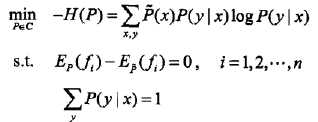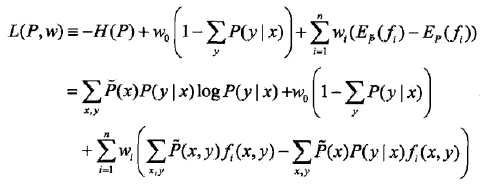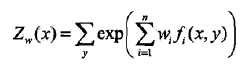标签:
模型参数估计
最大熵模型的定义
最大熵模型的学习
统计学习方法 李航---第6章 逻辑回归与最大熵模型
原文地址:http://www.cnblogs.com/YongSun/p/4761793.html
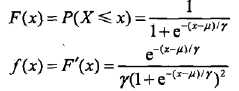
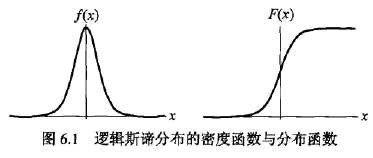
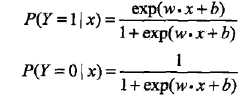
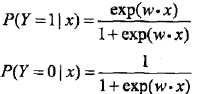
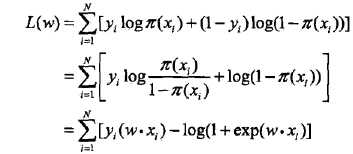
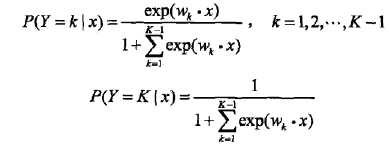
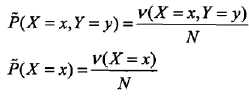
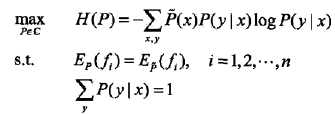 转化为
转化为