标签:
分组统计数据集是很常见的需求,R中也有相应的包支持数据集的分组统计。自己尝试了写了段R代码来完成分组统计数据集,支持公式,感觉用起来还算方便。代码分享在文章最后。
使用方式:
step 1: source(‘AggregateSummary.R‘)
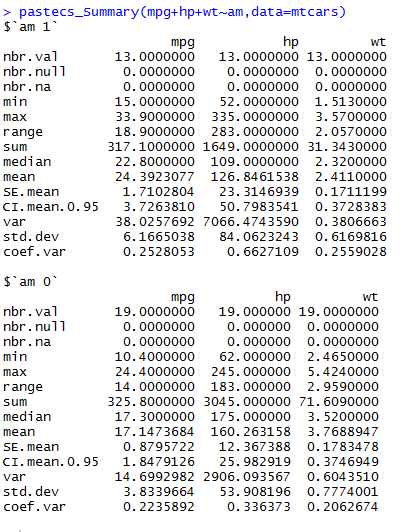
step 2: pastecs_summary(mpg+hp+wt~am,data=mtcars)
执行结果如下:
AggregateSummary.R的源码:
library(plyr)
library(stringr)
library(pastecs)
parseformula <- function(formula = "... ~ variable", varnames, value.var = "value") {
remove.placeholder <- function(x) x[x != "."]
replace.remainder <- function(x) {
if (any(x == "...")) c(x[x != "..."], remainder) else x
}
if (is.formula(formula)) {
formula <- str_c(deparse(formula, 500), collapse = "")
}
if (is.character(formula)) {
dims <- str_split(formula, fixed("~"))[[1]]
formula <- lapply(str_split(dims, "[+*]"), str_trim)
formula <- lapply(formula, remove.placeholder)
all_vars <- unlist(formula)
if (any(all_vars == "...")) {
remainder <- setdiff(varnames, c(all_vars, value.var))
formula <- lapply(formula, replace.remainder)
}
}
if (!is.list(formula)) {
stop("Don‘t know how to parse", formula, call. = FALSE)
}
lapply(formula, as.quoted)
}
evalFormula <- function(formula,data){
fo<-parseformula(formula)
lapply(fo,eval.quoted,envir=data)
}
pastecs_Summary<- function(formula,data){
tmplist<-evalFormula(formula,data)
df1<-as.data.frame(tmplist[1])
uni<-unique(tmplist[[2]][[1]])
lst<-list()
for(i in uni){
lst[[paste(names(tmplist[[2]]),i)]]<-stat.desc(df1[which(tmplist[[2]][[1]]==i),])
}
return(lst)
}
标签:
原文地址:http://www.cnblogs.com/1zhk/p/4746362.html