl", typeof(string));
dt.Columns.Add("BlogAuthor", typeof(string));
dt.Columns.Add("BlogTime", typeof(string));
dt.Columns.Add("BlogMotto", typeof(string));
dt.Columns.Add("BlogDepth", typeof(string));
filter = new BloomFilter<string>(200000);
const string CityName = "";
#region 设置种子地址
// 设置种子地址
Settings.SeedsAddress.Add(string.Format("http://www.cnblogs.com/{0}", CityName));
Settings.SeedsAddress.Add("http://www.cnblogs.com/artech");
Settings.SeedsAddress.Add("http://www.cnblogs.com/wuhuacong/");
Settings.SeedsAddress.Add("http://www.cnblogs.com/dudu/");
Settings.SeedsAddress.Add("http://www.cnblogs.com/guomingfeng/");
Settings.SeedsAddress.Add("http://www.cnblogs.com/daxnet/");
Settings.SeedsAddress.Add("http://www.cnblogs.com/fenglingyi");
Settings.SeedsAddress.Add("http://www.cnblogs.com/ahthw/");
Settings.SeedsAddress.Add("http://www.cnblogs.com/wangweimutou/");
#endregion
#region 设置 URL 关键字
Settings.HrefKeywords.Add("a/");
Settings.HrefKeywords.Add("b/");
Settings.HrefKeywords.Add("c/");
Settings.HrefKeywords.Add("d/");
Settings.HrefKeywords.Add("e/");
Settings.HrefKeywords.Add("f/");
Settings.HrefKeywords.Add("g/");
Settings.HrefKeywords.Add("h/");
Settings.HrefKeywords.Add("i/");
Settings.HrefKeywords.Add("j/");
Settings.HrefKeywords.Add("k/");
Settings.HrefKeywords.Add("l/");
Settings.HrefKeywords.Add("m/");
Settings.HrefKeywords.Add("n/");
Settings.HrefKeywords.Add("o/");
Settings.HrefKeywords.Add("p/");
Settings.HrefKeywords.Add("q/");
Settings.HrefKeywords.Add("r/");
Settings.HrefKeywords.Add("s/");
Settings.HrefKeywords.Add("t/");
Settings.HrefKeywords.Add("u/");
Settings.HrefKeywords.Add("v/");
Settings.HrefKeywords.Add("w/");
Settings.HrefKeywords.Add("x/");
Settings.HrefKeywords.Add("y/");
Settings.HrefKeywords.Add("z/");
#endregion
// 设置爬取线程个数
Settings.ThreadCount = 1;
// 设置爬取深度
Settings.Depth = 55;
// 设置爬取时忽略的 Link,通过后缀名的方式,可以添加多个
Settings.EscapeLinks.Add("http://www.oschina.net/");
// 设置自动限速,1~5 秒随机间隔的自动限速
Settings.AutoSpeedLimit = false;
// 设置都是锁定域名,去除二级域名后,判断域名是否相等,相等则认为是同一个站点
Settings.LockHost = false;
Settings.RegularFilterExpressions.Add(@"http://([w]{3}.)+[cnblogs]+.com/");
var master = new CrawlMaster(Settings);
master.AddUrlEvent += MasterAddUrlEvent;
master.DataReceivedEvent += MasterDataReceivedEvent;
master.Crawl();
}
#endregion
#region 打印Url
/// <summary>
/// The master add url event.
/// </summary>
/// <param name="args">
/// The args.
/// </param>
/// <returns>
/// The <see cref="bool"/>.
/// </returns>
private static bool MasterAddUrlEvent(AddUrlEventArgs args)
{
if (!filter.Contains(args.Url))
{
filter.Add(args.Url);
Console.WriteLine(args.Url);
if (dt.Rows.Count > 200)
{
MssqlHelper.InsertDb(dt);
dt.Rows.Clear();
}
return true;
}
return false; // 返回 false 代表:不添加到队列中
}
#endregion
#region 解析HTML
/// <summary>
/// The master data received event.
/// </summary>
/// <param name="args">
/// The args.
/// </param>
private static void MasterDataReceivedEvent(SimpleCrawler.DataReceivedEventArgs args)
{
// 在此处解析页面,可以用类似于 HtmlAgilityPack(页面解析组件)的东东、也可以用正则表达式、还可以自己进行字符串分析
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(args.Html);
HtmlNode node = doc.DocumentNode.SelectSingleNode("//title");
string title = node.InnerText;
HtmlNode node2 = doc.DocumentNode.SelectSingleNode("//*[@id=‘post-date‘]");
string time = node2.InnerText;
HtmlNode node3 = doc.DocumentNode.SelectSingleNode("//*[@id=‘topics‘]/div/div[3]/a[1]");
string author = node3.InnerText;
HtmlNode node6 = doc.DocumentNode.SelectSingleNode("//*[@id=‘blogTitle‘]/h2");
string motto = node6.InnerText;
MssqlHelper.GetData(title, args.Url, author, time, motto, args.Depth.ToString(), dt);
LogHelper.WriteLog(title);
LogHelper.WriteLog(args.Url);
LogHelper.WriteLog(author);
LogHelper.WriteLog(time);
LogHelper.WriteLog(motto == "" ? "null" : motto);
LogHelper.WriteLog(args.Depth + "&dt.Rows.Count=" + dt.Rows.Count);
//每次超过100条数据就存入数据库,可以根据自己的情况设置数量
if (dt.Rows.Count > 100)
{
MssqlHelper.InsertDb(dt);
dt.Rows.Clear();
}
}
#endregion
}
}
这里我们用爬虫从博客园爬取来了博文,我们需要用这个HtmlAgilityPack第三方工具来解析出我们需要的字段,博文标题,博文作者,博文URL,等等一些信息。同时我们可以设置服务的一些信息
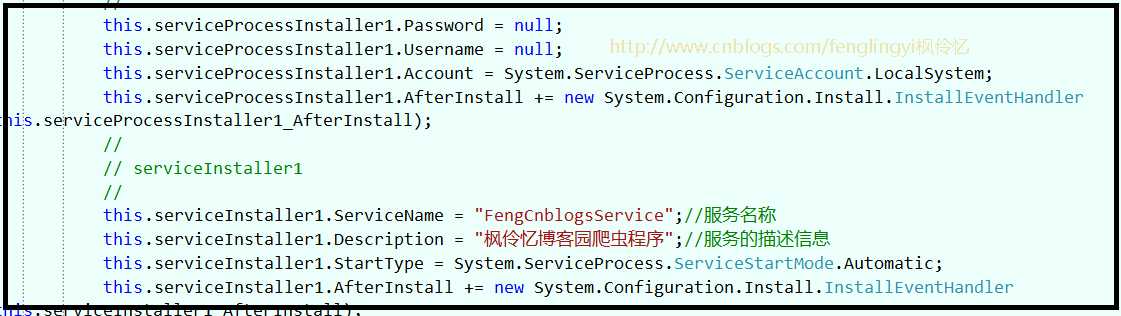
在网络爬虫中,我们要设置一些参数,设置种子地址,URL关键字,还有爬取的深度等等,这些工作都完成后,我们就只需要安装我们的windows服务,就大功告成了。嘿嘿...
在这里我们采用vs自带的工具来安装windows服务。
安装成功后,打开我们的windows服务就可以看到我们安装的windows服务。
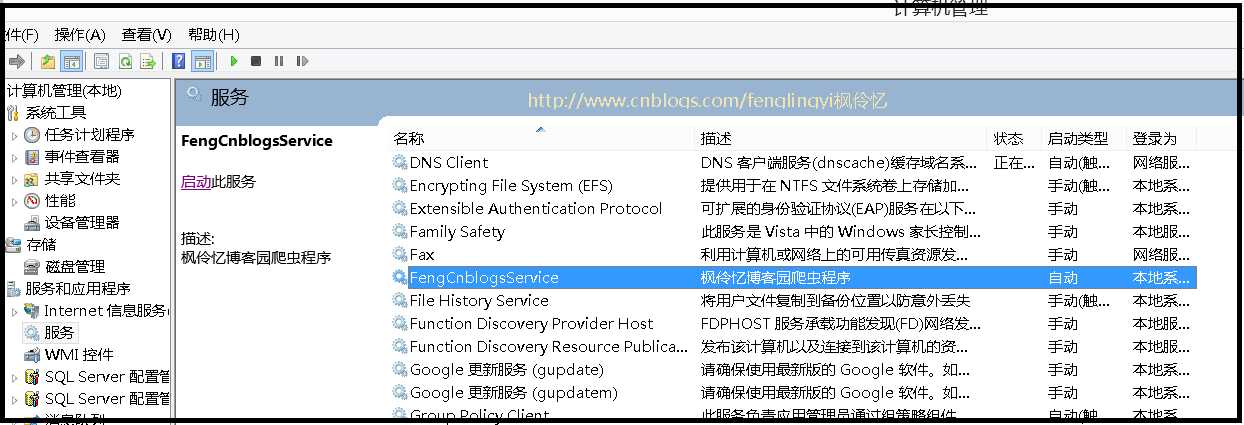
同时可以查看我们的日志文件,查看我们爬取的博文解析出来的信息。如下图所示。

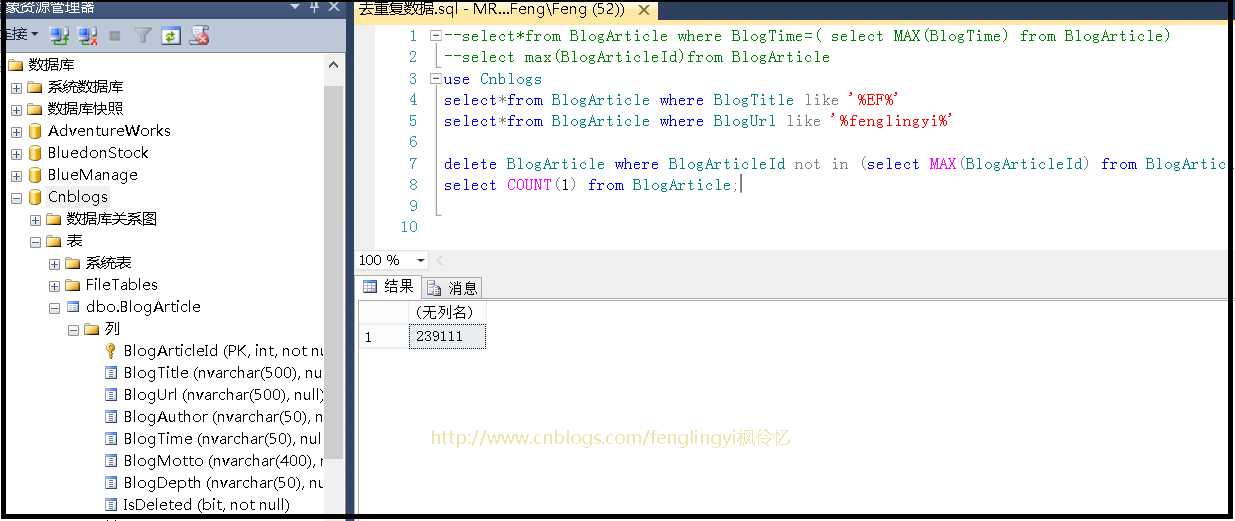
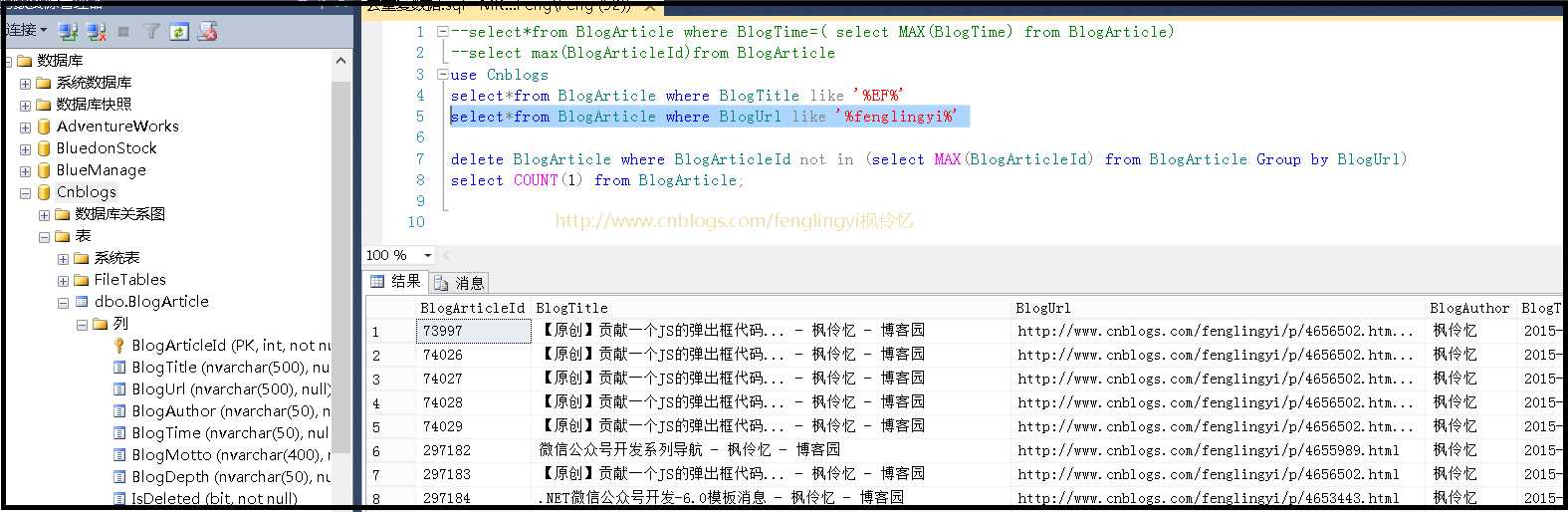
这个时候去查看我们的数据库,我的这个服务已经运行了一天。。。
转载:http://www.cnblogs.com/fenglingyi/p/4708006.html
网络爬虫+HtmlAgilityPack+windows服务从博客园爬取20万博文
标签:
原文地址:http://www.cnblogs.com/armyfai/p/4709714.html