标签:
本节您将了解基本可扩展性技术,例如数据库分片。分片被广泛应用于高端系统并提供一个简单而且可靠的扩展设置方式来向外扩展。近年来,分片已经成为一种扩大专业系统规模的标准方式。
如果您的数据量增长超过一台机器的处理能力将会发生什么事情?如果您要运行这么多的事务,一台服务器根本跟不上怎么办?我们假设您有百万级的用户,上万用户想在同一时间执行特定的任务。
显然,某些时候,您再也不能通过购买能够处理无限大的负载的足够大的服务器来解决问题。显然在单个服务器上运行一个类似Facebook或类似Google的应用是不可能的。有些时候,您必须拿出一个可伸缩策略来服务于您的需求。这就是分片应用的场景。
分片的想法很简单:要是您能在某种程度上分裂的数据可以驻留在不同的节点上会怎样?
设计一个分片系统的例子
为了表明分片的基本概念,我们假设一下情形:
我们要存储数百万用户的信息。每个用户都有一个唯一的用户ID。我们进一步假设,我们只有两台服务器。在这种情况下,我们可以存储偶数用户的ID到服务器1上,奇数用户的ID存储到服务器2上。
下图表明这是怎么实现的:
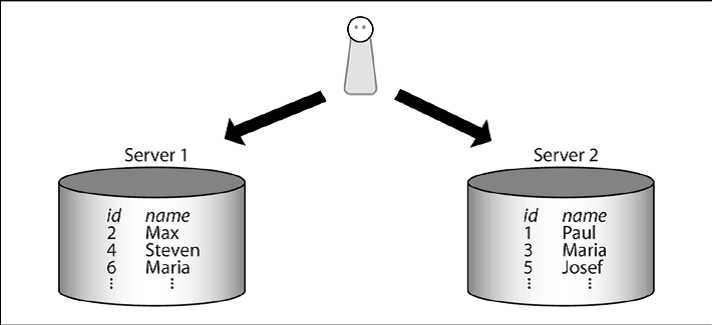
正如您所看到的,在我们的图中,我们已经很好地分发数据。一旦数据分发完成,我们就可以如下向系统发送一个查询:
SELECT * FROM t_user WHERE id = 4;
客户端可以很容易地计算出在哪里可以通过我们的查询检查过滤器找到数据。在我们的例子中,该查询将被发送到第一个节点,因为我们正在处理一个偶数。
正如我们已经基于一个键(key)(这里使用的是用户ID)所分布的数据,如果我们知道键(key)的话,我们可以很容易地搜索到任何人。在大型系统中,通过一个一个键(key)参考用户是常见的做法,因此这种方法是合适的。通过这种简单的方法,我们也可以容易地在我们的系统中使机器数量翻倍。
在设计系统时,我们可以容易地拿出任意数量的服务器;所有我们要做的就是创造一个漂亮的和聪明的分区功能来在我们的服务器集群内部分发数据。如果我们想要在十台服务器(不是问题)以内拆分数据,使用ID%10作为一个分区功能怎么样?
但您试图分布数据到不同的主机上时,必须确保您使用的是一个健壮的分区功能,在某种程度上,它可以非常出色地分布数据,每台主机都或多或少的有同样数量的数据。
用户按照字母顺序来分配数据可能不是一个好主意。其原因在于并不是所有的字母都有同样的可能。我们不能简单地假设从字母A到M发生的情况和字母从N到Z发生的情况一样。如果您想分发一个数据集到一千台服务器而且不仅仅是少数机器,这是一个大问题。如前所述,它必须是一个健壮的分区功能,其产生的分布均匀的效果。
[在大多情况下,哈希函数(散列函数)将为您提供很好且分布均匀的数据。处理字符字段时(例如名字,邮件地址等)特别有用。]
查询不同字段的例子
在上一节中,您已经看到我们如何容易地使用键(key)查询一个人。我们深入探究一下,看看下面的查询会发生什么:
SELECT * FROM t_test WHERE name = ‘Max‘;
请记住,我们使用ID分发数据,在查询中,我们搜索名字。该应用程序将不知要使用哪个分区,因为没有规则告诉我们什么在哪里。
作为一个合乎逻辑的结果,应用程序必须要求每个分区的名字。如果要找的名字是一个真实的情况,这是可以接受的;然而,我们不能依赖这个事实。不得不询问多台服务器而不是一台服务器显然是一个严重的解优化(未优化)而且是不能接受的。
我们有两个选择来处理这个问题:
•提出一个比较智能的分区功能
•冗余存储数据
提出一个比较聪明的分区功能必定是最好的选择,但如果您想查询不同的字段,这几乎是不可能的。
这给我们留下了第二个选项,就是冗余地存储数据。对一个数据集存储两份,或甚至更多份是不太常见的,实际上确实是一个好的方法来解决这个问题。下面的图片显示了这是如何实现的:
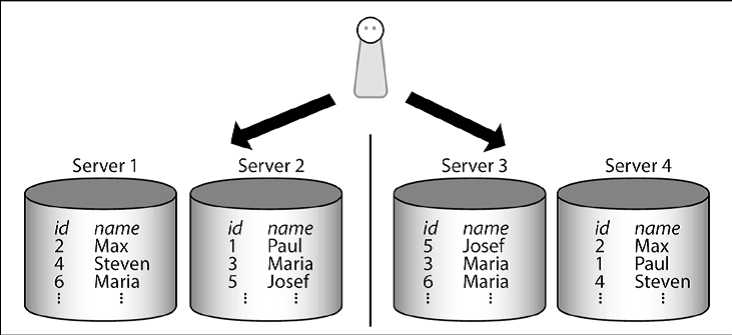
正如您可以看到的,在这个场景我们有两个集群。当一个查询到来,系统必须决定哪些数据可以在哪个节点上找到。万一查询名字,我们(为简单起见)简单地按半字母顺序分割数据。在第一个集群,我们的数据仍然按用户ID分割。
分片不是一个简单的单行道是需要理解的重要的事情。如果有人决定使用分片,必须要认识到技术的优点和缺点。与往常一样,不去思考,没有什么神能奇迹般地解决人类所有的问题。
每个实际使用情况都是不同的,没有替代的常识和深入思考。
首先,我们看一下下面列出来的拆分的优势:
• 它有扩展系统超过一台服务器的能力
• 它是一个简单的方法
• 它被许多框架支持
• 它可以与多种其它复制方法组合
• 它可以很好地支持PostgreSQL(例如使用PL/Proxy)
光与影子倾向于走在一起,因此分片也有其不足之处,如下:
•在运行的集群中添加服务器是非常麻烦的(取决于分区函数的类型)
•可能会严重降低您的灵活性。
•并非所有类型的查询将和在单台服务器上有相同的效果。
•增加了整体安装设置的复杂性(如故障转移等等)。
•备份需要更多的规划。
•您可能面临冗余和额外的存储需求。
•应用程序开发人员应该知道分片,以确保高效的查询被写入。
在第十三章,使用PL/Proxy扩展,我们将讨论如何和PostgreSQL一起能够高效地利用分片,如何最大性能和扩展性地设置PL/Proxy。
学习如何切分一个表只是设计一个可扩展系统架构的第一步。我们在前面章节已经展示的例子中,我们仅仅只有一张表,可以很容易地使用键(key)来拆分。但是,要是我们有不只一张表又会怎么样呢?假设我们有两张表:
•一张表名为t_user的表在我们的系统中存储用户
•一张表名为t_language存储我们的系统支持的语言
我们也许可以很好地通过某种拆分方式来拆分表t_user,这个表也可以分配到一个合理数目的服务器上。但是表t_language怎么办?我们的系统可能支持多达十种语言。
可以很好地分片和分发数以亿计的用户,但是拆分十种语言怎么样?这显然是无用的。除此之外,我们可能需要我们的语言表在所有的节点上以便我们可以进行连接。
解决这个问题的方法很简单:您需要语言表在所有节点上的一个完全的复制。这将不会引起存储浪费的相关问题,因为表是如此的小。
[确保只有大表被分片。对于小表的情况,表的完全复制可能更有效]
同样,每一种情况都必须深思熟虑。
到目前为止,我们一直认为分片大小的设置是恒定不变的。我们已经设置了使我们能够利用一个在我们集群内部固定数目分区的分片方式。这种限制可能无法反应日常的需求。您怎么能够真正地说出在设计的时候某个特定时刻需要的节点的数目?人们可能对硬件需求有一个粗略的想法,但是实际上知道负荷的期望值是一门艺术而不是科学。
[为了反映这一点,您必须设计一个系统,他可以很容易地调整大小。]
一个常见的错误是人们往往会在不必要的小步中增加他们设置的的大小。有人可能会从五台机器增加到六台或七台机器。这可能非常棘手。我们假设在某一时刻我们拆分数据使用用户ID%5来作为分区函数。要是我们想使用用户ID%6又怎样?这不太容易,问题是我们必须在我们的集群内重新平衡数据来反映我们的新规则。
请记住,我们已经介绍了分片(即,分区)因为我们有这么大量的数据和这么多的负载,一台服务器无法处理这么多的请求了。如果我们想出来一个策略,现在需要重新平衡数据。我们已经在错误的轨道上了。您肯定不希望为了添加两台或三台服务器到您现有的服务器而重新平衡20TB的数据。
实际上,简单地加倍分区数目是比较容易的。加倍您的分区不需要重新平衡数据,因为您可以简单地按照后面的策略来做:
•创建每个分区的副本
•删除每个分区上一半的数据
如果之前您的分区函数是用户ID%5,而现在应该是用户ID%10。倍增的优点在于数据不能在两个分区之间移动。但谈到加倍,用户可能会认为您的集群大大小会增长的太快。这是事实,但是如果系统的运行能力达到了极限,增加系统资源的10%并不能解决可扩展性的问题。
不仅仅增加一倍的集群(这是用于大多数情况),您也可以把更多的心思投入到编写一个更复杂的分区功能保留旧的数据,但更智能地处理最新的数据。有时间依赖的分区函数可能导致它自身的问题,但它可能是值得研究的方法。
[一些NoSQL系统采用范围分区传播数据。范围分区意味着一个给定的时间帧每个服务器有固定的数据切片。如果您想要做时间序列分析或相似的工作可能有益。但是,如果您要确保数据被均匀分割可能会适得其反。]
如果您期望您的集群规模扩大,我们建议从开始就设置比最初需要较多的分区,在一台服务器上打包不只一个分区。稍后,移动单个分区到添加到集群的硬件就会很容易。有些云服务能够做到这一点,但是本书不包含这些内容。
要缩小集群是您可以简单地套用反向策略和移动多于一个分区到单个服务器。为将来服务器的增加留下并敞开大门很容易做到。
一旦数据被拆散成有用的组块,可以被一个服务器或分区处理,我们必须考虑如何使整个设置更可靠和故障安全。
在您的设置中服务器越多,这些服务器中的一台服务器越容易由于别的原因宕机或不可用。
[这是设计一个高可扩展的系统时总是要避免单点故障。]
为了确保最大的吞吐量和最大可用性,我们可以再次转向冗余。该设计方法可以归纳为一个简单的公式,这应该永远印在一个系统架构师的脑海里:
“One is none and two is one”
一台服务器远远不够为我们提供高可用性。每个系统需要一个备份系统,它可以在非常紧急的情况下接管过来。仅通过拆分一组数据,我们绝对没有改善可用性,因为我们有较多的服务器可能也在这个时间点出故障。为了解决这个问题,我们可以为我们每个分区(碎片)增加副本,正如下图所示:
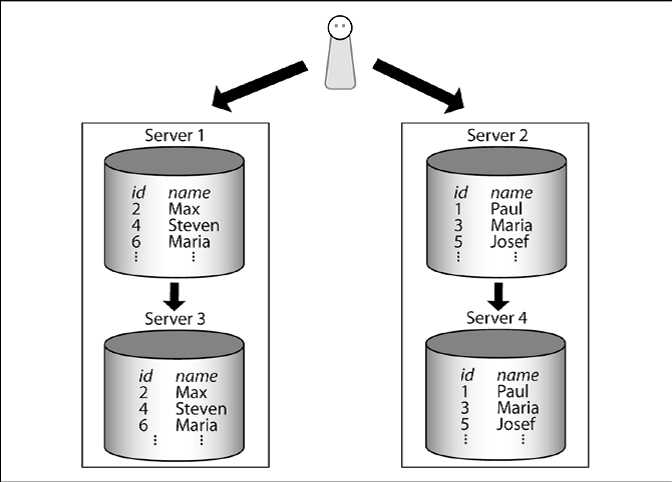
每个分区是一个独立的PostgreSQL数据库实例,每个实例有它自己的副本(或多个副本)。
请记住,您可以从全部武器特性和本书中所讨论的特性(例如,同步和异步复制)选择。本书中所介绍的所有策略可以灵活地组合;单一的技术通常是不够的,因此要以不同的方式自由组合各种技术来实现您目标。
近几年,分片已经作为一种工业标准融入到许多可扩展性相关的问题。因此,许多编程语言,框架和产品已经提供了即插即用来支持拆分。
实现分片时,您基本上可以在两种策略之间进行选择:
•依靠一些框架/中间件
•依靠PostgreSQL方法解决问题
在接下来的两节中,我们将简要讨论这两个选择。这个小概述并不意味着一个全面的指南,而是一个让您开始分片的概括。
基于PostgreSQL的分片
PostgreSQL本身不能对数据进行分片,但是它有通过附加组件来实现分片所有的接口和方法。其中的一个被广泛使用的附加组件是PL/Proxy。它已经存在好多年了,并提供卓越透明度以及良好的扩展性。
PL/Proxy背后的思想基本上是使用一个本地虚拟表隐藏一个服务器组组成的表。
PL/Proxy将在第十三章进行深入地讨论,使用PL/Proxy扩展。
外部框架/中间件
您也可以使用外部工具来替代依靠PostgreSQL。一些使用的最广泛和知名的工具是:
• Hibernate shards (Java)
• Rails (Ruby)
• SQLAlchemy (Python)
本章,您已经了解了基本的复制相关的概念,以及有关物理限制。我们已经处理了理论概念,这是基础的东西,在本书的后面仍然会出现。
下一章,您将通过PostgreSQL事务日志的指导,我们将概述这一重要组成部分的所有重要方面。您将学会事物日志对什么是有益的,它是如何被应用的。
PostgreSQL Replication之第一章 理解复制概念(3)
标签:
原文地址:http://www.cnblogs.com/songyuejie/p/4743307.html