标签:
kmeans算法的python实现:
参考与样本来源《Machine Learning in Action》
1 #-*-coding:UTF-8-*- 2 ‘‘‘ 3 Created on 2015年8月19日 4 @author: Ayumi Phoenix 5 ‘‘‘ 6 import numpy as np 7 8 def distL2(a,b): 9 """ 计算两个向量之间的L2距离 """ 10 return np.sqrt(np.sum((a-b)**2)) 11 12 class Kmeans(): 13 def __init__(self, dataset,k): 14 self.dataset = dataset 15 self.k = k 16 self.m, self.n = dataset.shape 17 18 def randcent(self): 19 """ 根据输入数据集获得随机生成一组簇质心 """ 20 maxn = np.max(self.dataset, 0) # 获取每一维的最大值 21 minn = np.min(self.dataset, 0) # 获取每一维的最小值 22 centoroid = np.random.rand(self.k,self.n) * (maxn - minn) + minn # k x n 23 return centoroid 24 25 def train(self, dist, iter = 1): 26 """ 27 # 1. 计算每个样本与所有簇心的最近匹配距离数组 m x 1: 28 # 计算某样本与所有簇心的距离, 29 # 找到最小距离所属的下标序号 0...k-1 30 # 2. 根据当前类标的分配,重新计算平均聚类中心 31 # 按照当前分配索引样本数据 32 # 迭代次数减一 33 # 3. 返回最终的质心与分配的序号 34 """ 35 centoroid = self.randcent() 36 while iter: 37 labels = np.zeros((self.m,), int) 38 for i in range(self.m): 39 d = [dist(self.dataset[i,:],centoroid[j]) 40 for j in range(self.k)] 41 labels[i] = np.argmin(d) 42 for i in range(self.k): 43 x = self.dataset[labels==i] 44 centoroid[i] = np.mean(x, 0) 45 iter -= 1 46 return centoroid, labels
读取数据与测试函数:
1 ef loadDataSet(filename): 2 dataMat = [] 3 with open(filename) as f: 4 for line in f.readlines(): 5 curline = line.strip().split(‘\t‘) 6 fltline = map(np.float, curline) 7 dataMat.append(fltline) 8 return dataMat 9 10 11 if __name__=="__main__": 12 pass 13 datMat = np.array(loadDataSet(‘testSet.txt‘)) 14 km = Kmeans(datMat,4) 15 centoroid, labels = km.train(distL2, iter=20) 16 17 # 根据当前质心显示样本分布 18 import matplotlib.pylab as pl 19 pl.figure() 20 c = [‘ro‘,‘go‘,‘bo‘,‘yo‘,‘co‘,‘ko‘,‘wo‘,‘mo‘] 21 for i in range(datMat.shape[0]): 22 pl.plot(datMat[i][0],datMat[i][1],c[labels[i]]) 23 for cen in centoroid: 24 pl.plot(cen[0],cen[1],‘mo‘) 25 pl.show()
结果:
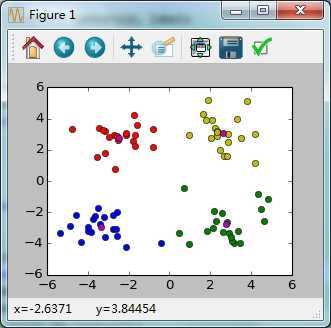
标签:
原文地址:http://www.cnblogs.com/hanahimi/p/4741756.html