标签:
网络爬虫简单介绍
先来看看网络爬虫的基本原理:
一个通用的网络爬虫的框架如图所示:
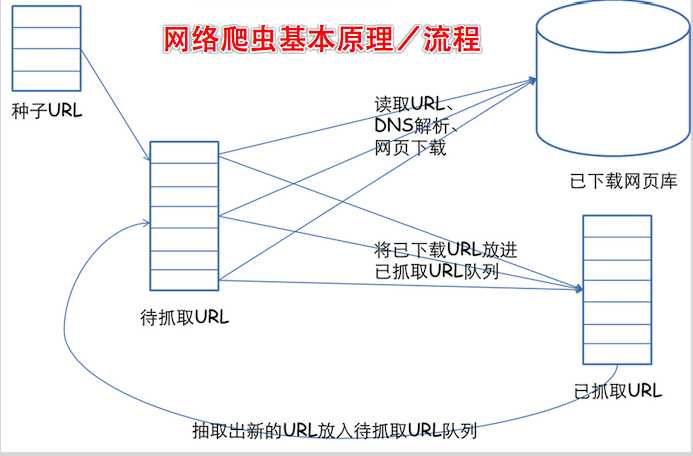
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
以下内容均为本人个人理解。
网络数据抓取
注意点:
其实网络抓取数据很简单,但是有用到正则表达式,这个有人说难,有人说很难,有人说非常难,其实我们抓取数据只会用到“." 、"*"、"?"这三个符号!
正则表达式中:“.”是包括任何字符不包括换行符,“*”是任意多个的字符,“?”是指到最近的一个URL,如果没有就是到最远的一个!
1 NSString *pantten = [NSString stringWithFormat:@"<ul class=\"cs_list\">(.*?)</ul>"]; 2 3 NSRegularExpression *regx = [NSRegularExpression regularExpressionWithPattern:pantten options:NSRegularExpressionCaseInsensitive |NSRegularExpressionDotMatchesLineSeparators error:NULL];
其中有两个参数需要大家了解一下,很重要
NSRegularExpressionCaseinsensitive 不区分大小写 NSRegularExpressionDotMatcheLineSeparators 让“点”字符可以匹配换行符
抓数据,其实主要会写匹配字符串就行
在开发项目的过程,很多情况下我们需要利用互联网上的一些数据,在这种情况下,我们可能要写一个爬虫来爬我们所需要的数据。一般情况下都是利用正则表达式来匹配Html,获取我们所需要的数据。一般情况下分以下三步。
1、获取网页的html
接下来我们分析代码:
1、获取网页的html
对于一些网页,不需要提交Post提交数据时,我们可以简单的利用NSURL类来获取我们所需要的html,交将其转换中kCFStringEncodingGB_18030_2000格式,解决中文乱码问题。
1 +(NSString*) urlstring:(NSString*)strurl{ 2 NSURL *url = [NSURL URLWithString:strurl]; 3 NSData *data = [NSData dataWithContentsOfURL:url]; 4 5 NSStringEncoding enc = CFStringConvertEncodingToNSStringEncoding(kCFStringEncodingGB_18030_2000); 6 NSString *retStr = [[NSString alloc] initWithData:data encoding:enc]; 7 8 //NSLog(@" html = %@",retStr); 9 10 return retStr; 11 }
对于需要Post提交数据的网页,我们可以利用强大的ASIFormDataRequest类来实现,例如:
1 +(void)getPostResult:(NSString*)startqi{ 2 ASIFormDataRequest *request = [[ASIFormDataRequest alloc] initWithURL:[NSURL URLWithString:URLPost]]; 3 4 [request setPostValue:startqi forKey:@"startqi"]; 5 [request setPostValue:@"20990101001" forKey:@"endqi"]; 6 [request setPostValue:@"qihao" forKey:@"searchType"];//网页的中的搜索方式 7 [request startSynchronous]; 8 9 NSData* data = [request responseData]; 10 11 if (data==nil) { 12 FCLOG(@"has not data"); 13 } 14 else{ 15 NSStringEncoding enc = CFStringConvertEncodingToNSStringEncoding(kCFStringEncodingGB_18030_2000); 16 NSString *retStr = [[NSString alloc] initWithData:data encoding:enc]; 17 FCLOG(@"html = %@",retStr); 18 } 19 }
这样的话,我们就通过了两种方式获取了我们所需要的html
2、分析html
关于利用正则表达式匹配问题,我又对NSString类扩展了一个方法-(NSMutableArray *)substringByRegular:(NSString *)regular。根据传入的正则表达式,返回所有匹配的数组。
1 @implementation NSString(StringRegular) 2 3 4 -(NSMutableArray *)substringByRegular:(NSString *)regular{ 5 6 NSString * reg=regular; 7 8 NSRange r= [self rangeOfString:reg options:NSRegularExpressionSearch]; 9 10 NSMutableArray *arr=[NSMutableArray array]; 11 12 if (r.length != NSNotFound &&r.length != 0) { 13 14 int i=0; 15 16 while (r.length != NSNotFound &&r.length != 0) { 17 18 FCLOG(@"index = %i regIndex = %d loc = %d",(++i),r.length,r.location); 19 20 NSString* substr = [self substringWithRange:r]; 21 22 FCLOG(@"substr = %@",substr); 23 24 [arr addObject:substr]; 25 26 NSRange startr=NSMakeRange(r.location+r.length, [self length]-r.location-r.length); 27 28 r=[self rangeOfString:reg options:NSRegularExpressionSearch range:startr]; 29 } 30 } 31 return arr; 32 } 33 @end
在这种情况下,我们首先我得到我们要获取数据的正则表达式,关于正则表达式这种火星文我就不多说了,我也很纠结,我就不多说了,但是有一点就是,所写的正则表达式一定是我们所需要的数据,并且能够屏蔽无效信息的,有可能在一次匹配中无法获取,可以多次利用正则表达式来分段获取。下面是我的语句,在我的例子中,就是两次利用正则表达式。
NSString *regstr = @"<td class=\‘z_bg_05\‘>\\w{11}</td><td class=\‘z_bg_13\‘>(\\w{2}\\s{0,1})*</td>"; NSMutableArray *arr=[strhtml substringByRegular:regstr];
3、分析或利用数据,在这里,我只是利用上一篇博客上所述方法简单的把这些数据保存到了数据库(sqlite3)中。
其实在这个arr数组中一条就是对应我数据库表中的一条记录,但是像td class等这些信息我是不需要的,所以再次利用正则表达式来分析NSString
1 if (arr!=nil&&[arr count]>0) { 2 3 NSString *prereg=@"\\w{11}"; 4 NSString *backreg=@"(\\w{2}\\s{0,1}){8}"; 5 6 TicketResultService *service=[[TicketResultService alloc] init]; 7 [[Sqlite3Helper Instance] openDB]; 8 for (NSString *sub in arr) { 9 10 TicketResult* r=[[[TicketResult alloc] init] autorelease]; 11 12 NSMutableArray* prearr=[sub substringByRegular:prereg]; 13 14 if (prearr!=nil&&[prearr count]>0) { 15 r.sectionID=(NSString*)[prearr objectAtIndex:0]; 16 } 17 else{ 18 continue; 19 } 20 21 NSMutableArray *backarr=[sub substringByRegular:backreg]; 22 if (backarr!=nil&&[backarr count]>0) { 23 r.result=[backarr objectAtIndex:0]; 24 } 25 else{ 26 continue; 27 } 28 29 if([service isExist:r.sectionID]){ 30 continue; 31 } 32 33 r.type=[NSNumber numberWithInt:1]; 34 35 [service addModel:r]; 36 37 } 38 [[Sqlite3Helper Instance] closeDB]; 39 40 [service release]; 41 }
以上爬虫才算正式完成,其实,在此之前还有一个第0步,即判断设备目前的网络状态,如果没有联网的就没有必要去爬虫了,因为你也爬不到任何的数据。判断网络状态我是利用Apple官方的一个例子Reachability,网上也有很多关于这个的例子,我就不再细说了,非常感谢网上的各位大牛们提供的很好的办法,让我能更快的写出这些。
标签:
原文地址:http://www.cnblogs.com/iCocos/p/4714115.html