标签:
本系列会分析 OpenStack 的高可用性(HA)解决方案:
(1)概述 (写着中...)
(2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议)
(3)Neutron L3 Agent HA - DVR (分布式虚机路由器)
Pacemaker 承担集群资源管理者(CRM - Cluster Resource Manager)的角色,它是一款开源的高可用资源管理软件,适合各种大小集群。Pacemaker 由 Novell 支持,SLES HAE 就是用 Pacemaker 来管理集群,并且 Pacemaker 得到了来自Redhat,Linbit等公司的支持。它用资源级别的监测和恢复来保证集群服务(aka. 资源)的最大可用性。它可以用基础组件(Corosync 或者是Heartbeat)来实现集群中各成员之间的通信和关系管理。它包含以下的关键特性:
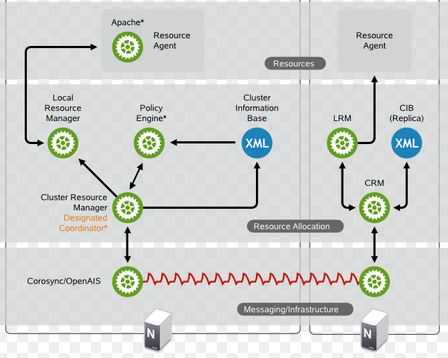
Pacemaker 软件架构:
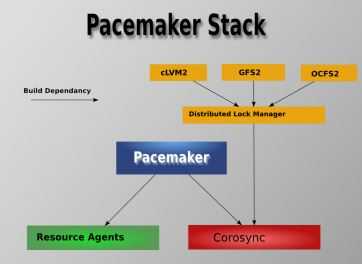
Pacemaker 支持多种类型的集群,包括 Active/Active, Active/Passive, N+1, N+M, N-to-1 and N-to-N 等。
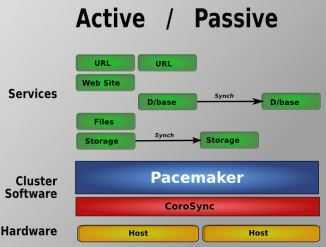
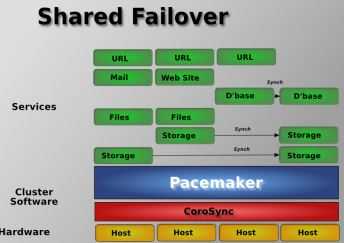
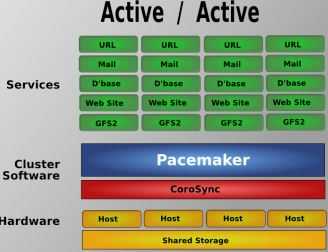
这里 有详细的 Pacemaker 安装方法。这是 中文版。这篇文章 提到了 Pacemaker 的一些问题和替代方案。
Corosync 用于高可用环境中提供通讯服务,位于高可用集群架构中的底层,扮演着为各节点(node)之间提供心跳信息传递这样的一个角色。Pacemaker 位于 HA 集群架构中资源管理、资源代理这么个层次,它本身不提供底层心跳信息传递的功能,它要想与对方节点通信就需要借助底层的心跳传递服务,将信息通告给对方。
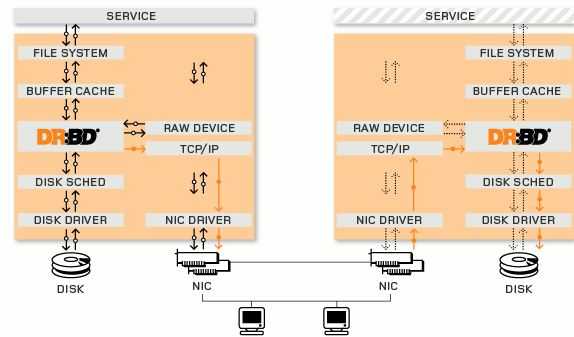
关于心跳的基本概念:
这篇文章 详细介绍了其原理。
RabbitMQ A/P HA 官方方案 是采用 Pacemaker + (DRBD 或者其它可靠的共享 NAS/SNA 存储) + (CoroSync 或者 Heartbeat 或者 OpenAIS)组合来实现的。需要注意的是 CoroSync 需要使用多播,而多播在某些云环境中是被禁用的,这时候可以改为使用 Heartbeat,它采用单播。其架构为:

实现 HA 的原理:
RabbitMQ 官方的 这篇文章介绍了基于 Pacemaker 的 RabbitMQ HA 方案。它同时指出,这是传统的 RabbitMQ HA 方案,并且建议使用 RabbitMQ 集群 + 镜像 Message Queue 的方式来实现 A/A HA。使用 Pacemaker 实现 HA 的方案主要步骤包括:
为 RabbitMQ 配置一个 DRBD 设备
配置 RabbitMQ 使用建立在 DRBD 设备之上的数据目录
选择并绑定一个可以在各集群节点之间迁移的虚拟 IP 地址 (即 VIP )
配置 RabbitMQ 监听该 IP 地址
使用 Pacemaker 管理上述所有资源,包括 RabbitMQ 守护进程本身
本配置使用两个节点。
首先,在两个节点上安装软件包:apt-get install pacemaker crmsh corosync cluster-glue resource-agents,并配置 Corosync,设它为 boot 自启动:vi /etc/default/corosync,START=yes。
两个节点上,
(1)修改配置文件:vim /etc/corosync/corosync.conf
totem { #... interface { ringnumber: 0 bindnetaddr: #节点1上,192.168.1.15;节点2上,192.168.1.32 broadcast: yes mcastport: 5405 } transport: udpu } nodelist { node { ring0_addr: 192.168.1.15 nodeid: 1 } node { ring0_addr: 192.168.1.32 nodeid: 2 } }
(2)启动服务 service corosync start
(3)查看状态
root@compute2:/home/s1# corosync-cfgtool -s
Printing ring status.
Local node ID 2
RING ID 0
id = 192.168.1.32
status = ring 0 active with no faults
root@compute2:/home/s1# corosync-cmapctl runtime.totem.pg.mrp.srp.members #需要确保两个节点都加入了组
runtime.totem.pg.mrp.srp.members.1.config_version (u64) = 0
runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(192.168.1.15)
runtime.totem.pg.mrp.srp.members.1.join_count (u32) = 1
runtime.totem.pg.mrp.srp.members.1.status (str) = joined
runtime.totem.pg.mrp.srp.members.2.config_version (u64) = 0
runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(192.168.1.32)
runtime.totem.pg.mrp.srp.members.2.join_count (u32) = 1
runtime.totem.pg.mrp.srp.members.2.status (str) = joined
(4)启动 pacemaker:service pacemaker start
(5)查看 pacemaker 状态:crm_mon
Last updated: Sun Aug 16 15:59:10 2015 Last change: Sun Aug 16 15:58:59 2015 via crmd on compute1 Stack: corosync Current DC: compute1 (1) - partition with quorum Version: 1.1.10-42f2063 3 Nodes configured 0 Resources configured Node compute1 (1084752143): UNCLEAN (offline) Online: [ compute1 compute2 ]
(6)配置 pacemaker
root@compute2:/home/s1# crm crm(live)# configure crm(live)configure# property no-quorum-policy="ignore" \ #因为这里只有两个节点,因此需要设置为 ‘ignore’。两个节点以上,不可以设置为 ‘ignore’ > pe-warn-series-max="1000" > pe-input-series-max="1000" > pe-error-series-max="1000" > cluster-recheck-interval="2min" crm(live)configure# quit There are changes pending. Do you want to commit them? yes bye
在 node1 和 node2 上,依次进行:
(0)安装 DRBD,并设置机器启动时 DRBD 服务不自动启动。该服务的启停升降机等都需要由 Pacemaker 控制。
(1)添加一个 1G 的 hard disk,fdiskl -l 可见 /dev/sdb
(2)创建 LVM:pvcreate /dev/sdb,vgcreate vg_rabbit /dev/sdb,lvcreate -L1000 -n rabbit vg_rabbit。创建好的 LVM 为 /dev/mapper/vg_rabbit-rabbit。
(3)定义 rabbitmq 资源:vi /etc/drbd.d/rabbitmq.res
根据 /etc/drbd.conf,资源的配置文件需要放置在 /etc/drbd.d/ 目录中,并以 res 为文件类型。DRBD 会自动读取这些配置文件并创建相应的资源。
rource rabbitmq { device minor 1; # DRBD device 是 /dev/drbd1,相当于 device /dev/drbd1 disk "/dev/mapper/vg_rabbit-rabbit"; # Raw device, 本例中是 LVM path。也可以使用不同名字的 Raw device,这样的话需要放到 host 定义部分。 meta-disk internal; # 这是默认值,更多信息可以参考这个 on compute1 { # 节点1,名称需要与 uname -n 的输出相同。 address ipv4 192.168.1.15:7701; #7701 是 DRBD 通信的 TCP 端口,需要确保该端口可以被访问 } on compute2 { # 节点2 address ipv4 192.168.1.32:7701; } }
(4)drbdadm create-md rabbitmq
root@compute2:/home/s1# drbdadm create-md rabbitmq
Writing meta data...
initializing activity log
NOT initializing bitmap
New drbd meta data block successfully created.
(5)drbdadm up rabbitmq
在 compute 2 上,
(1)drbdadm -- --force primary rabbitmq
(2)mkfs -t xfs /dev/drbd1 (如果提示 mkfs.xsf 找不到,则 sudo apt-get install xfsprogs)
meta-data=/dev/drbd1 isize=256 agcount=4, agsize=63996 blks = sectsz=512 attr=2, projid32bit=0 data = bsize=4096 blocks=255983, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 log =internal log bsize=4096 blocks=1200, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0
(3)mount /dev/drbd1 /var/lib/rabbitmq
(4)umount /var/lib/rabbitmq
(3)drbdadm secondary rabbitmq
在 compute 1 上:
至此,DRBD 设置完成,目前 compute 1 上的 DRBD 是主,compute 2 上的是备。查看其状态:
root@compute1:/home/s1# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.3 (api:1/proto:86-101) srcversion: 6551AD2C98F533733BE558C m:res cs ro ds p mounted fstype 1:rabbitmq Connected Primary/Secondary UpToDate/UpToDate C /var/lib/rabbitmq xfs root@compute2:/home/s1# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.3 (api:1/proto:86-101) srcversion: 6551AD2C98F533733BE558C m:res cs ro ds p mounted fstype 1:rabbitmq Connected Secondary/Primary UpToDate/UpToDate C
调试时遇到一个脑裂问题,就是两个node上 drbd 的状态都是 StandAlone,然后 DRBD 服务在 compute 2 上能起来,在 compute 1 上起不来。
root@compute1:/home/s1# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.3 (api:1/proto:86-101) srcversion: 6551AD2C98F533733BE558C m:res cs ro ds p mounted fstype 1:rabbitmq StandAlone Secondary/Unknown UpToDate/DUnknown r----- DRBD‘s startup script waits for the peer node(s) to appear. - In case this node was already a degraded cluster before the reboot the timeout is 0 seconds. [degr-wfc-timeout] - If the peer was available before the reboot the timeout will expire after 0 seconds. [wfc-timeout] (These values are for resource ‘rabbitmq‘; 0 sec -> wait forever) To abort waiting enter ‘yes‘ [ 148]:
SUSE 有关于 DRBD 安装、配置和测试的 不错的文档 。
(1)在两个节点上安装 RabbitMQ。rabbitmq-server 进程会在 rabbitmq 组内的 rabbitmq 用户下运行。
(2)确保 rabbitmq 组和用户在两个节点上具有相同的 ID。运行 cat /etc/passwd | grep rabbitmq 和 cat /etc/group | grep rabbitmq 查看 ID,必要时进行修改。
(3)确保 rabbitmq 用户对 /var/lib/rabbitmq/ 有读写权限。 运行 chmod a+w /var/lib/rabbitmq/。
(4)确保各节点都使用相同的 Erlang cookie。需要将 compute 1 上的 RabbitMQ cookie 拷贝到 compute 2 上:
(1)compute 1:scp /var/lib/rabbitmq/.erlang.cookie s1@compute2:/home/s1
(2)compute 2:mv .erlang.cookie /var/lib/rabbitmq/
(3)compute 2:chown rabbitmq: /var/lib/rabbitmq/.erlang.cookie
(4)compute 2:chmod 400 /var/lib/rabbitmq/.erlang.cookie
(5)再执行相同的步骤,将该文件拷贝到 DRBD 共享存储文件系统中
(5)确保计算机启动时不自动启动 rabbitmq。修改 /etc/init.d/rabbitmq-server 文件,在文件头注释后面添加 exit 0.
在添加前,在 compute 1 节点上,运行 crm configure,输入:
primitive p_ip_rabbitmq ocf:heartbeat:IPaddr2 \ #定义访问 RabbitMQ 的 VIP。使用 RA ocf:heartbeat:IPaddr2。对该 VIP 的监控间隔为 10s。 params ip="192.168.1.222" cidr_netmask="24" op monitor interval="10s" primitive p_drbd_rabbitmq ocf:linbit:drbd \ #定义RabbitMQ 的 DRBD 资源,pacemaker 会对它 start,stop,promote,demote 和 monitor。 params drbd_resource="rabbitmq" op start timeout="90s" \ #启动的超时时间 op stop timeout="180s" op promote timeout="180s" op demote timeout="180s" op monitor interval="30s" role="Slave" \ #对 Slave drbd 的监控间隔定义为 30s op monitor interval="29s" role="Master" #对 master drbd 的监控间隔定义为 29s primitive p_fs_rabbitmq ocf:heartbeat:Filesystem \ # 在 /dev/drbd1 上创建 xfs 文件系统,并 mount 到 /var/lib/rabbitmq params device="/dev/drbd1" directory="/var/lib/rabbitmq" fstype="xfs" options="relatime" op start timeout="60s" op stop timeout="180s" op monitor interval="60s" timeout="60s" primitive p_rabbitmq ocf:rabbitmq:rabbitmq-server \ #定义 RabbitMQ 资源 params nodename="rabbit@localhost" mnesia_base="/var/lib/rabbitmq" op monitor interval="20s" timeout="10s" group g_rabbitmq p_ip_rabbitmq p_fs_rabbitmq p_rabbitmq #group 指定一组资源需要在同一个node上 ip -> fs -> rabbitmq,顺序启动,逆序停止 ms ms_drbd_rabbitmq p_drbd_rabbitmq meta notify="true" master-max="1" clone-max="2" # 定义一个资源集合,往往用于 master-slave 资源集群。其中,clone-max 定义集合内的 drbd 节点数目,master-max 指定 master 最多只能有一个;notify = “true” 表示启用notification。 colocation c_rabbitmq_on_drbd inf: g_rabbitmq ms_drbd_rabbitmq:Master #colocation 定义在同一个节点上启动的资源。这里定义了一个约束,rabbitmq 只能在 DRBD Master 节点上启动 order o_drbd_before_rabbitmq inf: ms_drbd_rabbitmq:promote g_rabbitmq:start #oder 指定服务启动顺序。这个定义要求先 DRBD 升级为 Master 然后依次执行 ip,fs 和 rabbitmq 启动。
更多的 Pacemaker 配置细节,请参考 这个文档。
Pacemaker 一些有用的命令:
配置完成后,RabbitMQ 起不来。一堆问题,挨个来说:
(1)Corosync 调试:设置日志文件
logging { fileline: off to_stderr: yes to_logfile: yes to_syslog: yes logfile: /var/log/cluster/corosync.log syslog_facility: daemon debug: off timestamp: on }
(2)pacemaker 调试:pacemaker 的日志在 corosync 的 log file 中。
(3)运行 crm status,如果出现 Could not establish cib_ro connection: Connection refused (111) ,原因是 pacemaker 服务没有启动。运行 service pacemaker start 即可。
(4)rabbitmq 启动的错误日志可以在 /var/log/rabbitmq 目录下找到。可能的错误之一是,rabbit 用户没有目录 /var/lib/rabbitmq 的写权限。
成功后,是这样的效果:
root@compute2:/var/lib/rabbitmq/rabbit@localhost# crm status Last updated: Mon Aug 17 00:16:11 2015 Last change: Sun Aug 16 22:54:27 2015 via cibadmin on compute1 Stack: corosync Current DC: compute1 (1) - partition with quorum Version: 1.1.10-42f2063 3 Nodes configured 5 Resources configured Online: [ compute1 compute2 ] # pacemaker 集群中有两个节点 OFFLINE: [ compute1 ] # compute 1 是备节点 Resource Group: g_rabbitmq p_ip_rabbitmq (ocf::heartbeat:IPaddr2): Started compute2 #在 compute 2 上启动 VIP,成功 p_rabbitmq (ocf::rabbitmq:rabbitmq-server): Started compute2 #在 compute 2 上启动 rabbitmq,成功 Master/Slave Set: ms_drbd_rabbitmq [p_drbd_rabbitmq] Masters: [ compute2 ] Slaves: [ compute1 ] p_fs_rabbitmq (ocf::heartbeat:Filesystem): Started compute2 # 在 compute 2 上设置 drbd 文件系统,成功
可见,根据配置,pacemaker 会(1)根据 corosync 确定集群中的节点和状态 (2)启动 VIP (3)启动指定的服务 (4)设置 DRBD 文件系统。每一步都可能失败,失败则需要调试。
(5)将主节点停机,rabbitmq 服务顺利地被切换到备节点上。
RabbitMQ 自身实现了集群功能。官方文档在这里。基于该功能,就可以实现RabbitMQ Active/Active 模式的HA:当 master 挂掉了,按照策略选择某个slave (其实就是最先加入集群的那个slave)来担当master的角色。多个单独的 RabbitMQ 服务,可以加入到一个集群中,也可以从集群中退出。集群中的 RabbitMQ 服务,使用同样的 Erlang cookie(unix 系统上默认为 /var/lib/rabbitmq/.erlang.cookie)。所有在一个 RabbitMQ 服务中被操作的数据和状态(date/state)都会被同步到集群中的其它节点。只有 message queue 是例外,它默认只会保存到创建它的节点上,但是 这篇文章 介绍了从 3.3 版本开始,RabbitMQ 加入了 message queue 镜像的支持。这样,使用 RabbitMQ 集群+ 镜像 Message Queue 就可以实现一个完整的 A/A HA 了。
使用这种模式的 RabbitMQ,客户端象正常情况下一样,连接集群中的某个 RabbitMQ 服务。当该服务 down 掉后,客户端需要能感知到它和该服务之间的连接被中断了,然后自动连接集群中其它运行着的节点。这就需要 OpenStack 使用 RabbitMQ 的各组件也支持这种模式。目前,支持高可用 RabbitMQ 服务的 OpenStack 组件有:
除了在 OpenStack 各服务中配置多个 RabbitMQ 节点外,还可以使用 HAProxy 来提供一个 VIP 供各 OpenStack 服务使用。但是这又会涉及到 HAProxy 的 HA 问题。
和使用 Pacemaker 实现的 A/P HA 相比,这种方式是更优的方案,因为(1)它是 RabbitMQ 和 OpenStack 原生支持的,不需要使用别的软件 (2)A/A 的切换时间比 A/P 更短。但是,A/A 这种 HA 模式,仁者见仁智者见智,很多人说这是坑。
具体的配置可以参考 这篇文章 以及 OpenStack 官网,以及 RabbitMQ 官网。
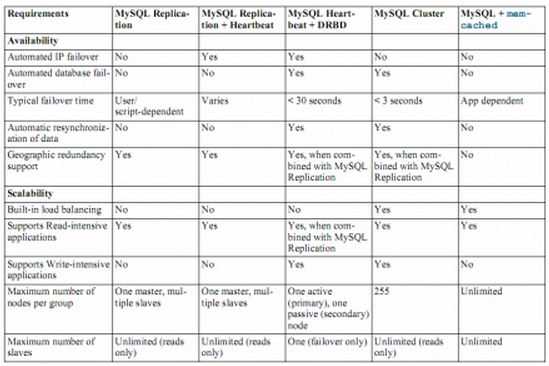
Mysql HA 方案有很多种,包括:
这里 有个各种方案的比较:
与 RabbitMQ HA 方案类似,OpenStack 官方推荐的 Mysql Active/Passive HA 方案也是 Pacemaker + DRBD + CoroSync。具体方案为:
OpenStack 官方推荐的 Mysql HA A/P 方案 配置完成后的效果:
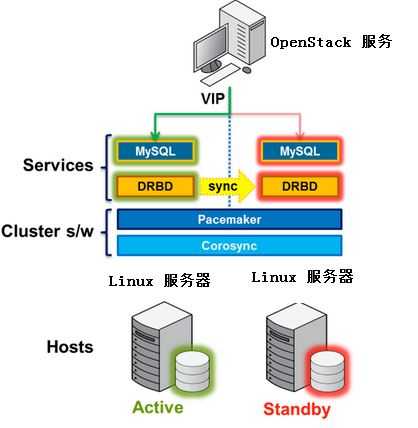
因为与 RabbitMQ HA 方案非常类似,不再赘述。这个文档 详细阐述了具体的配置步骤。
OpenStack 官方的推荐是使用 Galera 来做 A/A HA。这种模式下,Galera 提供多个 Mysql 节点之间的同步复制,使得多个 Mysql 节点同时对外提供服务,这时候往往需要使用负载均衡软件来提供一个 VIP 给各应用使用。官网 在这里。
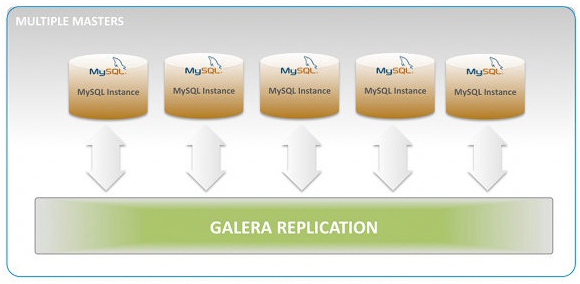
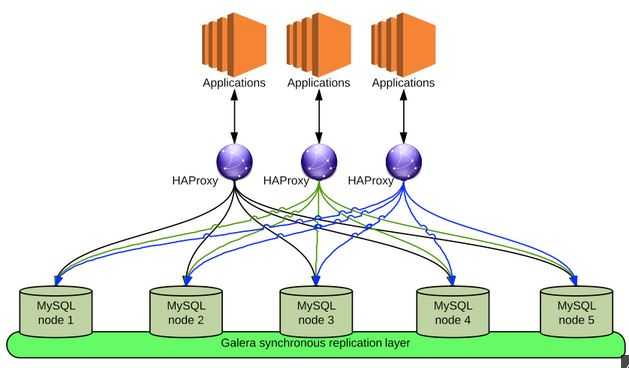
Galera 主要功能:
优势:
技术:
详细配置过程可以参考 OpenStack HA Guide 和 这个文章。
参考链接:
理解 OpenStack 高可用(HA)(4):RabbitMQ 和 Mysql HA
标签:
原文地址:http://www.cnblogs.com/sammyliu/p/4730517.html