标签:
pinyin4j项目 官网地址 http://pinyin4j.sourceforge.net/
我们先把资源下载下来,连同源码和jar包一起放入工程。如下图:
接下来在demo包下,我们写一个测试类,简单使用pinyin4j对中文字符进行自然排序
新建一个ConvertTest.java

package demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import net.sourceforge.pinyin4j.PinyinHelper;
public class ConvertTest {
public static void main(String[] args) {
String src = "我们中间出了一个叛徒";
char[] arr = src.toCharArray();
System.out.println("数组长度是:"+arr.length);
System.out.print("原始顺序:");
for (char temp : arr) {
System.out.print(temp+" ");
}
System.out.println();
convertToHanyuPinyin(arr);
}
private static List<String> convertToHanyuPinyin(char[] array){
HashMap<String, String> map = new HashMap<String, String>();
for (int i = 0; i < array.length; i++) {
//得到拼音首字母
String value = (PinyinHelper.toHanyuPinyinStringArray(array[i]))[0].substring(0, 1);
map.put(String.valueOf(array[i]), value);
}
System.out.println(map);
List<String> list = sort(map);
return list;
}
private static List<String> sort(Map map){
List<Map.Entry<String, String>> infoIds =
new ArrayList<Map.Entry<String, String>>(map.entrySet());
// 对HashMap中的 value 进行排序
Collections.sort(infoIds, new Comparator<Map.Entry<String, String>>() {
@Override
public int compare(Map.Entry<String, String> o1,
Map.Entry<String, String> o2) {
return (o1.getValue()).compareTo(o2.getValue());
}
});
List<String> list = new ArrayList<String>();
/*****************FOR TEST***********************/
List<String> letterList = new ArrayList<String>();
/*****************FOR TEST***********************/
// 对HashMap中的 value 进行排序后 显示排序结果
for (int i = 0; i < infoIds.size(); i++) {
Map.Entry<String,String> entry = infoIds.get(i);
list.add(entry.getKey());
letterList.add(entry.getValue());
}
/*****************FOR TEST***********************/
System.out.print("自然顺序:");
for (String string : list) {
System.out.print(string + " ");
}
System.out.println();
System.out.print("字母顺序:");
for (String string : letterList) {
System.out.print(string +" ");
}
/*****************FOR TEST***********************/
return list;
}
}
输出结果为:
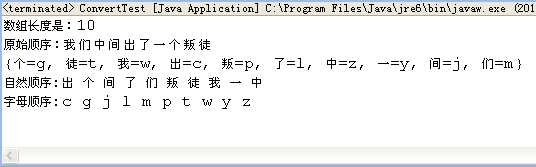
可以看到最终的输出顺序已经是按照自然顺序排序后的结果了。
简单说一下步骤:
1.我们先将字符串序列转换成 单个字符key, 首字母value 的map形式,
如 {个=g, 徒=t, 我=w, 出=c, 叛=p, 了=l, 中=z, 一=y, 间=j, 们=m}。
2. 然后针对map中的value进行排序,并返回排序过后的key值。
(PS:当然这里也可以对key值进行排序,但是最好还是针对value。
因为我们这里截取的是首字母,并不是整个拼音音节。)
代码缺点:
1.只是针对中文字符的第一个拼音进行排序,但是汉语中存在多音字。
2.只是针对字符的首字母进行排序,并不是整个拼音字节,并不严谨,适合粗略排序的场景。
下面简单分析一下,pinyin4j的转换流程。

如上图,其中核心的类就是PinyinHelper。它可以转换许多类型的拼音,这里我们只看汉语拼音,其他的与之类似。
追踪代码 PinyinHelper.toHanyuPinyinStringArray
按ctrl + 鼠标左键。
static public String[] toHanyuPinyinStringArray(char ch)
{
return getUnformattedHanyuPinyinStringArray(ch);
}
继续跟踪代码
private static String[] getUnformattedHanyuPinyinStringArray(char ch)
{
return ChineseToPinyinResource.getInstance().getHanyuPinyinStringArray(ch);
}
调用ChineseToPinyinResource示例的getHanyuPinyinStringArray方法
String[] getHanyuPinyinStringArray(char ch)
{
String pinyinRecord = getHanyuPinyinRecordFromChar(ch);
if (null != pinyinRecord)
{
//得到左括号( 的索引值
int indexOfLeftBracket = pinyinRecord.indexOf(Field.LEFT_BRACKET);
//得到右括号) 的索引值
int indexOfRightBracket = pinyinRecord.lastIndexOf(Field.RIGHT_BRACKET);
//得到字符对应的拼音
String stripedString = pinyinRecord.substring(indexOfLeftBracket
+ Field.LEFT_BRACKET.length(), indexOfRightBracket);
//以逗号.为分隔 返回String[] 数组
return stripedString.split(Field.COMMA);
} else
return null; // no record found or mal-formatted record
}
关键的方法getHanyuPinyinRecordFromChar
private String getHanyuPinyinRecordFromChar(char ch)
{
int codePointOfChar = ch;
//转换成unicode对应的字符
String codepointHexStr = Integer.toHexString(codePointOfChar).toUpperCase();
//从表中查询字符
// fetch from hashtable
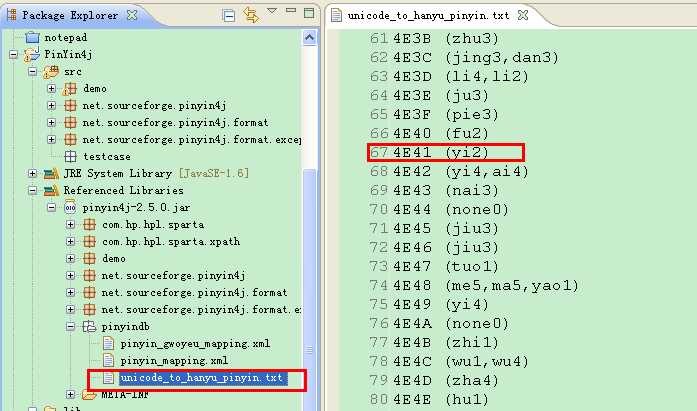
String foundRecord = getUnicodeToHanyuPinyinTable().getProperty(codepointHexStr);
//如果是合法的字符就返回,否则返回null
return isValidRecord(foundRecord) ? foundRecord : null;
}
就是如下图的资源:
http://www.cnblogs.com/sphere/p/4738888.html
浅析pinyin4j源码 简单利用pinyin4j对中文字符进行自然排序(转)
标签:
原文地址:http://www.cnblogs.com/softidea/p/4739106.html