标签:
ConcurrentHashMap使用了锁分离技术, 使用了多个锁来控制对hash表的不同部分进行的修改。使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
段数组是final的,并且其成员变量实际上也是final的。确保不会出现死锁,因为获得锁的顺序是固定的。
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。
Segment继承了ReentrantLock,表明每个segment都可以当做一个锁。
final Segment<K,V>[] segments; static final class HashEntry<K,V> { final K key; final int hash; volatile V value; final HashEntry<K,V> next; }
除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next 引用值,而next也是final的,所有的节点的修改只能从头部开始。
确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁(弱同步)。
默认情况下内部按并发级别为16来创建。对于每个segment的容量,默认情况也是16。
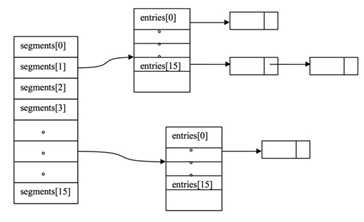
每个段hash槽的的个数都是2^n。
对hash链进行遍历不需要加锁的原因在于链指针next是final的。
通过对count变量的协调机制,get能读取到几乎最新的数据,虽然可能不是最新的。要得到最新的数据,只有采用完全的同步。
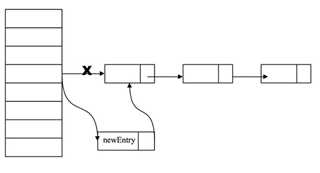
每个HashEntry中的next也是final的,没法对链表最后一个元素增加一个后续entry所以新增一个entry的实现方式只能通过头结点来插入了。如下图所示:
Segment中的get方法:
V get(Object key, int hash) { //segment中存在entry的个数 // count它使用了volatile来修改 //每次判断count变量的时候,即使恰好其他线程改变了segment也会体现出来 if (count != 0) { // ①注意这里 HashEntry<K,V> e = getFirst(hash); 得到头节点 while (e != null) { if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) //②注意这里 return v; //需要重新检查 return readValueUnderLock(e); // recheck } e = e.next; } } return null; }
以上代码中没有使用锁来同步,只是判断获取的entry的value是否为null,为null时才使用加锁的方式再次去获取。
get代码的①和②之间,另一个线程新增了一个entry,如果另一个线程新增的这个entry又恰好是我们要get的,这事儿就比较微妙了。
newEntry对象是通过 new HashEntry(K k , V v, HashEntry next) 来创建的。如果另一个线程刚好new 这个对象时,当前线程来get它。因为没有同步,就可能会出现当前线程得到的newEntry对象是一个没有完全构造好的对象引用。所以才需要判断一下:if (v != null) 如果确实是一个不完整的对象,则使用锁的方式再次get一次。
有没有可能会put进一个value为null的entry? 不会的,已经做了检查,这种情况会抛出异常。
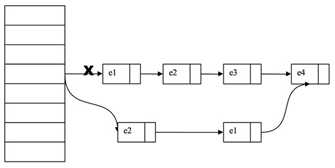
假设我们的链表元素是:e1-> e2 -> e3 -> e4 我们要删除 e3这个entry,因为HashEntry中next的不可变,所以我们无法直接把e2的next指向e4,而是将要删除的节点之前的节点复制一份,形成新的链表。
ConcurrentHashMap的迭代器不是Fast-Fail的方式,所以在迭代的过程中别其他线程添加/删除了元素,不会抛出异常,也不能体现出元素的改动。
Java集合(15)--ConcurrentHashMap源码分析
标签:
原文地址:http://www.cnblogs.com/pipi-style/p/4738083.html