标签:
DMA是AMBA的先进高性能总线(AHB)上的设备,它有2个AHB端口:
一个是从端口,用于配置DMA,另一个是主端口,使得DMA可以在不同的从设备之间传输数据。
DMA的作用是在没有Cortex-M3核心的干预下,在后台完成数据传输。
在传输数据的过程中,主处理器可以执行其它任务,只有在整个数据块传输结束后,
需要处理这些数据时才会中断主处理器的操作。
它可以在对系统性能产生较小影响的情况下,实现大量数据的传输。
DMA主要用来为不同的外设模块实现集中的数据缓冲存储区(通常在系统的SRAM中)。
与分布式的解决方法(每个外设需要实现自己的数据存储)相比,
这种解决方法无论在芯片使用面积还是功耗方面都要更胜一筹。
STM32F10XXX的DMA控制器充分利用了Cortex-M3哈佛架构和多层总线系统的优势,
达到非常低的DMA数据传输延时和CPU响应中断延迟。
DMA具有以下的特性:
DMA旨在为所有外设提供相对较大的数据缓冲区,这些缓冲区一般位于系统的SRAM中。
每一个通道在特定的时间里分配给唯一的外设,连接到同一个DMA通道的外设
(表1中的通道1到通道7)不能够同时使用DMA功能。
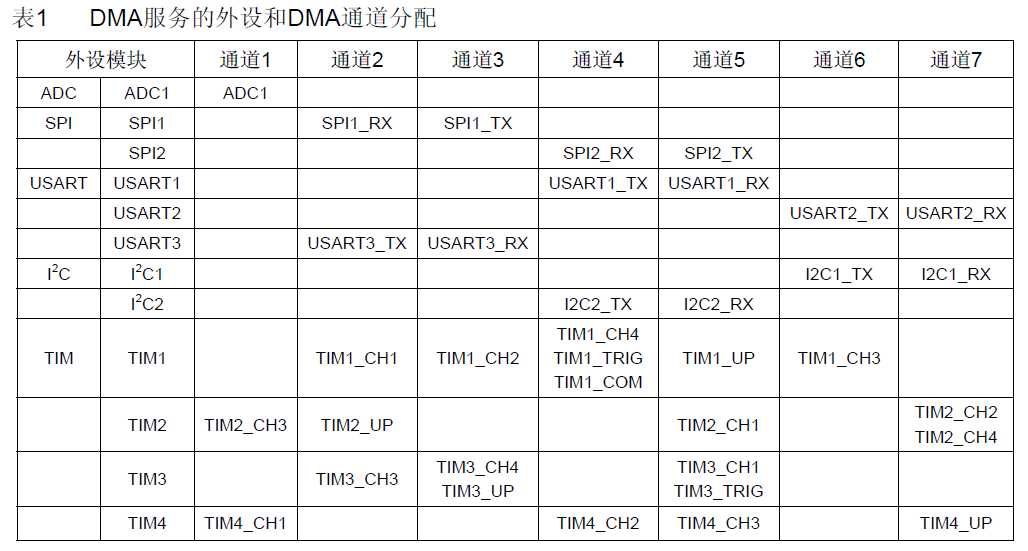
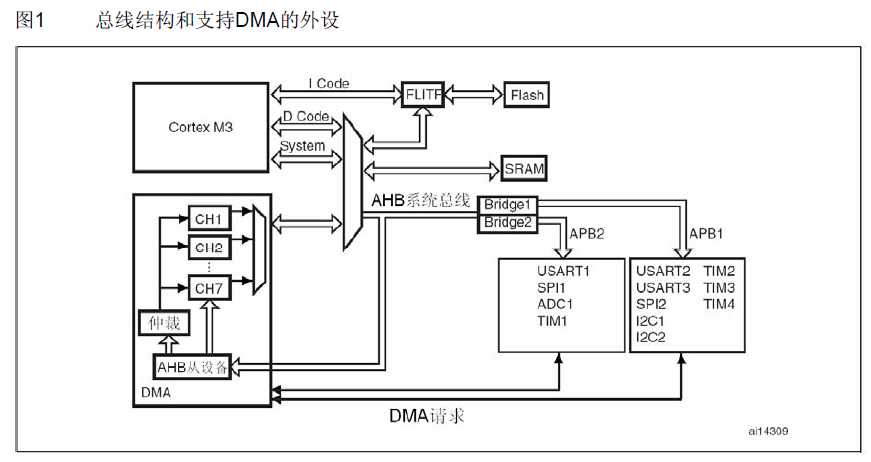
STM32F10xxx有两个主模块——Cortex-M3处理器和DMA。
他们通过总线矩阵连接到从总线、闪存总线、SRAM总线和AHB系统总线。
从总线的另一端连接到两个APB总线,以服务所有的嵌入的外设(参见图1)。
总线矩阵有两个主要的特性,实现系统性能的最大化和减少延时:
●轮询优先级方案
●多层结构和总线挪用
NVIC和Cortex-M3处理器实现了高性能低延时中断方案。
所有的Cortex-M3指令都或者是单周期执行指令,或者可以在总线周期级上被中断。
为了在系统层面上保持这个优点,DMA和总线矩阵必须确保DMA不能够长时间占用总线。
轮询优先级方案能够确保,如有必要,CPU能够每两个总线周期就去访问其它从总线。
因此,在CPU看来第一个数据的最大总线系统延时,就是一个总线周期(最大两个APB时钟周期)。
多层结构允许两个主设备同时执行数据传输,只要他们寻址到不同的从模块。
在Cortex-M3哈佛架构基础上,这种多层结构提高了数据的并行性,
因此减少了代码执行时间并且优化了DMA效率。
由于从Flash存储器取指是通过完全独立的总线,
所以DMA和CPU只是在需要通过同一个从总线进行数据访问时才会产生竞争。
另外,在其它DMA控制器工作于突发模式时,STM32F10xxx的DMA数据传输只使用单个总线周期(总线挪用)。
使用总线挪用存取机制时,CPU进行数据访问所等待的最大时间是很短的(一个总线周期) 。
通常,CPU对SRAM的访问是与DMA操作交替地进行,CPU访问SRAM的同时DMA就在通过APB总线访问外设。
尽管使用DMA的突发模式可以提高(DMA访问外设)数据传输速度,
但不可避免地是CPU的执行速度被拖慢。下图显示了总线挪用和突发机制的区别。
图2 DMA传输的总线挪用机制和突发机制
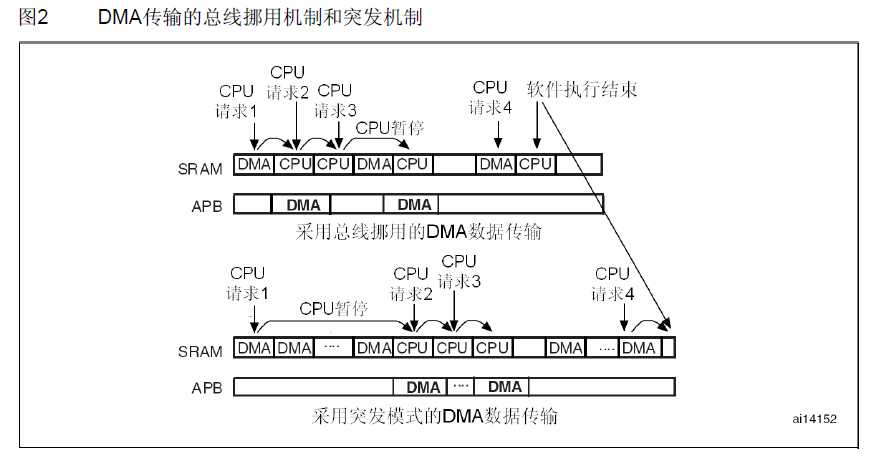
极端的情况发生在CPU从内存的一个地方复制一块数据到内存中的另一个地方。
这种情况下,软件的执行须等到整个DMA传输完毕才能进行。
实际上,CPU大部分时间是在做数据处理(寄存器的读/写),
比较少地进行数据访问,因此CPU和DMA对数据的存取还算是交替进行着。
STM32F10xxx总线结构固有的并行性,加上DMA总线挪用机制,
保证了CPU不会长时间地等待从SRAM中读取数据。
采用总线挪用机制的DMA因此能够更高效地使用总线,从而显著地减少了软件执行的时间。
DMA完成从外设到SRAM存储器的数据传输有三个步骤:
当DMA把数据从内存中传输到外设(例如SPI传送),操作步骤如下:
服务每个DMA通道的总时间,
tS = tA + tACC + tSRAM 这里,
tA是仲裁时间, tA = 1个AHB时钟周期
tACC是访问外设时间, tACC = 1个AHB时钟周期(总线矩阵仲裁) + 2个APB时钟周期(实际的数据传输) + 1个AHB时钟周期(总线同步)
tSRAM是读写SRAM的时间, tSRAM = 1个AHB时钟周期(总线矩阵仲裁) + 1个AHB时钟周期(单一的读/写操作) 或者 + 2个AHB时钟周期(先读SRAM再写SRAM的情况)
当DMA通道空闲或者是前一个DMA通道的第3步操作完成后,DMA控制器比较所有挂起的DMA请求的优先级
(先比较软件优先级;软件优先级相同时,再比较硬件优先级),
高优先级的通道将会被服务,DMA开始执行第2步操作。
当一个通道正在服务时(第2、3步操作正在进行),没有其他的通道能够被服务,不管它的优先级如何。
当至少同时使能了两个DMA通道时,最高优先级通道的DMA延迟时间为正在传输的时间(不包括仲裁阶段),
加上下个将被服务的DMA通道(挂起优先级最高的通道)数据传输的时间。
数据总线带宽限制主要是因为APB总线比系统SRAM和AHB总线速度慢。
对于最高优先级的DMA通道,必须考虑以下两种情况:(参见图3)
1. 当不止一个DMA通道被使能时,最高优先级的通道在APB总线上占用的数据带宽必须低于APB最高传输率的25%。
APB总线传输的所有时间必须考虑在内,即2个APB时钟周期加上用来仲裁/同步的2个AHB时钟周期。
2. 尽管高速/高优先级DMA传输通常发生在APB2上(更快的APB总线),但是CPU和其他DMA通道可以访问APB1上的外设。
大约3/4的APB传输是在APB1上完成的,最小的APB2频率依赖于最快的DMA通道数据带宽。
最大的APB时钟分频因子由下列的等式给出: fAHB > (2 x N2 + 6 x N1 + 6) x Bmax
如果 N2 < N1 则 N1 < (fAHB/ Bmax)/8 其中fAHB是AHB时钟频率, N1和N2分别是APB1和APB2的时钟分频因子, Bmax是APB2上的最大数据带宽,单位为传输次数/秒。
图3 DMA传输过程中APB总线的占用情况
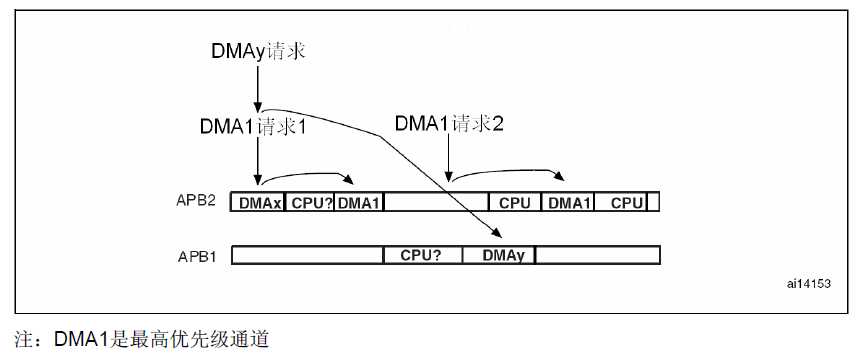
为了实现外设数据的连续传输,相关的DMA通道必须能够维持外设数据传输率,
确保DMA服务的延迟时间少于连续两个外设数据的时间间隔。
高速/高带宽外设必须拥有最高的DMA优先级,
这确保了最大的数据延迟对于这些外设都是可以忍受的,而且可以避免溢出和下溢的情况。
在相同带宽需求的情况下,推荐给工作在从模式下(不能对数据传输速度进行控制)的外设分配较高的优先级,
工作在主模式(能够控制数据流)下的外设分配相对低的优先级。
默认情况下,通道和硬件优先级(从1到7)的分配,
是按照最快的外设分配最高优先级的顺序来分配的。
当然,在某些运用场合下也许这种分配并不适用;
此时,用户可以为每一个通道配置软件优先级(分4种,从非常高到低),
软件优先级优先于硬件优先级。
当同时使用几个外设(不管有没有使用DMA)时,用户必须确保内部系统能够维持应用所要求的总数据带宽,
必须权衡以下两个因素,找到一个折中方案:
以SPI接口为例,SPI接口数据带宽是通过波特率除以SPI的数据字长度而得到的
(因为数据是一个紧接着下一个传输的)。假设SPI的波特率是18Mbps,
数据是以8位传输的,操作配置在单工模式下,因此,
内部数据带宽需求是2.25M传输/秒;
如果SPI配置为16位模式,则数据带宽将是1.125M传输/秒。
注意: 当使用SPI的16位模式时,同样波特率下,
数据带宽除以2,即只需要1.125M/秒的传输。
强烈推荐,尽可能地使用16位模式,以减少总线占用和功耗。
内部数据带宽依赖于以下两个条件:
推荐DMA对总线的占用保持在2/3以下,这样才能保证一个合理的系统和CPU的性能水平。
这个例子示范了如何将不同的外设用于DMA请求和数据传输,
这个机制允许在没有使用CPU的情况下实现简单的快速并行同步接口。
定时器3和连接到TIM3_TRIG 的DMA通道6,用来实现获取数据的接口。
在GPIO的端口上可以获取16位并行数据。
一个外部时钟信号作用在定时器3的外部触发器输入端,
在外部触发器上升沿,定时器产生一个DMA请求。
由于GPIO数据寄存器地址已设置到DMA通道6的外设地址,
DMA控制器在每一次DMA请求时从GPIO端口读取数据,并把它存储到SRAM的缓冲器中。
This example shows how to use different peripherals for DMA request and data transfer.
This mechanism allows to implement simple fast parallel synchronous interfaces without using the CPU (for example a camera interface).
Timer 3 and DMA1 channel 6 connected to TIM3_TRIG are used to implement this data acquisition interface.
An 16-bit parallel data is available on the GPIO port and an external clock signal applied on the external trigger input of Timer 3.
On the rising edge of the external trigger, the timer generates a DMA request.
As the GPIO data register address is set to DMA1 channel 6 peripheral address,
the DMA controller reads the data from the GPIO port on each DMA request, and stores it into an SRAM buffer.
This example shows how the DMA can be used to acquire data from a GPIO (parallel) port,
synchronised with an (external) clock signal. (for the sake of this demo, the clock is generated by software toggling GPIOA pin 6).
The control of the DMA channel is done through the TIM3 channel 1 (Input Capture Mode) which is using the DMA channel 6.
This is a non standard utilisation of the DMA as the peripheral controlling the DMA request (TIM3) is
neither the source, nor the destination of the DMA data transfer.
Instead, the data source is a GPIO port (PD0-PD15) - programmed in GPIO input mode and
the data destination is a RAM buffer (accessed by the DMA Channel 6 in circular mode)
The TIMCLK frequency is set to 72 MHz, and used in Input Capture/DMA Mode.
The system clock is set to 72MHz.
Hardware and Software environment
- This example runs on STM32F10x High-Density, STM32F10x Medium-Density and STM32F10x Low-Density Devices.
- This example has been tested with STMicroelectronics STM3210B-EVAL evaluation boards
and can be easily tailored to any other supported device and development board.
- STM3210B-EVAL Set-up
- Connect a signal generator on PD.00 to PD.15.
- In the example, the PA.06 (capture clock signal) is driven internally (by SW).
By removing the SW control on this pin (leaving the GPIO in input floating mode), an external clock signal can be used.
Alternativelly, PA.06 may be driven externally (leaving PA.06 in input floating mode - alternate function).
#include "stm32f10x.h" TIM_TimeBaseInitTypeDef TIM_TimeBaseStructure; TIM_ICInitTypeDef TIM_ICInitStructure; DMA_InitTypeDef DMA_InitStructure; __IO uint16_t Parallel_Data_Buffer[ 512 ]; ErrorStatus HSEStartUpStatus; void RCC_Configuration( void ); void GPIO_Configuration( void ); int main( void ) { /* System Clocks Configuration ---------------------------------------------*/ RCC_Configuration( ); /* GPIO Configuration ------------------------------------------------------*/ GPIO_Configuration( ); /* DMA Channel6 Configuration ----------------------------------------------*/ DMA_InitStructure.DMA_PeripheralBaseAddr = (uint32_t) &GPIOD->IDR; DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t) Parallel_Data_Buffer; DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralSRC; DMA_InitStructure.DMA_BufferSize = 512; DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable; DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable; DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord; DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord; DMA_InitStructure.DMA_Mode = DMA_Mode_Circular; DMA_InitStructure.DMA_Priority = DMA_Priority_VeryHigh; DMA_InitStructure.DMA_M2M = DMA_M2M_Disable; DMA_Init( DMA1_Channel6, &DMA_InitStructure ); /* Enable DMA Channel6 */ DMA_Cmd( DMA1_Channel6, ENABLE ); /* TIM3 Configuration ------------------------------------------------------*/ /* TIM3CLK = 72 MHz, Prescaler = 0, TIM3 counter clock = 72 MHz */ /* Time base configuration */ TIM_TimeBaseStructure.TIM_Period = 256; TIM_TimeBaseStructure.TIM_Prescaler = 0; TIM_TimeBaseStructure.TIM_ClockDivision = 0; TIM_TimeBaseStructure.TIM_CounterMode = TIM_CounterMode_Up; TIM_TimeBaseInit( TIM3, &TIM_TimeBaseStructure ); /* Input Capture Mode configuration: Channel1 */ TIM_ICInitStructure.TIM_Channel = TIM_Channel_1; TIM_ICInitStructure.TIM_ICPolarity = TIM_ICPolarity_Rising; TIM_ICInitStructure.TIM_ICSelection = TIM_ICSelection_DirectTI; TIM_ICInitStructure.TIM_ICPrescaler = TIM_ICPSC_DIV1; TIM_ICInitStructure.TIM_ICFilter = 0; TIM_ICInit( TIM3, &TIM_ICInitStructure ); /* Enable TIM3 DMA */ TIM_DMACmd( TIM3, TIM_DMA_CC1, ENABLE ); /* Enable TIM3 counter */ TIM_Cmd( TIM3, ENABLE ); while ( 1 ) { /* Trigger TIM3 IC event => DMA request by toggling PA.06 */ GPIO_ResetBits( GPIOA, GPIO_Pin_6 ); GPIO_SetBits( GPIOA, GPIO_Pin_6 ); } } void RCC_Configuration( void ) { /* RCC system reset(for debug purpose) */ RCC_DeInit( ); /* Enable HSE */ RCC_HSEConfig( RCC_HSE_ON ); /* Wait till HSE is ready */ HSEStartUpStatus = RCC_WaitForHSEStartUp( ); if ( HSEStartUpStatus == SUCCESS ) { /* Enable Prefetch Buffer */ FLASH_PrefetchBufferCmd( FLASH_PrefetchBuffer_Enable ); /* Flash 2 wait state */ FLASH_SetLatency( FLASH_Latency_2 ); /* HCLK = SYSCLK */ RCC_HCLKConfig( RCC_SYSCLK_Div1 ); /* PCLK2 = HCLK */ RCC_PCLK2Config( RCC_HCLK_Div1 ); /* PCLK1 = HCLK/2 */ RCC_PCLK1Config( RCC_HCLK_Div2 ); /* ADCCLK = PCLK2/4 */ RCC_ADCCLKConfig( RCC_PCLK2_Div4 ); /* PLLCLK = 8MHz * 9 = 72 MHz */ RCC_PLLConfig( RCC_PLLSource_HSE_Div1, RCC_PLLMul_9 ); /* Enable PLL */ RCC_PLLCmd( ENABLE ); /* Wait till PLL is ready */ while ( RCC_GetFlagStatus( RCC_FLAG_PLLRDY ) == RESET ) { } /* Select PLL as system clock source */ RCC_SYSCLKConfig( RCC_SYSCLKSource_PLLCLK ); /* Wait till PLL is used as system clock source */ while ( RCC_GetSYSCLKSource( ) != 0x08 ) { } } /* Enable TIM3 clock */ RCC_APB1PeriphClockCmd( RCC_APB1Periph_TIM3, ENABLE ); /* Enable DMA clock */ RCC_AHBPeriphClockCmd( RCC_AHBPeriph_DMA1, ENABLE ); /* GPIOA and GPIOD clock enable */ RCC_APB2PeriphClockCmd( RCC_APB2Periph_GPIOA | RCC_APB2Periph_GPIOD, ENABLE ); } void GPIO_Configuration( void ) { GPIO_InitTypeDef GPIO_InitStructure; /* GPIOA Configuration: PA6 GPIO Output -> TIM3 Channel1 in Input */ GPIO_InitStructure.GPIO_Pin = GPIO_Pin_6; GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP; GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; GPIO_Init( GPIOA, &GPIO_InitStructure ); }

STM32 GPIO fast data transfer with DMA
标签:
原文地址:http://www.cnblogs.com/shangdawei/p/4748426.html