虽然用到过很多次流操作,但是对流的理解仍然不到位,以前用C++写过一个SocketStream,利用指针和内存拷贝的方法实现不同数据类型和多种数据结构的网络传输,但这只是个简单是使用,JAVA中有很多流,目前仍不是很了解,这里总结一下C++的流,然后对JAVA流做一点了解。基本概念都是拷贝过来的,一些个人理解若不正确,请指正。
1、C++流
在程序设计中,数据输入/输出(I/O)操作是必不可少的,C++语言的数据输入/输出操作是通过I/O流库来实现的。C++中把数据之间的传输操作称为流,流既可以表示数据从内存传送到某个载体或设备中,即输出流,也可以表示数据从某个载体或设备传送到内存缓冲区变量中,即输入流。
C++流涉及以下概念:
STL中定义的流类:
| 流类分类 | 流类名称 | 流 类 作 用 |
| 流基类 | ios | 所有流类的父类,保存流的状态并处理错误 |
| 输入流类 | istream | 输入流基类,将流缓冲区中的数据作格式化和非格式化之间的转换并输入 |
| ifstream | 文件输入流类 | |
| istream_withassign | cin输入流类,即操作符>>输入流 | |
| istrstream | 串输入流类, 基于C类型字符串char*编写 | |
| istringstream | 串输入流类, 基于std::string编写 | |
| 输出流类 | ostream | 输出流基类,将流缓冲区中的数据作格式化和非格式化之间的转换。并输出 |
| ofstream | 文件输出流类 | |
| ostream_withassign | Cout、cerr、clog的输出流类,即操作符<<输出流 | |
| ostrstream | 串输入流类, 基于C类型字符串char*编写 | |
| ostringstream | 串输入流类, 基于std::string编写 | |
| 输入/输出流类 | iostream | 多目的输入/输出流类的基类 |
| fstream | 文件流输入/输出类 | |
| strstream | 串流输入/输出类, 基于C类型字符串char*编写 | |
| stringstream | 串流输入/输出类, 基于std::string编写 |
C++这些流的原理大概都是这样的:把流看出一个类,类中定义了一个指针指向一块动态增长的内存区域,并定义了一系列数据类型和数据结构的写入方法,最后重载运算符。
2、JAVA流
java.io包中包含了流式I/O所需要的所有类。在java.io包中有四个基本类:InputStream、OutputStream及Reader、Writer类,它们分别处理字节流和字符流:
基本数据流的I/O
|
输入/输出 |
字节流 |
字符流 |
|
输入流 |
Inputstream |
Reader |
|
输出流 |
OutputStream |
Writer |
Java中其他多种多样变化的流均是由它们派生出来的:
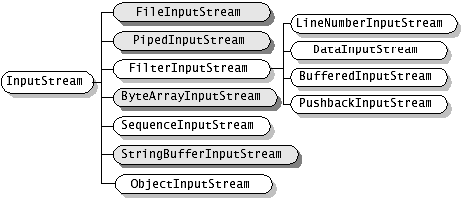
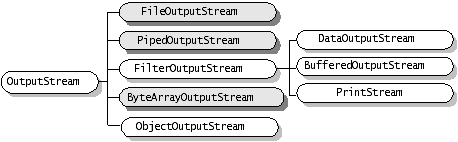
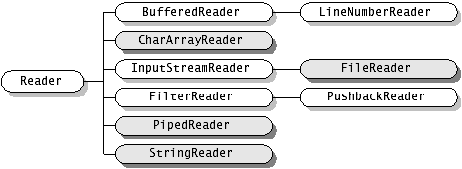
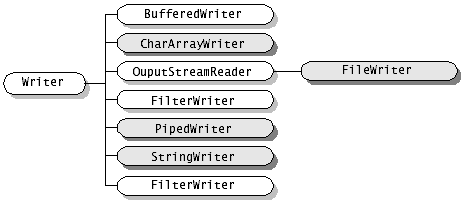
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点
所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 2. 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以
字节流是最基本的,所有的InputStrem和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的 但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化 这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联 在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的
下面分析几种常用的字节流:
其中FileInputStream和FileOutputStream是对文件读写的字节流,理解起来较为容易略过。
StringBufferInputStream:把一个String对象作为InputStream
SequenceInputStream:把多个InputStream合并为一个InputStream;
SequenceOutputStream:把多个OutStream合并为一个OutStream
这些流遇到的情况相对较少,主要介绍以下几种流。
管道流,PipedInputStream和PipedOutputStream,转载http://www.cnblogs.com/meng72ndsc/archive/2010/12/23/1915358.html的文章,感觉一下子就理解了。内容如下:
管道流,用于线程间的通信。一个线程的PipedInputStream对象从另外一个线程的PipedOutputStream对象读取输入。要使管道流有用,必须同时构造管道输入流和管道输出流。示列代码采用生产者-消费者模式模拟两个线程直接的通信。
生产者:
import java.io.IOException;
import java.io.PipedOutputStream;
public class Producer extends Thread {
private PipedOutputStream pos;
public Producer(PipedOutputStream pos) {
this.pos = pos;
}
@Override
public void run() {
super.run();
try {
pos.write("Hello".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
}消费者:
import java.io.IOException;
import java.io.PipedInputStream;
public class Consumer extends Thread {
private PipedInputStream pis;
public Consumer(PipedInputStream pis) {
this.pis = pis;
}
@Override
public void run() {
super.run();
byte[] b = new byte[100]; // 将数据保存在byte数组中
try {
int len = pis.read(b); // 从数组中得到实际大小。
System.out.println(new String(b, 0, len));
pis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}测试代码:
PipedStreamTest
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
public class PipedStreamTest {
public static void main(String[] args) {
PipedOutputStream pos = new PipedOutputStream();
PipedInputStream pis = new PipedInputStream();
try {
pos.connect(pis);// 连接管道
new Producer(pos).start();// 启动线程
new Consumer(pis).start();// 启动线程
} catch (IOException e) {
e.printStackTrace();
}
}
}ByteArrayOutputStream和ByteArrayInputStream向数组中写入或读出byte型数据,实现数据的缓冲。在网络传输中我们往往要传输很多变量,我们可以利用ByteArrayOutputStream把所有的变量收集到一起,然后一次性把数据发送出去。
参考:http://blog.csdn.net/yaoxin871101/article/details/7548112
● ByteArrayInputStream
ByteArrayInputStream 包含一个内部缓冲区,该缓冲区包含从流中读取的字节。内部计数器跟踪 read 方法要提供的下一个字节。关闭ByteArrayInputStream 无效。此类中的方法在关闭此流后仍可被调用,而不会产生任何IOException。
● ByteArrayOutputStream
此类实现了一个输出流,其中的数据被写入一个 byte 数组。缓冲区会随着数据的不断写入而自动增长。可使用toByteArray() 和toString() 获取数据。关闭 ByteArrayOutputStream 无效。此类中的方法在关闭此流后仍可被调用,而不会产生任何IOException。
/*
用于操作字节数组的流对象。
ByteArrayInputStream :在构造的时候,需要接收数据源,。而且数据源是一个字节数组。
ByteArrayOutputStream:在构造的时候,不用定义数据目的,因为该对象中已经内部封装了可变长度的字节数组。
这就是数据目的地。
因为这两个流对象都操作的数组,并没有使用系统资源。
所以,不用进行close关闭。
在流操作规律讲解时:
源设备,
键盘 System.in,硬盘 FileStream,内存 ArrayStream。
目的设备:
控制台 System.out,硬盘FileStream,内存 ArrayStream。
用流的读写思想来操作数据。
*/
class ByteArrayStream {
public static void main(String[] args) {
// 数据源
ByteArrayInputStream bis = new ByteArrayInputStream("ABCDEFD".getBytes());
// 数据目的 代表内存
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int by = 0;
while ((by = bis.read()) != -1) {
bos.write(by);
}
System.out.println(bos.size());
System.out.println(bos.toString());
// bos.writeTo(new FileOutputStream("a.txt"));
}
}DataInputStream和DataOutputStream这也是比较重要的一对Filter实现。那么说起功能,实际上就不得不提到他们除了extends FilterInputStream/FilterOutputStream外,还额外实现了DataInput和DataOutput接口。
我们可以先来看下DataInput和DataOutput这两个interface。

DataInput接口的outline
再看DataOutput:

DataOutput接口的outline
而DataInputStream/DataOutputStream这一对实际上所做的也就是这两个接口所定义的方法。再DataInputStream/DataOutputStream中,这些方法做了拼接和拆分字节的工作。通过这些方法,我们可以方便的读取、写出各种我们实际所面对的类型的数据,而不必具体去在字节层面上做细节操作。
BufferedInputStream和BufferedOutputStream
先说说这个最简单的一对,BufferedInputStream和BufferedOutputStream。顾名思义,Buffered就是缓冲了的。在BufferedInputStream和BufferedOutputStream中,都额外实现了byte数组做buffer。
我们知道在父类FilterInputStream和FilterOutputStream类中,已经在构造方法时封装了原始的InputStream或者OutputStream对象。
在我们使用BufferedInputStream和BufferedOutputStream来进行read()和write()调用的时候,并不一定直接对封装的InputStream或者OutputStream对象进行操作,而是要经过缓冲处理。
在BufferedInputStream的read()中,实际上是一次读取了多个字节到缓冲数组,而非一次只读取一个。后续的read()操作可以直接从数组中获取字节,而不必再次调用封装的InputStream对象的read()操作。这样做其实在一定情况下可以减少底层的read调用次数,降低成本开销,提高了效率。
在BufferedOutputStream中也是一样,它的write()会先把数据写到缓冲数组中,直到数据达到了某个特定的限额,再调用write()的时候回真正调用到封装的OutputStream对象的write()方法。
ByteArrayOutputStream和BufferedOutputStream的适用范围
二者的共同点是:都是为了缓存数据的输出,提高数据输出的效率;
而二者的区别是:ByteArrayOutputStream是将数据全部缓存到自身,然后一次性输出;而BufferedOutputStream是缓存一部分后,一次一次的输出。
BufferedOutputStream会首先创建一个默认的容器量, capacity = 8192 = 8KB, 每次在写的时候都会去比对capacity是否还够用, 如果不够用的时候, 就flushBuffer(), 把buf中的数据写入对应的outputStream中, 然后将buf清空, 一直这样等到把内容写完. 在这过程中主要起到了一个数据缓冲的功能.
ByteArrayOutputStream也会首先创建一个默认的容器量, capacity = 32 = 32b, 每次在写的时候都会去比对capacity是否还够用, 如果不够用的时候, 就重新创建buf的容量, 一直等到内容写完, 这些数据都会一直处于内存中.
当你资源不足够用时,选择BufferedOutputStream是最佳的选择, 当你选择快速完成一个作业时,可以选择ByteArrayOutputStream之类的输出流。
下面是一些常用的字符流:
FileReader :与FileInputStream对应
主要用来读取字符文件,使用缺省的字符编码,有三种构造函数:
CharArrayReader:与ByteArrayInputStream对应
StringReader : 与StringBufferInputStream对应
InputStreamReader
从输入流读取字节,在将它们转换成字符:Public inputstreamReader(inputstream is);
FilterReader: 允许过滤字符流
protected filterReader(Reader r);
BufferReader :接受Reader对象作为参数,并对其添加字符缓冲器,使用readline()方法可以读取一行。
Public BufferReader(Reader r);
FileWrite: 与FileOutputStream对应
将字符类型数据写入文件,使用缺省字符编码和缓冲器大小。 、
chararrayWrite:与ByteArrayOutputStream对应 ,将字符缓冲器用作输出。
PrintWrite:生成格式化输出
filterWriter:用于写入过滤字符流
PipedWriter:与PipedOutputStream对应
StringWriter:无与之对应的以字节为导向的stream
版权声明:本文为博主原创文章,未经博主允许不得转载。
原文地址:http://blog.csdn.net/feiyangtianyao/article/details/47321469