标签:
我们兴奋地宣布,从今天开始,Apache Spark1.5.0的预览数据砖是可用的。我们的用户现在可以选择提供集群与Spark 1.5或先前的火花版本准备好几个点击。
正式,Spark 1.5预计将在数周内公布,和社区所做的QA测试的版本。鉴于火花的快节奏发展,我们觉得这是很重要的,使我们的用户尽快开发和利用新特性。与传统的本地软件部署,它可以需要几个月,甚至几年,从供应商收到软件更新。数据砖的云模型,我们可以在几小时内更新,让用户试他们的火花版本的选择。
The last few releases of Spark focus on making data science more accessible, through high-level programming APIs such as DataFrames, machine learning pipelines, and R language support. A large part of Spark 1.5, on the other hand, focuses on under-the-hood changes to improve Spark’s performance, usability, and operational stability.
Spark 1.5 delivers the first phase of Project Tungsten, a new execution backend for DataFrames/SQL. Through code generation and cache-aware algorithms, Project Tungsten improves the runtime performance with out-of-the-box configurations. Through explicit memory management and external operations, the new backend also mitigates the inefficiency in JVM garbage collection and improves robustness in large-scale workloads.
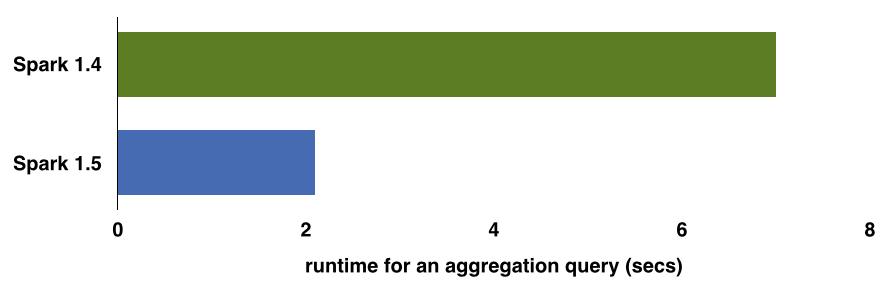
Over the next few weeks, we will be writing about Project Tungsten. To give you a sneak peek, the above chart compares the out-of-the-box (i.e. no configuration changes) performance of an aggregation query (16 million records and 1 million composite keys) using Spark 1.4 and Spark 1.5 on my laptop.
Streaming workloads typically run 24/7 and have stringent stability requirements. In this release, Typesafe has introduced Backpressure in Spark Streaming. With this feature, Spark Streaming can dynamically control the data ingest rates to adapt to unpredictable variations in processing load. This allows streaming applications to be more robust against bursty workloads and downstream delays.
Of course, Spark 1.5 is the work of more than 220 open source contributors from over 80 organizations, and includes a lot more than the above two. Some examples include:
New machine learning algorithms: multilayer perceptron classifier, PrefixSpan for sequential pattern mining, association rule generation, etc.
Improved R language support and GLMs with R formula.
Better instrumentation and reporting of memory usage in web UI.
Stay tuned for future blog posts covering the release as well as deep dives into specific improvements.
Launching a Spark 1.5 cluster is as easy as selecting Spark 1.5 experimental version in the cluster creation interface in Databricks.

Once you hit confirm, you will get a Spark cluster ready to go with Spark 1.5.0 and start testing the new release. Multiple Spark version support in Databricks also enables users to run Spark 1.5 canary clusters side-by-side with existing production Spark clusters.
You can find the work-in-progress documentation for Spark 1.5.0 here. Please be aware that just like any other preview software, Spark 1.5.0 support is experimental. There will be bugs and quirks that we find and fix in the next couple of weeks. The good news is that you don’t have to worry about following the development or upgrading yourself. As we discover and fix bugs in the open source project, the Spark 1.5 option in Databricks will also be updated automatically. If you encounter a bug, please report it by filing a JIRA ticket.
To try Databricks, sign up for a free 30-day trial.
在上一次北京sparkmeetup技术分享会上,一个spark commiter就说他们忙着Spark 1.5(核心工作就说Tungsten),一个新的DataFrames / SQL执行后端。项目支持缓存通过代码生成算法,提高运行时性能与Tungsten的开箱即用配置。通过显式的内存管理和外部操作,新的后端也减轻了低效JVM的垃圾收集,提高了鲁棒性在大规模的工作负载
目前来看,spark1.5第一阶段目前是完成,估计后期应该有很多优化和代码修复,但可尝尝甜头,如果想了解1.5版本代码,看github spark1.5 branch,个人感觉 主要还是spark sql的提升吧,因为大多数公司都是 spark on yarn的方式,大多数任务提升希望在spark sql上面
在 Databricks 可获得 Spark 1.5 预览版
标签:
原文地址:http://my.oschina.net/ghostmanyue/blog/496870