标签:
lucene最重要的索引问里面是怎么存放的呢?也就是lucene索引文件的格式是怎么保存的。
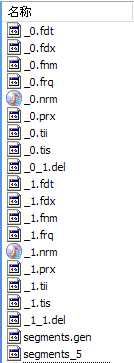
当写好一个索引-搜索的demo的时候,运行程序后,会在指定的indexDirectory生成索引文件:
索引的格式:
Lucene的索引结构是有层次结构的,主要分以下几个层次:
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
所谓正向信息:
所谓反向信息:
Index –> Segments (segments.gen, segments_N) –> Field(fnm, fdx, fdt) –> Term (tvx, tvd, tvf)。
segments.gen和segments_N保存的是段(segment)的元数据信息(metadata),其实是每个Index一个的,而段的真正的数据信息,是保存在域(Field)和词(Term)中的
标签:
原文地址:http://www.cnblogs.com/mggwct/p/4725655.html