标签:style blog http color 文件 os
新手学python,写了一个抓取网页后自动下载文档的脚本,和大家分享。
首先我们打开三亿文库下载栏目的网址,比如专业资料(IT/计算机/互联网)http://3y.uu456.com/bl-197?od=1&pn=0,可以观察到,链接中pn=后面的数字就是对应的页码,所以一会我们会用iurl = ‘http://3y.uu456.com/bl-197?od=1&pn=‘,后面加上页码来抓取网页.
一般网页会用1,2,3...不过机智的三亿文库用0,25,50...来表示,所以我们在拼接url时还得转换一下。
右键查看网页源代码,可以观察到这里每一个文档都用一个<a>标签标记,href对应文档的链接,title是文档名字,我们只需要用正则表达式将其“扣”出来就可以了.
不过你会发现我们扣出来的文档地址eg:"bp-602d123348d7c1c708a14sqb-1.html", 并不是真正的文档下载地址,进一步点击文档至下载页面,我们可以发现文档真正的下载路径是:“dlDoc-602d123348d7c1c708a14sqb-1-toword.doc”,清晰易见,我们只需提取文档序号602d123348d7c1c708a14sqb-1,再拼接起来便OK了。
<p> <a href="bp-602d123348d7c1c708a14sqb-1.html" title="视频会议系统" target="_blank">视频会议系统</a> </p>
<a rel="nofollow" target="_blank" href="dlDoc-602d123348d7c1c708a14sqb-1-toword.doc">视频会议系统-第1页.doc</a>
运行结果如下: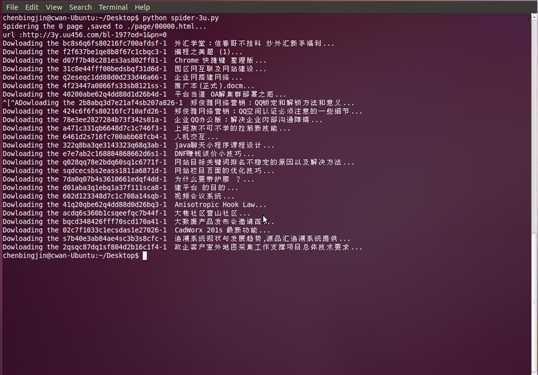
代码如下:
# -*- coding: utf-8 -*- #----------------------------------------------------- # 功能:将访问的页面存储为html文件,并将页面内的文档下载至本地 # 作者:chenbjin # 日期:2014-07-10 # 语言:Python 2.7.6 #----------------------------------------------------- import string import urllib import urllib2 import re import os #函数功能:抓取begin-end页面,存入threeuPage文件夹中,并将其中的文档下载到threeuFile文件夹中。 def threeu_page(burl,url,begin_page,end_page) : #The directory to save web page sPagePath = ‘./treeuPage‘ if not os.path.exists(sPagePath) : os.mkdir(sPagePath) #The director to save downloaded file sFilePath = ‘./threeuFile‘ if not os.path.exists(sFilePath) : os.mkdir(sFilePath) for i in range(begin_page,end_page+1) :
pn = (i-1)*25 #自动填充成六位的文件名,eg:00001.html sName = sPagePath + ‘/‘+ string.zfill(i,5) + ‘.html‘ print ‘Spidering the ‘ + str(i) + ‘ page ,saved to ‘ + sName + ‘...‘ f = open(sName,‘w+‘) user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ headers = { ‘User-Agent‘ : user_agent } request = urllib2.Request(url+str(pn),headers = headers) try: con = urllib2.urlopen(request, timeout=10).read() #正则匹配出文档的地址 myItems = re.findall(‘<a href="bp-(.*?).html" title="(.*?)" target="_blank">(.*?)</a>‘,con,re.S) #print "Total : ",len(myItems) for item in myItems : print ‘Dowloading the ‘ +item[0] + " "+ item[1].decode(‘gbk‘) + ‘...‘ #下载文档 durl = burl+item[0]+‘-toword.doc‘ urllib.urlretrieve(durl,sFilePath+‘/‘+item[1].decode(‘gbk‘)+‘.doc‘) except urllib2.URLError,e : print e else: f.write(con) f.close() #这是三亿文库中“专业资料 > IT/计算机 > 互联网”的地址 burl = ‘http://3y.uu456.com/dlDoc-‘ iurl = ‘http://3y.uu456.com/bl-197?od=1&pn=‘ ibegin = 1 iend = 1 threeu_page(burl,iurl,ibegin,iend) #end
参考资料:
1.Python爬虫入门教程:http://blog.csdn.net/column/details/why-bug.html
Python小爬虫-自动下载三亿文库文档,布布扣,bubuko.com
标签:style blog http color 文件 os
原文地址:http://www.cnblogs.com/chenbjin/p/3835607.html