标签:
一、背景介绍
皮肤检测在人脸识别与跟踪、手势识别、图像检索与分类等诸多计算机应用领域都有着广泛的应用。上述研究课题都必须解决一个基础问题,那就是将图像精确的划分为皮肤和背景两种区域,划分的精确与否直接影响着后续工作的精度与性能,因此皮肤检测已经逐渐成为以上任务的先行步骤和技术基础。
皮肤检测的相关算法有很多,典型的包括:直方图统计方法、高斯混合模型方法、基于颜色的皮肤检测、基于纹理的皮肤检测、基于多特征的皮肤检测、基于小波变换的皮肤检测、基于差分的皮肤检测以及诸如使用空间扩散法等。其中M.J.Jones和J.M.Rehg提出的基于皮肤像素颜色的直方图统计模型方法[1]具有良好的检测性能,也是我在本次实验中所采用的算法。
本次实验所采用的训练数据包括约一亿六千万个像素点,均从互联网上采集而得。利用这些数据,我构建了一个颜色直方图统计模型,用以区分皮肤像素和非皮肤像素。最终的实验结果表明了该方法的有效性。
二、直方图模型的构建
颜色空间的选取是皮肤检测的重要环节,但不同颜色空间在皮肤检测中的性能的比较都是在特定皮肤分布模型下进行的,普遍意义上的最优空间并不存在。对于皮肤色和非皮肤色的区分而言,RGB是最优空间,也为本次实验所采用。
除了颜色空间,直方图模型大小的选择同样值得考虑。如果像素采用的是24位三维色彩值,则R、G、B每一分量值都对应二进制的8位,在构建的RGB直方图模型中每一维就要被分划为2^8=256个单位值,则直方图模型将一共有256^3个柄数。这样的大小能够带来很高的分辨性,因为它最大程度上利用了像素色彩值的信息,从而能够保证对其差异性的区分度。
然而采用这种方式将占据很大的存储空间,同时实验数据集可能在数量上难以达到所需的基本限度,因为相对256^3个柄数而言,实验数据集能提供的像素集会相对稀疏,进行影响实验结果。另一方面,在不明显降低可分辨性的同时,采用较少的量化等级可以减少存储代价。根据前人的经验,在256,128,64,32,16这些量化等级中,等级32是一个相对较好的折中点。为了验证各种不同直方图模型大小对实验结果的影响,本实验首先采用256作为量化等级,并选取其它量化等级与之进行对比。
本次实验用以构建颜色直方图模型所需要的图像数据集主要来源于随机抓取的网页图片。整个图像数据集分为两类——包含人体皮肤的图像类和完全不含有任何皮肤的图像类,这两类数据集各由约500张图像构成。在图像搜集完毕之后,还需使用相关图像处理软件对这些图像中包含的标签、水印等进行剔除,以筛选出符合预期要求的数据集。
为保障数据样本的普遍性和无偏性,实验数据集覆盖男、女、老、幼各类人群以及各种不同场景、不同背景的图像。最终数据集包括500张含有人体皮肤区域的皮肤图像类和500张不含任何皮肤区域的非皮肤图像类。
数据搜集完毕后,就开始进行模型的训练。基于方便性考虑,本次实验对训练数据集的图像作了统一的尺寸调整:其中皮肤类图像统一处理为240*320(像素)的大小,非皮肤类图像则统一处理为600*400(像素)的大小。
下图是一个皮肤类图像处理的示例,前面是处理前的图像,后面为经人工提取皮肤像素并经过填充处理后的图像:

在图像尺寸统一以及皮肤像素区域的提取完成之后,接下来便开始构建皮肤类和非皮肤类的直方图模型。直方图模型的构建就是在这两类数据集中分别进行。对于皮肤类直方图模型而言,针对每一幅处理过后的皮肤类图像,逐行逐列的将其中每一个像素的R、G、B值信息读取出来。其中的每一个像素点都对应着一组(R,G,B)三维色彩值。在依次读完一副图像的所有像素之后,就能获取所有在该图像中的皮肤像素的色彩值信息了。
在对全部图像中的像素点所对应的色彩值进行计数后,皮肤类的颜色直方图模型也就构建完毕了。在256量级的模型中,共有256^3个柄数,其中每一个柄中存储的是该柄对应的色彩值在以上所有皮肤类图像中出现的次数,这个就是通过前面的计数过程来实现的。
而对于非皮肤类模型而言,它的构建方法是完全类似的。
三、利用直方图模型进行皮肤检测
在两类直方图模型构建完毕之后,接下来就是利用构建好的模型进行皮肤检测。检测的过程分为两步:1、概率的计算;2、运用贝叶斯决策进行皮肤像素的判别。
从“计数”到“概率”:
当两种模型构建完毕之后,对于任一给定的像素而言就能够通过其色彩值来计算相关概率了。对于任一指定的像素而言,如果规定P(rgb|skin)为该像素对应的色彩值在皮肤直方图中出现的概率,而规定 P(rgb|nonskin)为该像素对应的色彩值在非皮肤类直方图中出现的概率,则可以很容易的得到如下计算公式:
P(rgb|skin) = s[rgb] / Ts;
P(rgb|nonskin) = n[rgb] / Tn;
其中s[rgb]是该像素对应的色彩值在皮肤类直方图模型中对应的彩色单位柄中储存的计数和,而n[rgb]则相应的是该像素对应色彩值在非皮肤类直方图模型中对应的彩色单位柄中存储的计数和,Ts和Tn分别是皮肤类和非皮肤类直方图模型所包含的像素总个数。
通过以上算式我们可以得到任一像素对应的色彩值在两类颜色直方图模型中出现的概率了,亦即完成了从计数到概率的转化。
贝叶斯决策:
皮肤检测的核心步骤是在给定任一像素后,计算其属于皮肤像素的概率,这个过程是通过色彩值的相关概率判别来实现的,本次实验采用贝叶斯决策来进行判别。
在贝叶斯决策判别中,对任一给定像素而言,需要事先指定它“先验”的属于皮肤类的概率P(skin)以及“先验”的属于非皮肤类的概率P(nonskin)。由于两者之和为1,所以只需要指定其中一个就行。对于皮肤类的先验概率而言,一个比较合理的选择方案是将其设定为直方图中全部皮肤像素的总数与全体像素总数的比率,由于非皮肤类直方图模型是不含“皮肤”像素的,而皮肤类直方图模型中只有皮肤像素,于是我们可以利用如下公式来计算:
P(skin) = Ts / (Ts + Tn)
P(nonskin) = 1 - P(skin)
其中Ts和Tn的含义如前所述,分别是皮肤类和非皮肤类直方图模型所包含的像素总个数。在指定了先验概率之后,我们便可依据贝叶斯决策,通过如下算式来计算一个给定像素色彩值属于皮肤类的概率大小了:
P(skin|rgb) = P(rgb|skin)P(skin) / [P(rgb|skin)P(skin)+P(rgb|nonskin)P(nonskin)]
在求得了任一指定像素属于皮肤类概率的大小之后,要具体判断其是否属于皮肤类可采取如下方式:
1.设定阈值x,计算所得的概率大于x,则将其判定为皮肤类像素,反之则将其归为非皮肤类像素;
2.计算任一像素色彩值属于非皮肤类的概率:
P(nonskin|rgb) = P(rgb|nonskin)P(nonskin) / [P(rgb|skin)P(skin)+P(rgb|nonskin)P(nonskin)]
如果对于指定的像素有:P(skin|rgb) > P(nonskin|rgb),则将其判定为皮肤类像素,反之则将其判定为非皮肤类像素。
在后面的实验中,会将以上两种判别方式进行测试与对比,通过比较二者的正检率和误检率来评判优劣。对于第一种方式,还会通过改变阈值x的大小进行一系列对比,以观测阈值的改变对实验结果的影响,检测指标同样是基于测试数据集的正检率和误检率。
四、实验结果与对比分析
部分实验结果展示:





检测标准:
对于皮肤检测而言,检测其性能优劣最佳的方式是测试它的正检率和错检率。所谓正检率是指被正确的归为皮肤类像素的像素点的个数除以原图像本身具有的皮肤类像素点的个数。而错检率指的是那些最终被归为皮肤类像素而事实上又不是皮肤类像素的点的个数除以原图像本身具有的非皮肤类的像素个数。在直方图量级为256,训练数据集为原始数据集,同时采用的是决策方案一并且阈值 x = 0.5,最终实验结果如下表所示:

不同的直方图量级:
如前所述,直方图模型大小的选择是除颜色空间之外另一个需要考虑的问题。为了比较不同直方图量级对皮肤检测性能的影响我依次测试了256、128、64、32、16五种直方图量级对应的正检率和错检率,为了科学的反映实验结果与变量的关系,我在五次实验中采用的测试数据集为同一个集合,这样可以避免测试集的差异给实验结果造成干扰,同时其余设置均采用初试设置,即采用的是决策方案一并且设定的阈值 x = 0.5,最终实验结果如下表所示:
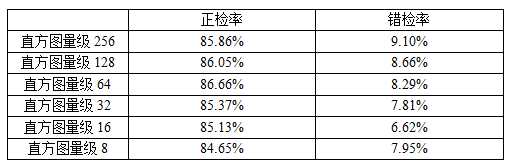
从实验结果中我们可以看到:对于正检率而言,一开始它随着直方图量级的递减而递增,随后它在量化等级为64时达到一个最高值,以后就随着直方图量级的继续递减而递减。对于错检率而言,一开始它随着直方图量级的递减而递减,在直方图量级为16时达到最小值,随后在直方图量级为8时大幅上升。
分析以上实验数据,可以印证之前的相关结论:抛开储存代价不谈,仅就检测性能而言,理论上讲,采用量级为256大小的直方图将能够带来最高的分辨性,因为它最大程度上利用了像素色彩值的信息从而能够保证对其差异性的区分度。但是在现实条件下我们不得不面对训练数据量不够充足的问题:如果训练数据量足够大,那么采用256量级的直方图模型无疑是最好的选择;但是如果训练数据还不够充足的话,那么相对于庞大的直方图空间而言,数据的稀疏分布显然将会对实验结果造成不良影响。实验结果很清晰的反映了这一点,因此相比较而言,折中的量级直方图在性能上表现更好。
下面我将给出对于同一幅图像使用不同量级的直方图模型的检测效果图,以便更直观的反映实验结果。


不同训练数据量:
除了直方图量级会对皮肤检测的性能造成影响外,训练数据量的改变同样会给检测结果带来差异,当训练数据量锐减或者两类训练数据出现严重不均衡的时候,在同一直方图量级下以及同一测试集下正检率和错检率都会改变,在256的直方图量级下同时采用决策方案二测得的具体实验数据结果如下表所述:
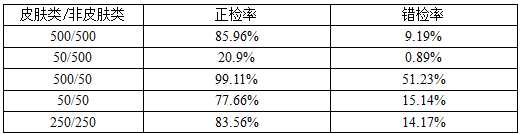
从实验结果中我们可以清楚的看到,训练数据量的改变对实验结果的影响是巨大的。随着皮肤类训练图像张数的递减正检率也会随之而降低,尤其当皮肤类和非皮肤类图像数据有严重不均衡的时候,正检率几乎是锐减。这说明了保持两类训练数据大体上平衡是极其重要的,因为如果某一类的数据显著多于另一类的话,该类识别的敏感度自然就会锐减,因为它得到的训练量小、对信息储存的少,也就难以达到训练的目的。
本次实验结果说明:尽可能的扩大训练数据量,以及尽可能的保持两类训练数据量的平衡,将会对皮肤检测的性能的改善起着重大作用。
两种不同的决策方式:
在算得相应的概率后,如前所述有几种不同的方式来判别一个像素究竟是否属于皮肤类:
1.设定一个阈值x,如果所求得的相应RGB颜色值属于皮肤类的概率大于x的话,我就将其判定为皮肤类像素,反之则将其归为非皮肤类像素;
2.采用对比的方法,如果对于指定的像素对应的色彩值有:P(skin|rgb) >P(nonskin|rgb),则将其判定为皮肤类像素,反之则将其判定为非皮肤类像素。
为了验证这两种决策方式谁更有效,我们分别进行了实验验证。对于决策方式一我们设定不同的阈值x进行实验分析,最终的实验结果数据如下表所示:
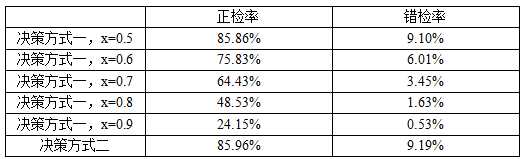
从实验数据结果我们可以看出,如果采取决策方案一,随着设定阈值的提高,正检率和错检率都会急剧下降,这也是符合预期的。因为阈值越高就意味着一个像素被判定为皮肤像素的门槛越高,提高阈值会在降低错检率的同时也降低了正检率。换句话说,在提高阈值后,被错误的归为皮肤类的非皮肤像素将会大大减少;但另一方面,很多原本就属于皮肤类的像素最终会因为门槛的过高而被误判为非皮肤类像素。因此在实际应用中,应该根据实际需要来进行取舍,选取适当的阈值。
五、在彩色深度图像中手型区域提取的应用
实验结果如下图所示:
1.原始图片:

2.皮肤像素识别结果(采用红色标记):

3.结合深度信息得到手型区域结果:

4.二值化处理得到的最终结果:

参考文献:
[1] Michael J. Jones, James M. Rehg: Statistical Color Models with Application to Skin Detection. CRL 98/11 December 1998
[2] B. Jedynak, H. Zheng, M. Daoudi: Statistical models for skin detection. IEEE Workshop on Statistical Analysis in Computer Vision, in conjunction with CVPR 2003 Madison,
Wisconsin, June 16–22, 2003.
标签:
原文地址:http://www.cnblogs.com/floristt/p/4691248.html