标签:
?? 什么是函数
?? 调用函数
?? 创建函数
?? 传入函数
?? 形参
?? 变长参数
?? 函数式编程
?? 变量的作用域
?? 递归
?? 生成器
11.1 什么是函数?
函数是对程序逻辑进行结构化或过程化的一种编程方法.
函数可以以不同的形式出现.
declaration/definition def foo(): print ‘bar‘
function object/reference foo
function call/invocation foo()
函数和过程两者都是可以被调用的实体.
传统意义上的函数或者“黑盒”,可能不带任何输入参数,经过一定的处理,最后向调用者传回返回值
过程是简单,特殊,没有返回值的函数.
python 的过程就是函数,因为解释器会隐式地返回默认值None.
返回值与函数类型
函数会向调用者返回一个值, 而实际编程中大偏函数更接近过程,不显示地返回任何东西.
把过程看待成函数的语言通常对于“什么都不返回”的函数设定了特殊的类型或者值的名字。
这些函数在c 中默认为“void"的返回类型,意思是没有值返回。
在python 中, 对应的返回对象类型是None。
>>> def hello():
... print(‘hello world !‘)
...
>>> hello()
hello world !
>>> he = hello()
hello world !
>>> print(he)
None
>>>
与其他大多数的语言一样,python 里的函数可以返回一个值或者对象.
>>> def bar():
... return (‘abc‘,[42,‘python‘],‘Guido‘)
...
>>> bar()
(‘abc‘, [42, ‘python‘], ‘Guido‘)
>>> for item in tup:
... print(item)
...
abc
[42, ‘python‘]
Guido
>>>
表11.1 返回值及其类型
许多静态类型的语言主张一个函数的类型就是其返回值的类型。在python 中, 由于python 是
动态地确定类型而且函数能返回不同类型的值,所以没有进行直接的类型关联。因为重载并不是语
言特性,程序员需要使用type()这个内建函数作为代理,来处理有着不同参数类型的函数的多重声
明以模拟类C 语言的函数重载(以参数不同选择函数的多个原型)。
11.2 调用函数
函数操作符
同大多数语言相同,我们用一对圆括号调用函数. 函数的操作符同样用于类的实例化.
关键字参数
关键字参数的概念仅仅针对函数的调用.
这种理念是让调用者通过函数调用中的参数名字来区分参数.
这样规范允许参数缺失或者不按顺序,因为解释器能通过给出的关键字来匹配参数的值.
当参数允许"缺失“的时候,也可以使用关键字参数.这取决于函数的默认参数.
>>> def net_conn(host, port):
... pass #net_conn_suite
...
>>> net_conn(‘kappa‘, 8080) #标准调用,只要按照函数声明中参数定义的顺序,输入恰当的参数
>>> net_conn(port=8080, host=‘kappa‘) #关键字调用,不按照函数声明中的参数顺序输入,但是要输入相应的参数名,
>>>
默认参数
默认参数就是声明了默认值的参数,因为给参数赋予了默认值,所以, 在函数调用时,不向该参数传入值也是允许的。
>>> def foo(arg = ‘bar‘):
... print(arg)
...
>>> foo()
bar
>>> foo(‘baz‘)
baz
>>> foo(arg=‘fubar‘)
fubar
>>>
参数组
Python 同样允许程序员执行一个没有显式定义参数的函数。
元组(非关键字参数)
字典(关键字参数)作为参数组传递给函数
可以将所有参数放进一个元组或者字典中,仅仅用这些装有参数的容器来调用一个函数,而不必显式地将它们放在函数调用中:
func(*tuple_grp_nonkw_args, **dict_grp_kw_args) #*tuple **dict
tuple_grp_nonkw_args 是以元组形式体现的非关键字参数组,
dict_grp_kw_args 是装有关键字参数的字典
>>> def foo(a,b,c):
... print(str(a) + ‘ ‘ + str(b) + ‘ ‘ + str(c))
...
>>> foo(*(1,2,3))
1 2 3
>>> foo(**{‘a‘:1,‘c‘:3,‘b‘:2})
1 2 3
>>> foo(**{‘a‘:‘a‘,‘c‘:‘c‘,‘b‘:‘b‘})
a b c
>>>
11.3 创建函数
def 语句
函数是用def 语句来创建的,语法如下:
def function_name(arguments):
"function_documentation_string"
function_body_suite
标题行由def 关键字,函数的名字,以及参数的集合(如果有的话)组成。
def 子句的剩余部分包括了一个虽然可选但是强烈推荐的文档字串,和必需的函数体。
声明与定义比较
在某些编程语言里, 函数声明和函数定义区分开的。一个函数声明包括提供对函数名,参数的名字(传统上还有参数的类型),但不必给出函数的任何代码,具体的代码通常属于函数定义的范畴。
在声明和定义有区别的语言中,往往是因为函数的定义可能和其声明放在不同的文件中。python将这两者视为一体,函数的子句由声明的标题行以及随后的定义体组成的。
前向引用
和其他高级语言类似,Python 也不允许在函数未声明之前,对其进行引用或者调用.(python的函数的声明和定义是一体的)
>>> def foo():
... bar()
...
>>> foo() #NameError 名字错误是当访问没有初始化的标识符 时才产生的异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in foo
NameError: global name ‘bar‘ is not defined
>>> def bar():
... pass
...
>>> foo() #OK
>>>
函数属性
你可以获得每个pyhon 模块,类,和函数中任意的名字空间。你可以在模块foo 和bar 里都有
名为x 的一个变量,,但是在将这两个模块导入你的程序后,仍然可以使用这两个变量。所以,即使
在两个模块中使用了相同的变量名字,这也是安全的,因为句点属性标识对于两个模块意味了不同
的命名空间,比如说,在这段代码中没有名字冲突:
import foo, bar
print foo.x + bar.x
命名空间
句点属性标识
函数对象
函数属性是python 另外一个使用了句点属性标识并拥有名字空间的领域
... ‘foo() -- properly created doc string‘
...
>>> def bar():
... pass
...
>>> bar.__doc__ = ‘Oops, forgot the doc str above‘
>>> bar.version = 0.1
>>> help(foo)
Help on function foo in module __main__:
foo()
foo() -- properly created doc string
>>> help(bar)
Help on function bar in module __main__:
bar()
Oops, forgot the doc str above
>>> bar.__dict__
{‘version‘: 0.1}
>>>
内部/内嵌函数
在函数体内创建另外一个函数(对象)是完全合法的, 这种函数叫做内部/内嵌函数
python 支持静态地嵌套域(在2.1 中引入但是到2.2 时才是标准)
内部函数的整个函数体都在外部函数的作用域(即是你可以访问一个对象的区域)之内,如果没有任何对内嵌函数的外部引用,那么除了在函数体内,任何地方都不能对其进行调用
创造内部函数的方法
在外部函数的定义体内定义函数(用def 关键字)
在外部函数的定义体使用lambda 语句
如果内部函数的定义包含了在外部函数里定义的对象的引用(这个对象甚至可以是在外部函数之外),内部函数会变成被称为闭包(closure)的特别之物。
*函数(与方法)装饰器
装饰器背后的主要动机源自python 面向对象编程,装饰器是在函数调用之上的修饰,这些修饰仅是当声明一个函数或者方法的时候,才会应用的额外调用。
装饰器
装饰器的语法以@开头,接着是装饰器函数的名字和可选的参数,紧跟着装饰器声明的是被修饰的函数,和装饰函数的可选参数。
@decorator(dec_opt_args)
def func2Bdecorated(func_opt_args):
pass
使用了多个装 饰器:
函数组合用数学来定义就像这样: (g · f)(x) = g(f(x))。对于在python 中的一致性
@g
@f
def foo():
:
......与foo=g(f(foo))相同
有参数和无参数的装饰器


是的,装饰器语法一开始有点让你犯迷糊,但是一旦你适应了,唯一会困扰你的就是什么时候
使用带参数的装饰器。没有参数的情况,一个装饰器如:
@deco
def foo(): pass
....非常的直接
foo = deco(foo)
跟着是无参函数(如上面所见)组成。然而,带参数的装饰器decomaker()
@decomaker(deco_args)
def foo(): pass
. . .
需要自己返回以函数作为参数的装饰器。换句话说,decomaker()用deco_args 做了些事并返回
函数对象,而该函数对象正是以foo 作为其参数的装饰器。简单的说来:
foo = decomaker(deco_args)(foo)
这里有一个含有多个装饰器的例子,其中的一个装饰器带有一个参数
@deco1(deco_arg)
@deco2
def func(): pass
This is equivalent to:这等价于:
func = deco1(deco_arg)(deco2(func))
我们希望如果你明白这里的这些例子,那么事情就变得更加清楚了。下面我们会给出简单实用
的脚本,该脚本中装饰器不带任何参数。例子11.8 就是含有无参装饰器的中间脚本。
有参数和无参数的装饰器
那么什么是装饰器?
现在我们知道装饰器实际就是函数。我们也知道他们接受函数对象。但它们是怎样处理那些函
数的呢?一般说来,当你包装一个函数的时候,你最终会调用它。最棒的是我们能在包装的环境下
在合适的时机调用它。我们在执行函数之前,可以运行些预备代码,如post-morrem 分析,也可以在
执行代码之后做些清理工作。所以当你看见一个装饰器函数的时候,很可能在里面找到这样一些代
码,它定义了某个函数并在定义内的某处嵌入了对目标函数的调用或者至少一些引用。从本质上看,
这些特征引入了java 开发者称呼之为AOP(Aspect Oriented Programming,面向方面编程)的概念。
你可以考虑在装饰器中置入通用功能的代码来降低程序复杂度。例如,可以用装饰器来:
?? 引入日志
?? 增加计时逻辑来检测性能
?? 给函数加入事务的能力
对于用python 创建企业级应用,支持装饰器的特性是非常重要的。你将会看到上面的条例与我
们下面的例子有非常紧密地联系,这在例11.2 中也得到了很好地体现。
那么什么是装饰器?
修饰符举例
下面我们有个极其简单的例子,但是它应该能让你开始真正地了解装饰器是如何工作的。这个
例子通过显示函数执行的时间"装饰"了一个(没有用的)函数。这是一个"时戳装饰",与我们在16
章讨论的时戳服务器非常相似。
例子11.2 使用函数装饰器的例子(deco.py)
这个装饰器(以及闭包)示范表明装饰器仅仅是用来“装饰“(或者修饰)函数的包装,返回一
个修改后的函数对象,将其重新赋值原来的标识符,并永久失去对原始函数对象的访问。
1 #!/usr/bin/env python
2
3 from time import ctime, sleep
4
5 def tsfunc(func):
6 def wrappedFunc():
7 print ‘[%s] %s() called‘ % (
8 ctime(), func.__name__)
9 return func()
10 return wrappedFunc
11
12 @tsfunc
13 def foo():
14 pass
15
16 foo()
17 sleep(4)
18
19 for i in range(2):
20 sleep(1)
21 foo()
运行脚本,我们得到如下输出:
[Sun Mar 19 22:50:28 2006] foo() called
[Sun Mar 19 22:50:33 2006] foo() called
[Sun Mar 19 22:50:34 2006] foo() called
逐行解释
5-10 行
在启动和模块导入代码之后, tsfunc()函数是一个显示何时调用函数的时戳的装饰器。它定义
了一个内部的函数wrappedFunc(),该函数增加了时戳以及调用了目标函数。装饰器的返回值是一个
“包装了“的函数。
Lines 12–21
我们用空函数体(什么都不做)来定义了foo()函数并用tsfunc()来装饰。为证明我们的设想,
立刻调用它,然后等待四秒,然后再调用两次,并在每次调用前暂停一秒。
结果,函数立刻被调用,第一次调用后,调用函数的第二个时间点应该为5(4+1),第三次的时
间应该大约为之后的1 秒。这与上面看见的函数输出十分吻合。
你可以在python langugae reference, python2.4 中“What’s New in Python 2.4”的文档
以及PEP 318 中来阅读更多关于装饰器的内容。
修饰符举例
11.4 传递函数
函数是可以被引用的(访问或者以其他变量作为其别名),也作为参 数传入函数,以及作为列表和字典等等容器对象的元素 .
函数有一个独一无二的特征使它同其他对象区分开来,那就是函数是可调用的。
所有的对象都是通过引用来传递的,函数也不例外。
函数对象的引用
当对一个变量赋值时,实际是将相同 对象的引用赋值给这个变量。
如果对象是函数的话,这个对象所有的别名都是可调用的。
>>> def foo():
... ‘print hello world !‘
... print(‘Hello world !‘)
...
>>> foo() #函数对象的调用
Hello world !
>>> bar = foo #当我们把foo 赋值给bar 时,bar 和foo 引用了同一个函数对象,所以能以和调用foo()相同的 方式来调用bar()。
>>> bar() #函数对象的调用
Hello world !
>>>
以把函数作为参数传入其他函数来进行调用
>>> def foo():
... ‘print hello world !‘
... print("Hello world !")
...
>>> def bar(foo):
... ‘call foo to print hello world !‘
... foo()
...
>>> f = foo;
>>> bar(f)
Hello world !
>>> bar(foo)
Hello world !
>>>
11.5 形式参数
python 函数的形参集合由在调用时要传入函数的所有参数组成,这参数与函数声明中的参数列表精确的配对。
这些参数包括: (声明函数时创建的)局部命名空间为各个参数值,创建了一个名字, 一旦函数开始执行,即能访问这个名字。
位置参数 以正确的定位顺序来传入函数的),
关键字参数 以顺序或者不按顺序传入,但是带有参数列表中曾定义过的关键字,
默认参数 所有含有默认值,函数调用时不必要指定的参数。
位置参数
位置参数必须以在被调用函数中定义的准确顺序来传递。
没有任何默认参数的话,传入函数(调用)的参数的精确的数目必须和声明 的数字一致。
作为一个普遍的规则, 无论何时调用函数,都必须提供函数的所有位置参数。
可以不按位置地将关键字参数传入函数,给出关键字来匹配其在参数列表中的合适的位置是被准予的。
由于默认参数的特质,他们是函数调用的可选部分。
默认参数
对于默认参数如果在函数调用时没有为参数提供值则使用预先定义的的默认值。
c++也支持默认参数,和python 有同样的语法:参数名等号默认值。
python 中用默认值声明变量的语法是所有的位置参数必须出现在任何一个默认参数之前。
def func(posargs, defarg1=dval1, defarg2=dval2,...):
"function_documentation_string"
function_body_suite
每个默认参数都紧跟着一个用默认值的赋值语句,如果在函数调用时没有给出值,那么这个赋值就会实现。
所有必需的参数都要在默认参数之前。
为什么用默认参数?
为什么用默认参数?
默认参数让程序的健壮性上升到极高的级别,因为它们补充了标准位置参数没有提供的一些灵活性。这种简洁极大的帮助了程序员。当少几个需要操心的参数时候,生活不再那么复杂。这在一个程序员刚接触到一个API 接口时,没有足够的知识来给参数提供更对口的值时显得尤为有帮助。
使用默认参数的概念与在你的电脑上安装软件的过程类似。一个人会有多少次选择默认安装而不是自定义安装?我可以说可能几乎都是默认安装。这既方便,易于操作,又能节省时间。如果你是那些总是选择自定义安装的顽固分子,请记着你只是少数人之一。
另外一个让开发者受益的地方在于,使开发者更好地控制为顾客开发的软件。当提供了默认值的时候,他们可以精心选择“最佳“的默认值,所以用户不需要马上面对繁琐的选项。随着时间流逝,当用户对系统或者api 越来越熟悉的时候,他们最终能自行给出参数值,便不再需要使用“学步车“了。
为什么用默认参数?
默认函数对象参数举例
1 #!/usr/bin/env python
2
3 from urllib import urlretrieve
4
5 def firstNonBlank(lines):
6 for eachLine in lines:
7 if not eachLine.strip():
8 continue;
9 else:
10 return eachLine
11
12 def firstLast(webpage):
13 f = open(webpage)
14 lines = f.readlines()
15 f.close()
16 print firstNonBlank(lines)
17 lines.reverse()
18 print firstNonBlank(lines)
19
20 def download(url = ‘http://www.w3.org/TR/2000/WD-xml-2e-20000814‘, process = firstLast):
21 try:
22 retval = urlretrieve(url)[0]
23 except IOError:
24 retval = None
25 if retval: #do some processing
26 process(retval)
27
28 if __name__ == ‘__main__‘:
29 download()
View Code
11.6 可变长度的参数
可能会有需要用函数处理可变数量参数的情况。这时可使用可变长度的参数列表。变长的参数在函数声明中不是显式命名的,因为参数的数目在运行时之前是未知的(甚至在运行的期间,每次函数调用的参数的数目也可能是不同的),这和常规参数(位置和默认)明显不同,常规参数都是在函数声明中命名的。由于函数调用提供了关键字以及非关键字两种参数类型,python 用两种方法来支持变长参数,我们了解了在函数调用中使用*和**符号来指定元组和字典的元素作为非关键字以及关键字参数的方法。在这个部分中,我们将再次使用相同的符号,但是这次在函数的声明中,表示在函数调用时接收这样的参数。这语法允许函数接收在函数声明中定义的形参之外的参数。
可变长度的参数
*和**符号
在函数的调用中使用*和**符号来指定元组和字典的元素作为非关键字以及关键字参数
在函数的声明中使用*和**符号来指定元组和字典的元素允许函数接收在函数声明中定义的形参之外的参数。
非关键字可变长参数(元组)
当函数被调用的时候,所有的形参(必须的和默认的)都将值赋给了在函数声明中相对应的局 部变量。剩下的非关键字参数按顺序插入到一个元组中便于访问。
可变长的参数元组必须在位置和默认参数之后,带元组(或者非关键字可变长参数)的函数普 遍的语法如下:
def function_name([formal_args,] *vargs_tuple):
"function_documentation_string"
function_body_suite
星号操作符之后的形参将作为元组传递给函数,
元组保存了所有传递给函数的"额外"的参数(匹 配了所有位置和具名参数后剩余的)。
如果没有给出额外的参数,元组为空。
>>> def tupleVarArgs(arg1,arg2=‘defaultB‘,*theRest):
... ‘display regular args and non-keyword variable args‘
... print(‘formal arg 1:‘,arg1)
... print(‘formla arg 2:‘,arg2)
... for eachXtrArg in theRest:
... print(‘another arg:‘,eachXtrArg)
...
>>> tupleVarArgs(1,2)
formal arg 1: 1
formla arg 2: 2
>>> tupleVarArgs(1,2,(3,4,5,6))
formal args 1: 1
formla arg 2: 2
another arg: (3, 4, 5, 6)
>>> tupleVarArgs(1,2,3,4,5,6)
formal args 1: 1
formla arg 2: 2
another arg: 3
another arg: 4
another arg: 5
another arg: 6
>>>
关键字变量参数(Dictionary)
在我们有不定数目的或者额外集合的关键字的情况中, 参数被放入一个字典中,字典中键为参数名,值为相应的参数值。
使用了变量参数字典来应对额外关键字参数的函数定义的语法:
def function_name([formal_args,][*vargst,] **vargsd):
function_documentation_string function_body_suite
为了区分关键字参数和非关键字非正式参数,使用了双星号(**)。
**是被重载了的以便不与幂运算发生混淆。
关键字变量参数应该为函数定义的最后一个参数,带**。
关键字和非关键字可变长参数都有可能用在同一个函数中,只要关键字字典是最后一个参数并且非关键字元组先于它之前出现。
>>> def foo(formal_arg,*vargst,**vargsd):
... ‘display regular args and all variable args‘
... print(‘formal_args:‘,formal_arg)
... for eachVargst in vargst:
... print(‘vargst:‘,eachVargst)
... for key in vargsd:
... print(‘name %s, value %s‘ %(key,vargsd[key]))
...
>>> foo(1,2,3,4,{5:6,7:8})
formal_args: 1
vargst: 2
vargst: 3
vargst: 4
vargst: {5: 6, 7: 8}
>>> foo(1,2,3,4,{5:6,7:8},a=‘a‘,b=‘b‘)
formal_args: 1
vargst: 2
vargst: 3
vargst: 4
vargst: {5: 6, 7: 8}
name a, value a
name b, value b
>>>
11.7 函数式编程
python 不是也不大可能会成为一种函数式编程语言,但是它支持许多有价值的函数式编程语言构建。
也有些表现得像函数式编程机制但是从传统上也不能被认为是函数式编程语言的构建。
匿名函数与lambda
python 允许用lambda 关键字创造匿名函数。
匿名是因为不需要以标准的方式来声明,比如说, 使用def 语句。
除非赋值给一个局部变量,这样的对象也不会在任何的名字空间内创建名字。
作为函数,它们也能有参数。
一个完整的lambda“语句”代表了一个表达式,这个表达式的定义体必须和声明放在同一行。
匿名函数的语法:
lambda [arg1[, arg2, ... argN]]: expression
参数是可选的,如果使用的参数话,参数通常也是表达式的一部分。
核心笔记:lambda 表达式返回可调用的函数对象。
用合适的表达式调用一个lambda 生成一个可以像其他函数一样使用的函数对象。它们可被传入
给其他函数,用额外的引用别名化,作为容器对象以及作为可调用的对象被调用(如果需要的话,
可以带参数)。当被调用的时候,如过给定相同的参数的话,这些对象会生成一个和相同表达式等价
的结果。它们和那些返回等价表达式计算值相同的函数是不能区分的。
虽然看起来lambdda 是一个函数的单行版本,但是它不等同于c++的内联语句,这种语句的目的是由于性能的原因,在调用时绕过函数的栈分配。
lambda 表达式运作起来就像一个函数,当被调用时,创建一个框架对象。
单行语句.命名函数
def true(): return True
lambda 的等价表达式
lambda :True
内建函数apply()、filter()、map()、reduce()
*apply()
正如前面提到的, 函数调用的语法, 现在允许变量参数的元组以及关键字可变参数的字典, 在 python1.6 中有效的摈弃了apply()。
这个函数将来会逐步淘汰,在未来版本中最终会消失。 我们在这里提及这个函数既是为了介绍下历史,也是出于维护具有applay()函数的代码的目的。
filter()
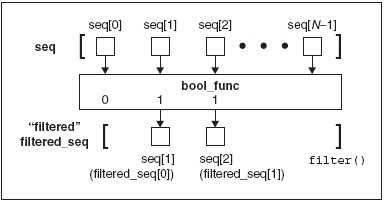
想像下,去一个果园,走的时候带着一包你
从树上采下的苹果。 如果你能通过一个过滤器,将包裹中好的苹果留下,不是一件很令人开心的事
吗?这就是filter()函数的主要前提。给定一个对象的序列和一个“过滤”函数,每个序列元素都
通过这个过滤器进行筛选, 保留函数返回为真的的对象。filter 函数为已知的序列的每个元素调用
给定布尔函数。每个filter 返回的非零(true)值元素添加到一个列表中。返回的对象是一个从原
始队列中“过滤后”的队列。
Figure 11–1 How the filter() built-in function works
形象化其行为的 filter()
>>> def filter(bool_func, seq):
... filtered_seq = []
... for eachItem in seq:
... if bool_func(eachItem):
... filtered_seq.append(eachItem)
... return filtered_seq
...
>>>
map()
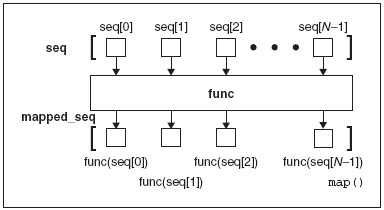
map() 将函数调用“映射”到每个序列的元素上,并返回一个含有所有返回值的列表。
Figure 11–2 How the map() built-in function works
形象化其行为的 filter()
>>> def map(func, seq):
... mapped_seq = []
... for eachItem in seq:
... mapped_seq.append(func(eachItem))
... return mapped_seq
...
>>>
Lambda表达式:
>>> map(lambda x, y: x + y, [1,3,5], [2,4,6])
[3, 7, 11]
>>>
>>> map(lambda x, y: (x+y, x-y), [1,3,5], [2,4,6])
[(3, -1), (7, -1), (11, -1)]
>>>
>>> map(None, [1,3,5], [2,4,6])
[(1, 2), (3, 4), (5, 6)]
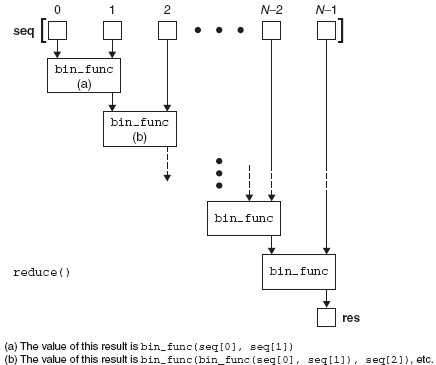
reduce()
函数式编程的最后的一部分是reduce(),reduce 使用了一个二元函数(一个接收带带两个值
作为输入,进行了一些计算然后返回一个值作为输出),一个序列,和一个可选的初始化器,卓有成
效地将那个列表的内容“减少”为一个单一的值,如同它的名字一样。在其他的语言中,这种概念
也被称作为折叠。
Figure 11-3 How the reduce() built-in function works.
形象化其行为的 filter()
reduce(func, [1, 2, 3]) = func(func(1, 2), 3) #等价于
>>> def reduce(func, lseq, init):
... if init is None: #initializer?
... res = lseq.pop(0) #no
... else:
... res = init #yes
... for eachItem in lseq: #reduce sequence
... res = func(res, eachItem) #apply function
... return res
...
>>>
11.8 变量作用域
标识符的作用域是定义为其声明在程序里的可应用范围, 或者即是我们所说的变量可见性。
变量可以是局 部域或者全局域。
全局变量与局部变量
定义在函数内的变量有局部作用域,在一个模块中最高级别的变量有全局作用域。在编译器理 论里有名的“龙“书中,Aho, Sethi, 和ULLman 以这种方法进行了总结。
全局变量
全局变量的一个特征是除非被删除掉,否则它们的存活到脚本运行结束,且对于所有的函数, 他们的值都是可以被访问的,
局部变量
局部变量,就像它们存放的栈,暂时地存在,仅仅只依赖于定义它们的函数现阶段是否处于活动。
当一个函数调用出现时,其局部变量就进入声明它们的作用域,在那一刻,一个新的局部变量名为那个对象创建了,一旦函数完成,框架被释放,变量将会离开作用域。
global_str = ‘foo‘
def foo():
local_str = ‘bar‘
return global_str + local_str
global_str 是全局变量,而local_str 是局部变量。foo()函数可以对全局和局 部变量进行访问,而代码的主体部分只能访问全局变量。
搜索标识符(aka 变量,名字,等等)
核心笔记:搜索标识符(aka 变量,名字,等等)
当搜索一个标识符的时候,python 先从局部作用域开始搜索。如果在局部作用域内没有找到那
个名字,那么就一定会在全局域找到这个变量否则就会被抛出NameError 异常。
一个变量的作用域和它寄住的名字空间相关。对于现在只能 说子空间仅仅是将名字映射到对象的
命名领域,现在使用的变量名字虚拟集合。作用域的概念和用于找到变量的名字空间搜索顺序相关。
当一个函数执行的时候,所有在局部命名空间的名字都在局部作用域内。那就是当查找一个变量的
时候,第一个被搜索的名字空间。如果没有在那找到变量的话,那么就可能找到同名的全局变量。
这些变量存储(搜索)在一个全局以及内建的名字空间。
仅仅通过创建一个局部变量来“隐藏“或者覆盖一个全局变量是有可能的。回想一下,局部名
字空间是首先被搜索的,存在于其局部作用域。如果找到一个名字,搜索就不会继续去寻找一个全
局域的变量,所以在全局或者内建的名字空间内,可以覆盖任何匹配的名字。
>>> bar = ‘bar‘
>>> def foo():
... bar = ‘foo‘
... print(bar)
...
>>> bar
‘bar‘
>>> foo()
foo
>>>
global 语句
将全局变量的名字声明在一个函数体内,全局变量的名字能被局部变量给覆盖掉。但是该变量的全局和局部的特性就不是那么清晰了。
为了明确地引用一个已命名的全局变量,必 须使用global 语句。global 的语法如下:
global var1[, var2[, ... varN]]]
>>> is_this_global = 100
>>> def foo():
... global is_this_global
... print is_this_global
... is_this_global += 100
... print is_this_global
...
>>> foo()
100
200
作用域的数字
python 从句法上支持多个函数嵌套级别,就如在python2.1 中的,匹配静态嵌套的作用域。
在2.1 至前的版本中,最多为两个作用域:一个函数的局部作用域和全局作用域,虽然存在多个函数的嵌涛,但你不能访问超过两个作用域。
闭包(closure)
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是closure。
定义在外部函数内的但由内部函数引用或者使用的变量被称为自由变量。
闭包将内部函数自己的代码和作用域以及外部函数的作用结合起来。
闭包的词法变量不属于全局名字空间域或者局部的--而属于其他的名字空间,带着“流浪"的作用域。
>>> def counter(start_at = 0):
... count = [start_at]
... def incr():
... count[0] += 1
... return count[0]
... return incr
...
>>> count = counter(2003)
>>> for i in range(10):
... print(count())
...
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
>>>
有点不同的是我们能够做些原来需要我们写一个类做的事,并且不仅仅是要写,
而且必需覆盖掉这个类的__call__()特别方法来使他的实例可调用。
追踪闭包词法的变量
*高级闭包和装饰器
作用域和lambda
python 的lambda 匿名函数遵循和标准函数一样的作用域规则。
一个lambda 表达式定义了新的作用域,就像函数定义,所以这个作用域除了局部lambda/函数,对于程序其他部分,该作用域都是不能对进行访问的。
那些声明为函数局部变量的lambda 表达式在这个函数体内是可以访问的;然而,在lambda 语句中的表达式有和函数相同的作用域。
你也可以认为函数和一个lambda 表达式是同胞。
>>> x = 2003
>>> def foo():
... y = 10
... bar = lambda : x + y
... print(bar())
... y = 3
... print(bar())
...
>>> foo()
2013
2006
>>>
变量作用域和名字空间
从函数内部,局部作用域包围了局部名字空间,第一个搜寻名字的地方。如果名字存 在的话,那么将跳过检查全局作用域(全局和内建的名字空间)。
#!/usr/bin/env python
#局部变量隐藏了全局变量,正如在这个变量作用程序中显示的。
j,k = 1,2
def proc1():
j,k = 3,4
print ‘j == %d and k == %d‘ % (j,k)
k = 5
def proc2():
j = 6
print "j == %s" % j
k = 7
proc1()
print ‘j == %d and k == %d‘ % (j, k)
j = 8
proc2()
print ‘j == %d and k == %d‘ % (j, k)
View Code
11.9 *递归
如果函数包含了对其自身的调用,该函数就是递归的。
如 果一个新的调用能在相同过程中较早的调用结束之前开始,那么该过程就是递归的。
递归广泛地应用于语言识别和使用递归函数的数学应用中。
>>> def factorial(n):
... if n == 0 or n == 1: # 0! = 1! = 1
... return 1
... else:
... return n * factorial(n-1)
...
>>> factorial(3)
6
>>> factorial(4)
24
>>>
11.10 生成器
协同程序
协同程序是可以运行的独立函数调 用,可以暂停或者挂起,并从程序离开的地方继续或者重新开始。
在有调用者和(被调用的)协同程序也有通信。
举例来说,当协同程序暂停的时候,我们能从其中获得一个中间的返回值,当调用回到程序中时,能够传入额外或者改变了的参数,但仍能够从我们上次离开的地方继续,并且所有状态完整。
挂起返回出中间值并多次继续的协同程序被称为生成器,那就是python 的生成器真正在做的事。
什么是python 式的生成器?
从句法上讲,生成器是一个带yield 语句的函数。
一个函数或者子 程序只返回一次,但一个生成器能暂停执行并返回一个中间的结果----那就是yield 语句的功能, 返回一个值给调用者并暂停执行。
当生成器的next()方法被调用的时候,它会准确地从离开地方继续(当它返回[一个值以及]控制给调用者时)
简单的生成器特性
与迭代器相似,生成器以另外的方式来运作:当到达一个真正的返回或者函数结束没有更多的 值返回(当调用next()),一个StopIteration 异常就会抛出。
>>> def simpleGen():
... yield 1
... yield ‘2 --> punch‘
...
>>> myG = simpleGen()
>>> myG.next()
1
>>> myG.next()
‘2 --> punch‘
>>> myG.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>> for i in simpleGen():
... print i
...
1
2 --> punch
>>>
加强的生成器特性
在python2.5 中,一些加强特性加入到生成器中,所以除了next()来获得下个生成的值,用户
可以将值回送给生成器[send()],在生成器中抛出异常,以及要求生成器退出[close()]
由于双向的动作涉及到叫做 send()的代码来向生成器发送值(以及生成器返回的值发送回来),
现在yield 语句必须是一个表达式,因为当回到生成器中继续执行的时候,你或许正在接收一个进
入的对象。
11 函数和函数式编程 - 《Python 核心编程》
标签:
原文地址:http://www.cnblogs.com/BugQiang/p/4735626.html