标签:
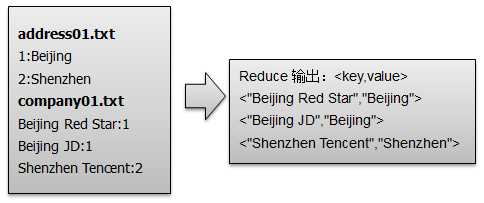
问题描述:两种类型输入文件:address类(地址)和company类(公司)进行一对多的关联查询,得到地址名(例如:Beijing)与公司名(例如:Beijing JD、Beijing Red Star)的关联信息。
1.map阶段:对比于前者的单表关联可知,reduce阶段的key必须为关联两表的key,即address.Id = company.Id。则两表经过map处理输出的key必须是Id。
Class Map<LongWritable, Text, LongWritable, Text>{ method map(){ // 获取文件的每一行数据,并以":"分割 String[] line = value.toString().split(":"); //split对应的文件名 String fileName = ((FileSplit) context.getInputSplit()).getPath().getName(); //处理company文件的value信息:"Beijing Red Star:1" if (path.indexOf("company") >= 0){ //<key,value> --<"1","company:Beijing Red Star"> context.write(new LongWritable(line[1]), new Text("company" + ":" + line[0])); } //处理adress文件的value信息:"1:Beijing" else if (path.indexOf("address") >= 0){ //<key,value> --<"1","address:Beijing"> context.write(new LongWritable(line[0]), new Text("address" + ":" + line[1])); } } }
2.reduce阶段:首先对输入<key, values>即<”1”,[“company:Beijing Red Star”,”company:Beijing JD”,”address:Beijing”]>的values值进行遍历获取到单元信息value(例如”company:Beijing Red Star”),然后根据value中的标识符(company和address)将公司名和地址名分别存入到company集合和address集合,最后对company集合和address集合进行笛卡尔积运算得到company与address的关系,并进行输出。
Class Reducer<LongWritable, Text, Text, Text>{ method reduce(){ //用来存储 company 和 address 的集合 List<String> companys = new ArrayList<String>(); List<String> addresses = new ArrayList<String>(); for(Text text : v2s){ String[] result = text.toString().split(":"); //以 company 开头的value存储到 company 集合中 if(result[0].equals("company")){ companys.add(result[1]); } //以 address 开头的value存储到 address 集合中 else if(result[0].equals("address")){ addresses.add(result[1]); } } // 求笛卡尔积 if(0 != companys.size()&& 0 != addresses.size()){ for(int i=0;i<companys.size();i++){ for(int j=0;j<addresses.size();j++){ //<key,value>--<"Beijing JD","Beijing"> context.write(new Text(companys.get(i)), new Text(addresses.get(j))); } } } } }
标签:
原文地址:http://www.cnblogs.com/skyl/p/4746005.html