标签:
LAB1:系统的启动
这里主要讲了两个关键的点
1.操作系统的启动的过程主要通过以下几个步骤
这里值得一说的是Boot loader。因为Boot loader完成了实模式到保护模式的切换(通过加载GD)
其中保护模式的切换具有很重要的意义,不仅仅是为了提供更大的地址访问空间,而且后边我们也可以看到通过中间增加了一层的访问的方法,可以实现对内存的读写保护.
2程序之间的调用关系
很基础的东西,就是程序相互调用时。把栈底压栈,然后返回时弹出
LAB2:内存管理模块
这个实验主要实现了操作系统的内存管理模块。这里实现主要分为两部分
1.物理内存通过链表的方式进行管理,定义一个
1 Struct PageInfo{ 2 Struct PageInfo * next; 3 size_t ref; 4 }
结构体进行控制,这里next如果是空闲表,指向下个地址,如果不是则为NULL,而ref则主要标记这个物理内存地址被引用的次数,如果等于0,则表示没有被使用
2.虚拟地址到物理内存的映射
Jos利用了一个双层的页表项进行管理虚拟地址。这里的虚拟地址空间的管理,主要通过查找这两个的页表项进行。其实每个页表项又可以设置相应的控制位,也就是利用这些控制位从而实现了内存的读写保护。其虚拟地址到物理的转换可以由下图说明(选自intel手册 http://pdosnew.csail.mit.edu/6.828/2014/readings/i386/toc.htm)
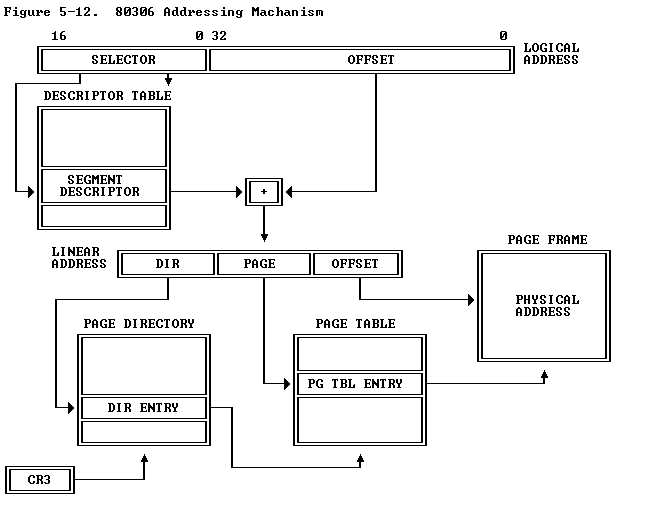
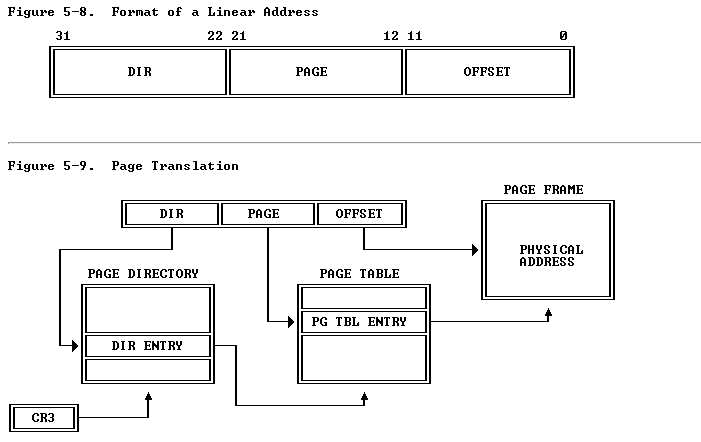
这里需要提到的地址的转换过程,以及虚拟地址到物理地址的映射。另外part3部分提及了内核和用户空间的区分。ULIM之上的是内核空间,一般而言内核和用户空间之间还有一段空间是内核和用户都是只能读取不能修改的,那段空间存放着管理内存的Pagetable以及虚拟内存表,还有环境空间变量。
LAB3 进程以及中断的切换
这部分实验主要分为两个部分进行,第一部分主要是进程的创建和初始化。
1 struct Env { 2 struct Trapframe env_tf; // Saved registers 3 struct Env *env_link; // Next free Env 4 envid_t env_id; // Unique environment identifier 5 envid_t env_parent_id; // env_id of this env‘s parent 6 enum EnvType env_type; // Indicates special system environments 7 unsigned env_status; // Status of the environment 8 uint32_t env_runs; // Number of times environment has run 9 10 // Address space 11 pde_t *env_pgdir; // Kernel virtual address of page dir 12 };
由PCB可以看出进程中存放的那些变量。其中env_pgdir指的是每个进程打开的文件接口。其中env_pgdir指的是内存中保存的文件表,而env_tf则是保存各个进程的寄存器数据,可以用以cpu切换时使用。
中断切换当中有两点需要注意的,分别是
1.调用中断处理程序的过程
2.中断处理的中的寄存器切换
以下这个图可以较好的解释中断的切换过程
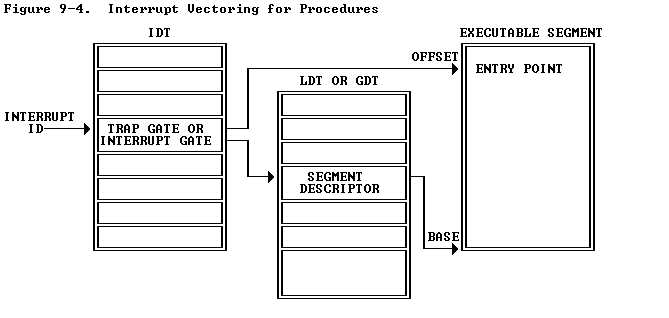
其中通过一个中断号在IDT(中断描述符表中进行查找),然后确定相应的中断处理程序。然后进行中断切换的工作,这里中断切换需要先将当前进程的寄存器地址压栈。然后调用相应的中断处理程序对其进行处理,处理完成后pop出相应的寄存器的值。这样也就完成了相应的中断处理过程。这里有几点需要注意的
LAB4 多核处理器以及多任务切换
多核处理器的支持。多核处理器有两个方面的需要注意的。
1.多核处理器的启动
2.多核处理器之间的通信
先说多核处理器的启动问题,启动时都是先单核启动,由BSP(bootstarp processor) 启动然后通知其它处理也启动 ,这里就涉及到了第二个方面的问题,那就是多核处理器之间的通信问题。首先我们要知道对于每个处理器都有一个APIC,要与多核处理器进行通信,首先就要通过APIC。而怎么向APIC中传递数据,这里就将内存中的一块映射为通信区域。对这个区域内进行读写就相当于向相应的APIC发送数据。
Per-CPU kernel stack.
Per-CPU TSS and TSS descriptor.
Per-CPU current environment pointer.
Per-CPU system registers.
这里每个cpu需要保存的数据如上所示。
问题 1.TSS作用 2.为什么要有cpu栈
对于多处理器问题,要实现内核的加锁功能,从而实现只有一个进程陷入内核的功能。
再实现了内核加锁功能后,下一步就是要实现内核切换任务的功能,这里的基于LAB3中的env_run来实现的。总体思想就是从内核的就绪态中选取一个处于Runnable的进行,然后调用。这里需要注意如果没有就绪进程,就调用原先运行的进程,切不可调用其它运行的进行,因为它们可能正在其它cpu上运行。
fork的实现:
fork()实现思路是这样,从进程列表里选取一个进程进行初始化设置其为RUNNABLE那么它就可以执行了,这也是fork可以一次执行返回两次的原因。
fork()是操作系统中非常常用的系统调用中,这里实现了fork函数使用了copy_on_write的机制。这种机制的思想就是当fork时并不复制父进程的内存空间,只有当子进程写入时才进行复制。这里的处理方法是在PCB中加入page_fault的函数指针,当触发page_fault时看看进程中的page_fault指针是否为NULL,如果不是则调用该指针。否则调用默认处理。这里之所以不使用内核的默认page_fault函数是因为,内核的page_fault默认处理并不是仅仅复制一份,可能会将磁盘中的数据调入内存,但是这里仅仅需要复制一份,与默认的处理不相符。因为要在用户空间处理中断,所以这里也需要在用户空间开辟一个堆栈UXSTACK用以模拟内核处理中断的过程。这里中断的处理首先通过将tf中寄存器内容保存UXSTACK中,然后再将设置esp eip到相应的位置。
copy_on_write的实现思路是这样的。首先在fork中通过子程序将父程序的地址复制一份,然后利用设置相应的寄存器为不能写,这样一旦发生写操作时候,就会导致page_fault操作,而对于page_fault操作当中想进行压栈保存工作,然后进行中断处理。这里很显然就是想到将发生写操作的页copy一份,然后映射到相应pte当中,这样子进程中发生page_fault处地址的值与父进程并不相同了。
PARTC
这部分实现了两个方面的功能:
1. IRQ中断
2. IPC 进程间通信
IRQ中断与中断类似不过其执行的是硬件中断,实验中利用了IRQ中断实现了处理器的时间片管理/
IPC进程间通信,实验中通过实现了两种信息的传递,一个int类型的数值以及内存中Page的传递。其中int类型传递过程比较简单就是通过虚拟地址中所共有的进程列表,找出所要传递的进程号,写入相应的PCB当中即可。而Page的传递稍微复杂些。这个传递过程分为传递和接收两部分进行,传递方首先要通过page_lookup找出所要传递的page,接收放在PCB中有个值是保存用来接收的page地址的,当进程要接收相应的page时,作为接收方首先要将接收的地址初始化,确保其有足够的空间可以接收这些地址。当然作为接收方和发送方,其发送的数据都要位于UTOP之下,不能发送内核的数据。
LAB5 文件管理系统
实验首先让你确定一个进程是否可以访问文件系统,即是否可以进行IO OUT操作,这个在创建进程时就要实现。这里通过FLAG寄存器来实现这个功能。紧接着让你实现一个block buffer功能的模块,这个功能的模块的原理就是在内存中开辟一个区域,用以对硬盘数据进行缓存(文中是0X1000000 - 0xD0000000)。利用LAB4中的映射,首先映射一个页到这个虚拟地址当中,然后调用ide_read读入数据。而flush功能与其相反,是写入到内存当中,这里需要注意的内存中是不是存在要写入的页,这里通过PTE_D这个位置来判断。
通过IPC进行文件系统的读取:
并不是所有的进程都可以进行文件系统的读取的,ex1中已经完成这部分的功能了。通过FLAG寄存器来判断。很显然就会联想到使用IPC来进行操作文件系统。以下给出读写文件的框架图。
Regular env FS env +---------------+ +---------------+ | read | | file_read | | (lib/fd.c) | | (fs/fs.c) | ...|.......|.......|...|.......^.......|............... | v | | | | RPC mechanism | devfile_read | | serve_read | | (lib/file.c) | | (fs/serv.c) | | | | | ^ | | v | | | | | fsipc | | serve | | (lib/file.c) | | (fs/serv.c) | | | | | ^ | | v | | | | | ipc_send | | ipc_recv | | | | | ^ | +-------|-------+ +-------|-------+ | | +-------------------+
可以看出对文件系统的操作是通过IPC交给相应的文件系统操作进程进行的。以下再给出对于每个打开文件的说明结构体
1 // The file system server maintains three structures 2 // for each open file. 3 // 4 // 1. The on-disk ‘struct File‘ is mapped into the part of memory 5 // that maps the disk. This memory is kept private to the file 6 // server. 7 // 2. Each open file has a ‘struct Fd‘ as well, which sort of 8 // corresponds to a Unix file descriptor. This ‘struct Fd‘ is kept 9 // on *its own page* in memory, and it is shared with any 10 // environments that have the file open. 11 // 3. ‘struct OpenFile‘ links these other two structures, and is kept 12 // private to the file server. The server maintains an array of 13 // all open files, indexed by "file ID". (There can be at most 14 // MAXOPEN files open concurrently.) The client uses file IDs to 15 // communicate with the server. File IDs are a lot like 16 // environment IDs in the kernel. Use openfile_lookup to translate 17 // file IDs to struct OpenFile. 18 19 struct OpenFile { 20 uint32_t o_fileid; // file id 21 struct File *o_file; // mapped descriptor for open file 22 int o_mode; // open mode 23 struct Fd *o_fd; // Fd page 24 };
如注释所描述的struct File 是描述文件的物理结构,struct Fd是文件描述符,里边是文件读取位置,文件设备以及文件打开模式等的数据。
ex5,ex6要求实现文件的读取与写入操作。
这里文件的读取与写入操作的过程如下(这里的fs env可能有多个)
1.首先通过IPC将要打开的文件id以及读取的byte传递给 fs env
2. fs env通过id转换为相应的打开文件,并且通过OpenFile这个结构体中相应的文件描述符等信息读取文件
3. 读取文件后传入到IPC的buffer当中,再利用IPC传送回去
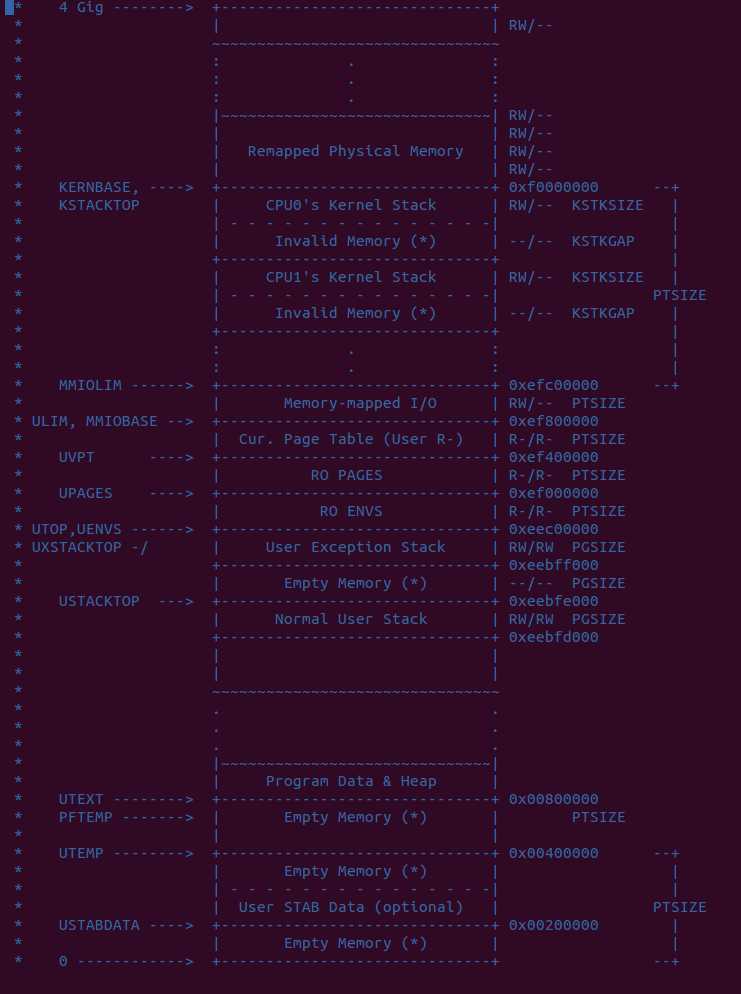
最后附上一张虚拟地址的分布图,可以说这几个实验就是一步步解释这个内存分布中各个区域的作用。
标签:
原文地址:http://www.cnblogs.com/qtalker/p/4733240.html