标签:
在正式开始本内容之前,需要先从github下载相关代码,搭建好一个名为mysql_shiyan的数据库(有三张表:department,employee,project),并向其中插入数据。
具体操作如下,首先输入命令进入Desktop:
cd Desktop
然后再输入命令,下载代码:
git clone http://git.shiyanlou.com/shiyanlou/SQL4
下载完成后,输入“cd ~”(注意有空格)退回到原先目录,然后输入命令开启MySQL服务并使用root用户登录:
sudo service mysql start #打开MySQL服务
mysql -u root #使用root用户登录
刚才从github下载的SQL4目录下,有个两文件“MySQL-04-01.sql”和“MySQL-04-02.sql”,其中第一个文件用于创建数据库,第二个文件向数据库中插入数据。
(SQL4目录在桌面上,你可以用Gedit查看里面两个的文件。)
输入命令运行第一个文件,搭建数据库:
source /home/shiyanlou/Desktop/SQL4/MySQL-04-01.sql
运行第二个文件,向数据库中插入数据:
source /home/shiyanlou/Desktop/SQL4/MySQL-04-02.sql
在数据库操作语句中,使用最频繁,也被认为最重要的是SELECT查询语句。之前的实验中,我们已经在不少地方用到了 SELECT * FROM table_name; 这条语句用于查看一张表中的所有内容。 而SELECT与各种限制条件关键词搭配使用,具有各种丰富的功能,这次实验就进行详细介绍。
SELECT语句的基本格式为:
SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;
如果要查询表的所有内容,则把要查询的列名用一个 * 号表示(实验2、3中都已经使用过),代表要查询表中所有的列。 而大多数情况,我们只需要查看某个表的指定的列,比如要查看employee表的name和age:
SELECT name,age FROM employee;

SELECT语句常常会有WHERE限制条件,用于达到更加精确的查询。WHERE限制条件可以有数学符号 (=,<,>,>=,<=) ,刚才我们查询了name和age,现在稍作修改:
SELECT name,age FROM employee WHERE age>25;
筛选出age大于25的结果:

或者查找一个名字为Mary的员工:
SELECT name,age,phone FROM employee WHERE name=‘Mary‘;
结果当然是:

从这两个单词就能够理解它们的作用。WHERE后面可以有不止一条限制,而根据条件之间的逻辑关系,可以用OR(或)和AND(且)连接:
SELECT name,age FROM employee WHERE age<25 OR age>30; #筛选出age小于25,或age大于30

SELECT name,age FROM employee WHERE age>25 AND age<30; #筛选出age大于25,且age小于30

而刚才的限制条件 age>25 AND age<30 ,如果需要包含25和30的话,可以替换为 age BETWEEN 25 AND 30 :

关键词IN和NOT IN的作用和它们的名字一样明显,用于筛选“在”或“不在”某个范围内的结果,比如说我们要查询在dpt3或dpt4的人:
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt IN (‘dpt3‘,‘dpt4‘);

而NOT IN的效果则是,如下面这条命令,查询出了不在dpt1也不在dpt3的人:
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt NOT IN (‘dpt1‘,‘dpt3‘);

关键字 LIKE 在SQL语句中和通配符一起使用,通配符代表未知字符。SQL中的通配符是 _ 和 % 。其中 _ 代表一个未指定字符,% 代表不定个未指定字符。
比如,要只记得电话号码前四位数为1101,而后两位忘记了,则可以用两个 _ 通配符代替:
SELECT name,age,phone FROM employee WHERE phone LIKE ‘1101__‘;
这样就查找出了1101开头的6位数电话号码:

另一种情况,比如只记名字的首字母,又不知道名字长度,则用 % 通配符代替不定个字符:
SELECT name,age,phone FROM employee WHERE name LIKE ‘J%‘;
这样就查找出了首字母为 J 的人:

为了使查询结果看起来更顺眼,我们可能需要对结果按某一列来排序,这就要用到 ORDER BY 排序关键词。默认情况下,ORDER BY的结果是升序排列,而使用关键词ASC和DESC可指定升序或降序排序。 比如,我们按salary降序排列,SQL语句为:
SELECT name,age,salary,phone FROM employee ORDER BY salary DESC;

SQL允许对表中的数据进行计算。对此,SQL有5个内置函数,这些函数都对SELECT的结果做操作:
| 函数名: | COUNT | SUM | AVG | MAX | MIN |
|---|---|---|---|---|---|
| 作用: | 计数 | 求和 | 求平均值 | 最大值 | 最小值 |
其中COUNT函数可用于任何数据类型(因为它只是计数),而另4个函数都只能对数字类数据类型做计算。
具体举例,比如计算出salary的最大、最小值,用这样的一条语句:
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee;
有一个细节你或许注意到了,使用AS关键词可以给值重命名,比如最大值被命名为了max_salary:

上面讨论的SELECT语句都仅涉及一个表中的数据,然而有时必须处理多个表才能获得所需的信息。例如:想要知道名为"Tom"的员工所在部门做了几个工程。员工信息储存在employee表中,但工程信息储存在project表中。 对于这样的情况,我们可以用子查询:
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project
WHERE of_dpt IN
(SELECT in_dpt FROM employee WHERE name=‘Tom‘);

子查询还可以扩展到3层、4层或更多层。
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接(join)操作。 连接的基本思想是把两个或多个表当作一个新的表来操作,如下:
SELECT id,name,people_num
FROM employee,department
WHERE employee.in_dpt = department.dpt_name
ORDER BY id;
这条语句查询出的是,各员工所在部门的人数,其中员工的id和name来自employee表,people_num来自department表:

另一个连接语句格式是使用JOIN ON语法,刚才的语句等同于:
SELECT id,name,people_num
FROM employee JOIN department
ON employee.in_dpt = department.dpt_name
ORDER BY id;
结果也与刚才的语句相同。
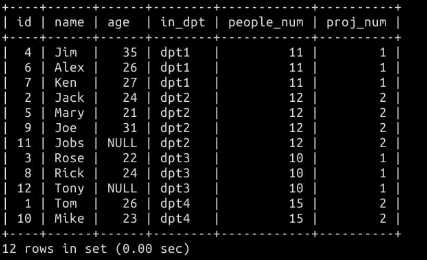
1、使用连接查询的方式,查询出各员工所在部门的人数与工程数,工程数命名为count_project。(连接3个表,并使用COUNT内置函数)
代码如下:(SQL基础不好,研究了好大会儿呢,可能有些繁琐的地方,欢迎指正!):

结果:
(大数据工程师学习路径)第四步 SQL基础课程----select详解
标签:
原文地址:http://www.cnblogs.com/yangxiao99/p/4719143.html