今天发布了新小组的第一个任务,这个任务是统计销售一段时间的数据,统计完成后再序列化存入到数据库一个text字段。当统计线上全部的销售时,因为线上有离职销售,所以统计出来的数据量就超过了text字段长度(65535),导致数据没有存放下。 后来和组长讨论了下,打算将离职销售全部归为一类,展示,那样销售 ...
分类:
数据库 时间:
2020-01-07 22:45:57
阅读次数:
190
rollup 和 cube group by 生成数据结果时,只会生成相关列的数据统计信息,而不是生成小计和总计 group by统计结果如下(不是select直接返回格式): SQL> select deptno,job,avg(sal) from emp group by deptno,job; ...
分类:
数据库 时间:
2020-01-04 18:57:32
阅读次数:
144
今天来说一下使用sql统计数据。 用的H2数据库,用的是DBeaver连接工具。有三表,打印表PRINT_JOB,复印表COPY_JOB和扫描表SCANNER_JOB (这段可以忽略)任务是要统计相同的SERIAL_NUMBER下三张表数据的,但是有要求三张表的SERIAL_NUMBER只要其中有一 ...
分类:
数据库 时间:
2019-12-31 12:20:17
阅读次数:
149
1 import numpy as np 2 3 # 创建一个数组 4 arr = np.array([[1, 2],[3, 4]]) 5 print("arr: \n", arr) 6 7 # 对数组进行统计分析 8 # sum mean std var min max argmin argmax ...
分类:
编程语言 时间:
2019-12-29 18:50:55
阅读次数:
90
下面介绍了这些工具的主要功能以及教程、书籍、视频等。 端口扫描器:Nmap Nmap是"Network Mapper"的缩写,众所周知,它是一款非常受欢迎的免费开源黑客工具。Nmap被用于发现网络和安全审计。据数据统计,全世界成千上万的系统管理员使用nmap发现网络、检查开放端口、管理服务升级计划, ...
分类:
其他好文 时间:
2019-12-29 16:32:57
阅读次数:
135
1. 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计。 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hive分析数 ...
分类:
其他好文 时间:
2019-12-27 13:08:13
阅读次数:
92
流数据的窗口操作:窗口操作,即把几个批次的数据整合到一个窗口里计算,并且窗口根据步长不断滑动。 本质:把小批次,小颗粒的数据任意进行大批次和大颗粒的数据统计,意味着批次采集周期不用设置太大,可以通过滑动窗口来调整数据出现的粒度。 code: package com.home.spark.stream ...
分类:
其他好文 时间:
2019-12-25 17:36:28
阅读次数:
93
背景消息报表主要用于统计消息任务的下发情况。比如,单条推送消息下发APP用户总量有多少,成功推送到手机的数量有多少,又有多少APP用户点击了弹窗通知并打开APP等。通过消息报表,我们可以很直观地看到消息推送的流转情况、消息下发到达成功率、用户对消息的点击情况等。个推在提供消息推送服务时,为了更好地了解每天的推送情况,会从不同的维度进行数据统计,生成消息报表。个推每天下发的消息推送数巨大,可以达到数
分类:
其他好文 时间:
2019-12-23 10:21:46
阅读次数:
286
什么是Hive Hive是由Facebook开源用于解决海量结构化日志的数据统计;Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射 成一张表,并提供类SQL查询功能,底层计算引擎默认为Hadoop的MapReduce(本质是将sql转化成mapreduce程序),可以将引擎更 ...
分类:
其他好文 时间:
2019-12-14 15:25:15
阅读次数:
129
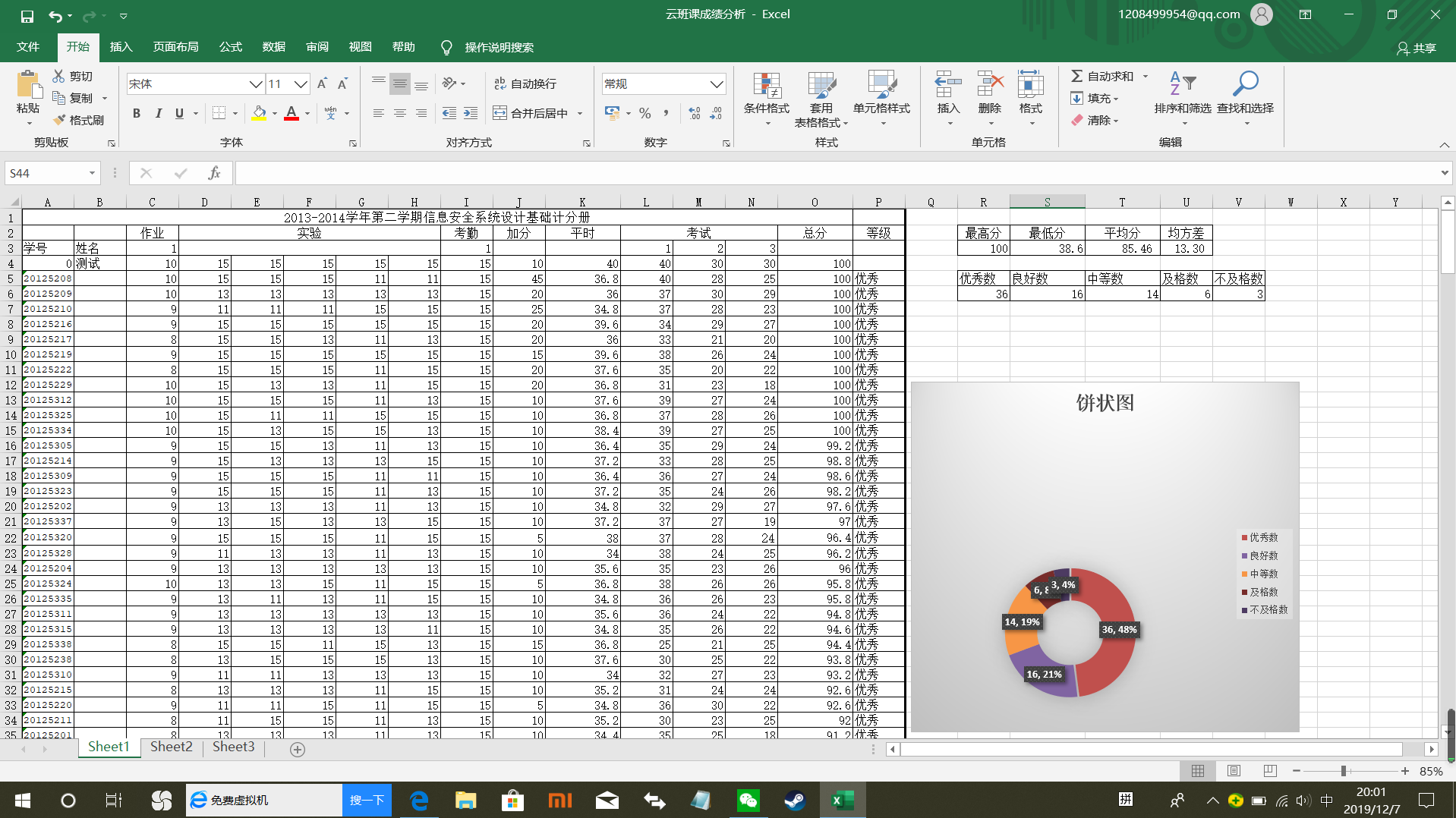 ![](https://img2018.cnblogs.com/blog/1812314/201912/18123... ...
分类:
其他好文 时间:
2019-12-07 21:36:56
阅读次数:
80