标签:
EntityFramework之领域驱动设计实践 (一):从DataTable到EntityObject
EntityFramework之领域驱动设计实践 (二):分层架构
EntityFramework之领域驱动设计实践 (三):案例:一个简易的销售系统
EntityFramework之领域驱动设计实践 (四):存储过程 - 领域驱动的反模式
EntityFramework之领域驱动设计实践 (五):聚合
EntityFramework之领域驱动设计实践 (六):模型对象的生命周期 - 工厂
EntityFramework之领域驱动设计实践 (七):模型对象的生命周期 - 仓储
EntityFramework之领域驱动设计实践 (八):仓储的实现(基本篇)
EntityFramework之领域驱动设计实践 (九):仓储的实现(深入篇)
EntityFramework之领域驱动设计实践 (十):规约(Specification)模式
EntityFramework之领域驱动设计实践【扩展阅读】:服务(Services)
EntityFramework之领域驱动设计实践【扩展阅读】:CQRS体系结构模式
EntityFramework之领域驱动设计实践 - 前言
根据网友的讨论结果,以及自己在实践中的不断积累,在整理的过程中,我会将原文中的描述作相应调整。不仅如此,也有不少关心领域驱动设计的网友在原文的评论栏目中提了问题或作了批注,我也针对网友的问题给予了细致的答复,为了能够让更多的朋友了解到问题的本质,本次整理稿会将评论部分也一一列出,供大家参考。
EntityFramework
EntityFramework是微软继LINQ to SQL之后推出的一个更为完整的领域建模和数据持久化框架。初见于.NET Framework 3.5版本,4.0的.NET Framework已经集成了EntityFramework。使用.NET 4.0的朋友就不需要下载和安装额外的插件了。与LINQ to SQL相比,EntityFramework从概念上将系统设计的关注点从数据库驱动转移到模型/领域驱动上。
领域驱动设计(DDD)
领域驱动设计并不是一门技术,也不是一种方法论。它是一种考虑问题的方式,是一种经验积累,它关注于那些处理复杂领域问题的软件项目。为了获得项目成功,团队需要具备一系列的设计实践、开发技术和开发准则。与此相关的技术与设计/代码重构也是领域驱动设计讨论的重点。
本系列文章就是着重讨论EntityFramework在领域驱动设计上的实践,也希望DDD与.NET的爱好者能够从文中获得启发,将解决方案用在自己的实际项目中。
从DataTable到EntityObject
虽然从技术角度讲,DataTable与EntityObject并没有什么可比性,然而,它暗示了一场革命正在悄然进行着,即使是微软,也摆脱不了这场革命的飓风。
软件设计思想需要革命,需要摆脱原有的思路,而走向面向领域的道路。你或许会觉得听起来很玄乎,然而目前软件开发的现状使你不得不接受这样的现实,仍然有大帮的从业人员成天扯着数据库不放,仍然有大帮的人在问:“我要实现xxxx功能,我的数据库应该如何设计?”这些人犯了根本性的错误,就是把软件的目的搞错了,软件研究的是什么?是研究如何使用计算机来解决实际(领域)问题,而不是去研究数据应该如何保存更合理。这方面的事情我在我以前的博文中已经说过很多次了,在此就不再重复了。
当然,很多读者会跟我有着相同的观点,也会觉得我很“火星”,但这都不要紧,上面我所说的都是一个引子,希望能够帮助更多“步入歧途”的从业人员 “走上正路”。不错,软件设计应该从“数据库驱动”走向“领域驱动”,而领域驱动设计的实践经验正是为设计和开发大型复杂的软件系统提供了实践指导。
回到我们的副标题,从DataTable到EntityObject,你看到了什么?看到的是微软在领域驱动上的进步,从DataTable这一纯粹的数据组织形式,到EntityObject这一实体对象,微软带给我们的不仅仅是技术框架,更是一套面向领域的解决方案。
.NET 4.0来了,随之而来的是实体框架(EntityFramework,简称“EF”),在本系列文章中,我将结合领域驱动设计的实践知识,来剖析EF的具体应用过程,当然,现在的EF还并不是那么完善,我也非常期待能够看到,今后微软能够继续发展和完善EF,使其成为微软领域驱动工具箱中的重要角色。
先不说EF,首先我们简要地分析一下,作为一种框架,要支持领域驱动的思想,需要满足哪些硬性需求,之后再仔细想想,.NET EF是否真的能够很好地应用在领域驱动上。

从上面的描述,我们对EF的功能有了个大概的了解,接下来的系列文章,我会和大家一起,一步步地探讨,如何在EF上应用领域驱动设计的思想,进而完成我们的案例程序。本系列文章均为我个人原创,或许在某些问题上你会有不同意见,不要紧,你可以直接签写留言,或者发邮件给我,期待与你的探讨,期待与你在软件架构设计的道路上共同进步。
分层架构
在引入实例以前,我们有必要回顾,并进一步了解分层架构。“层”是一种体系结构模式[POSA1],也是被广大软件从业人员用得最为广泛而且最为灵活的模式之一。记得在CSDN上,时常有朋友问到:“分层是什么?为什么要分层?三层架构是不是就是表现层、业务逻辑层和数据访问层?”
到这里,你可能会觉得这些朋友的问题很简单,分层嘛,不就是将具有不同职责的组件分离开来,组成一套层内部高聚合,层与层之间低耦合的软件系统吗?不错!这是分层的目标。但是,我们应该如何分层呢?
领域驱动设计的讨论同样也是建立在层模式的基础上的,但与传统的分层架构相比,它更注重领域架构和技术架构的分离。
传统的三层架构
如上文那位朋友提的问题那样,最简单的分层方式自然就是“表现层、业务逻辑层和数据访问层”,我们可以用下图来表示这个思想:

注意图中打虚线的“基础结构层”,从实践的表现上来看,这部分内容可能就是一些帮助类,比如 SQLHelper之类的,也可能是一些工具类,比如TextUtility之类。这些东西可以被其它各层所访问。而基于分层的概念,表现层只能跟业务逻辑层打交道,而业务逻辑层在数据持久化方面的操作,则依赖于数据访问层。表现层对数据访问层的内容一无所知。
从领域驱动的角度看,这种分层的方式有一定的弊端。首先,为各个层面提供服务的“基础结构层”的职责比较紊乱,它可以是纯粹的技术框架,也可以包含或处理一定的业务逻辑,这样一来,业务逻辑层与“基础结构层”之间就会存在依赖关系;其次,这种结构过分地突出了“数据访问”的地位,把“数据访问”与 “业务逻辑”放在了等同的地位,这也难怪很多软件人员一上来就问:“我的数据表该如何设计?”
领域驱动设计的分层
领域驱动设计将软件系统分为四层:基础结构层、领域层、应用层和表现层。与上述的三层相比,数据访问层已经不在了,它被移到基础结构层了。
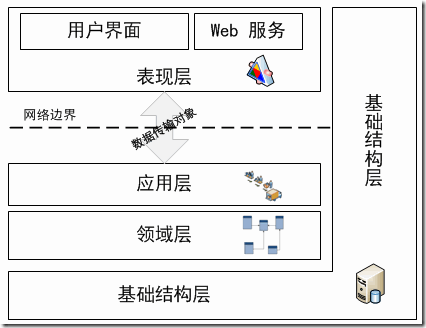
从上图还可以看到,表现层与应用层之间是通过数据传输对象(DTO)进行交互的,数据传输对象是没有行为的POCO对象,它的目的只是为了对领域对象进行数据封装,实现层与层之间的数据传递。为何不能直接将领域对象用于数据传递?因为领域对象更注重领域,而DTO更注重数据。不仅如此,由于“富领域模型”的特点,这样做会直接将领域对象的行为暴露给表现层。
从下一个章节开始,我将以最简单的销售系统为例,介绍EntityFramework下领域驱动设计的应用。
案例:一个简易的销售系统
从现在开始,我们将以一个简易的销售系统为例,探讨EntityFramework在领域驱动设计上的应用。为了方便讨论,我们的销售系统非常简单,不会涉及客户存在多个收货地址的情况,也不会包含任何库存管理的内容。假设我们的系统只需要维护产品类型、产品以及客户信息,并能够帮客户下订单、跟踪订单状态,以及接受客户退货。从简单的分析我们大致可以了解到,这个系统将会有如下实体:客户、单据、产品及其类型。单据分为销售订单和退货单两种,每个单据可以有多个单据行(比如销售订单行和退货单行)。不仅如此,系统允许每个客户有多张信用卡,以便在结账的时候,选择一张信用卡进行支付。在使用EF的Entity Data Model Designer进行设计后,我们得到下面的模型:
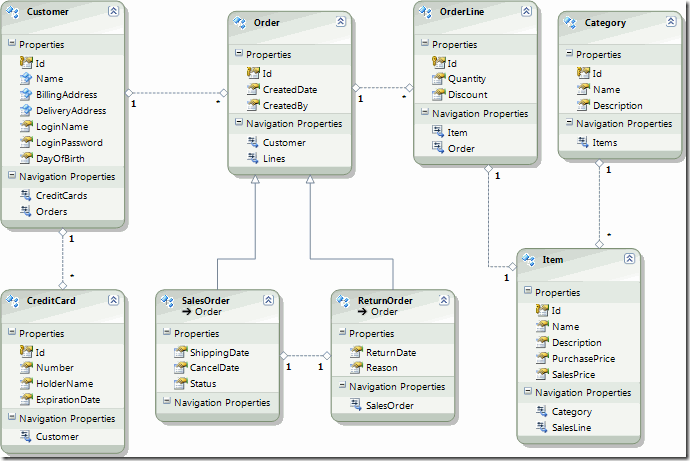
上面的模型表述了领域模型中各个实体及其之间的关系。我们先不去讨论整个系统的业务会是什么样的,我们先看看EF是如何支持实体和值对象概念的。
实体
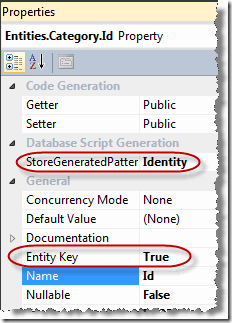
首先看看实体这个概念。在领域驱动设计的理论中,实体是模型中需要区分个体的对象,也就是说,针对某种类型,我们既要知道它是什么,还需要知道它是哪个。我在前面的博文中有介绍过实体这个概念。实体都有一个标识符,以便跟同类型的其它实体进行区分。EF Entity Data Model Designer上能够画出的都是实体,你可以看到每个实体都有个Id成员,其Entity Key属性被设置为True,同时被分配了一种标识符的生成方式,如下图所示:
在从领域模型映射到数据模型的过程中,这个标识符通常都是被映射为关系数据库某个数据表的主键,这个应该是很容易理解的。
其次,EF不支持实体行为,因此,整个模型只能被称为Entity Data Model,而不是Entity Model,因为它只支持对实体数据的描述。幸亏从.NET 2.0开始,托管语言开始支持partial特性,同一个类可以以部分类(partial class)的特性写入多个代码文件中。因此,如果需要向上述模型中的实体加入行为,我们可以在工程中加入几个代码文件,然后使用部分类的特点,为实体添加必要的行为。比如,下面的部分类向订单行中加入了一个只读属性,该属性用于计算某一单据行所拥有的总金额:
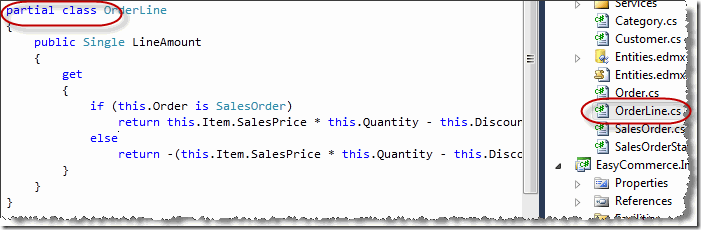
有朋友会问,为什么我们要另外使用部分类,而不是直接在模型文件 edmx的源代码上直接修改?因为这个源代码文件是框架动态生成的,如果在上面修改,等下次模型被更新的时候,你所做的更改便会丢失。
对于实体的行为,EF支持从数据库存储过程生成实体对象行为的过程。对此,我持批判态度:EF把数据模型与实体模型混为一谈了,这种做法只能让软件人员感到更加困惑。我在下一篇文章将重点表述我对这个问题的看法。我也相信微软在下一代实体框架中能够处理好这个问题。
再次,EF对实体对象关系的支持主要有关联和继承。根据Multiplicity的设置,关联又可以支持到组合关联与聚合关联。我觉得EF中对继承关系的支持是一个亮点。继承表述了“什么是一种什么”的观点,比如在我们的案例中,“销售订单”和“退货单”都是一种“单据”。如果从传统的数据库驱动的设计方案,我们很自然地会使用“Orders”数据表中的整型字段“OrderType”来保存当前单据的类型(比如0表示销售订单,1表示退货单),那么,在获取系统中所有销售订单的时候,我们会使用下面的代码:
List<Order> GetSalesOrders(IDbConnection connection)
{
IDbCommand command = new SqlCommand("SELECT * FROM [Orders] WHERE [OrderType]=0",
(SqlConnection)connection);
List<Order> orders = new List<Order>();
using (IDataReader dr = command.ExecuteReader())
{
while (dr.Read())
{
Order order = new Order();
order.Id = Convert.ToInt32(dr["Id"]);
// ...
orders.Add(order);
}
dr.Close();
}
return orders;
}
|
从技术角度讲,上面的代码没什么问题,运行的也很好,能够获得系统中所有销售订单的列表。但是, [OrderType]=0这种写法并不包含任何领域语义,如果让另一个开发人员来跟进这段代码,他不得不先去查阅其它项目文档,以了解这个 [OrderType]=0的具体涵义。在引入了继承关系的EF中,我们只需要下面的Linq to Entities,即可既方便、又明了地获得所有销售订单的列表了:
List<Order> GetSalesOrders()
{
using (EntitiesContainer container = new EntitiesContainer())
{
return (from order in container.Orders
where order is SalesOrder
select order).ToList();
}
}
|
简单明了吧?EF带给我们的不仅仅是一个技术框架,也不仅仅是一个数据存取的解决方案。
值对象
EF支持值对象,这很好!在EF中可以定义Complex Types,而一个Complex Type下可以定义多个Primitive Type和多个Complex Type。与LINQ to SQL相比,这是一大进步。
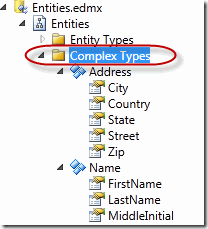
对于值对象的两点问题我在第一篇文章中已经讲过了,在此就不重复了。
综上所述,EF基本上能够支持领域驱动设计的思想(即使有些方面不完善,但目前也可以找到替代的方案)。我想,只要能够对领域驱动有清晰的认识,就能够很好地将实体框架应用于领域驱动的实践中。
存储过程 - 领域驱动的反模式
EntityFramework(EF)中有一项功能,就是能够根据数据库中的存储过程生成实体的行为(或称方法,以下统称方法)。我在本系列的第一篇博文中就已经提到,这种做法并不可取!因为存储过程是技术架构中的内容,而我们所关注的却是领域模型。
Andrey Yemelyanov在其“Using ADO.NET EF in DDD: A Pattern Approach”一文中,有下面这段话:
In this context, the architect also identified the anti-pattern of using the EF (ineffective use): the EF is used to mechanically derive the domain model from the database schema (database-driven approach). Therefore, the main topic of the guidelines should be the domain-driven development with the EF and the primary focus should be on how to build a conceptual model over a relational model and expose it to application programmers.
黑体部分的意思是:(被采访的架构师)同时也指出了使用EF的一种“反模式”,即通过使用数据库结构来机械化地生成领域模型(数据库驱动的方式)。这也就证明了我在第一篇文章中指出的“只能通过领域模型来映射到数据模型,反过来则不行”的观点。
我能够理解很多做系统的朋友喜欢考虑数据库方面的事情,毕竟数据存储也是软件系统中不可或缺的部分(当然,内存数据库另当别论),数据库结构设计的好坏直接影响到系统的运行效率。比如:加不加索引、如何加索引,将对查询效率造成重大影响。但请注意:你把过多的精力放在了技术架构上,而原本更重要的业务架构却被扔到了一边。
什么时候选择存储过程?我认为存储过程的操作对象应该是数据,而不是对象,业务层也不可能把业务对象交给数据库去处理。其实,存储过程本身的意义也就是将数据放在DB服务器上处理,以减少客户程序与服务器之间的网络流量和往返次数,从而提高效率。所以,可以把查询次数较多的、与业务无关的数据处理交给存储过程(比如数据统计),而不要单纯地认为存储过程能够帮你解决业务逻辑问题,那样做只会让你的领域模型变得混乱,久而久之,你将无法应对复杂的业务逻辑与需求变更。
在做技术选型的时候还要注意一点,也就是存储过程的数据库相关性。存储过程是特定于某种关系型数据库机制的,比如,SQL Server的存储过程与Oracle的存储过程并不通用,而有些数据库系统甚至不支持存储过程。因此过多使用存储过程将会给你带来一些不必要的麻烦。我个人对是否使用存储过程给出如下几点意见:1、根据需求来确定;2、不推荐使用;3、出于效率等技术考虑,需要使用的,酌情处理。
回过头来看实体框架,虽然现在支持从数据库存储过程生成实体方法的过程,但这是一种反模式,我也不希望今后EF还提供将实体方法映射到存储过程的功能,因为行为不同于数据,数据是状态,而行为是业务,它与领域密切相关,它不应该被放到“基础结构层”这一技术架构中。
聚合
聚合(Aggregate)是领域驱动设计中非常重要的一个概念。简单地说,聚合是这样一组领域对象(包括实体和值对象),这组领域对象联合起来表述一个完整的领域概念。比如,根据Eric Evans《领域驱动设计》一书中的例子,一辆车包含四个轮子,轮子离开“车”就毫无意义,此时这个联合体就是聚合,而“车”就是聚合根(Aggregate Root)。
从实践中得知,并非领域模型中的每个实体都能够完整地表述一个明确的领域概念,就比如客户与送货地址的关系。假设在某个应用中,系统需要为每个客户维护多个送货地址,此时送货地址就是一个实体,而不是值对象。那么这样一来,领域模型中至少就有了“客户”和“送货地址”两个实体,而事实上,“送货地址”是针对“客户”的,离开“客户”,“送货地址”就变得毫无意义。于是,“送货地址”就和“客户”一起,完整地表达了“客户可以有多个送货地址,并能对它们进行维护”的思想。
在《实体框架之领域驱动实践(三) - 案例:一个简易的销售系统》一文中,我们简单地设计了一个领域模型,其中包含了一些必要的实体和值对象。现在,我用不同颜色的笔在这个领域模型上圈出了三个聚合:客户、订单以及产品分类,如下图所示:
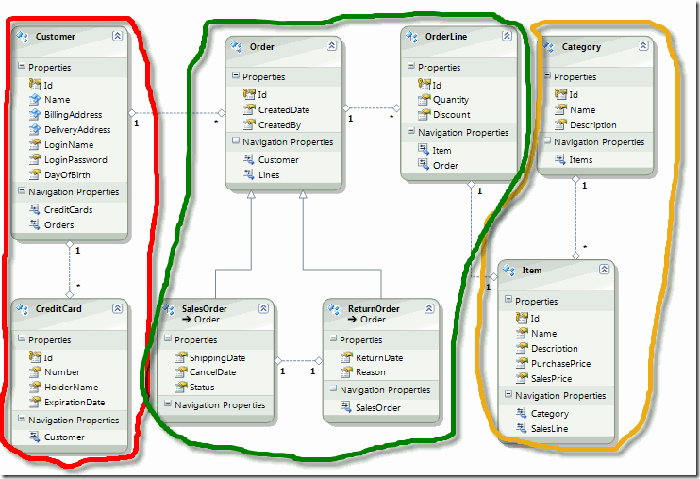
【注意】:如果像上图所示,Category-Item组成一个聚合,那么此时聚合根就应该是Item,而不是Category,因为Category对Item从概念上并没有包含/被包含的关系,而更多情况下,Category是 Item的一种信息描述,即某个Item是可以归类到某个Category的。在这种情况下,我们不需要对Category进行维护,Category就以值对象的形式存在于领域模型中。如果是另一种应用场合,比如,我们的系统需要针对Category进行促销,那么我们需要维护Category的信息,由此Category和Item就分属两个不同的聚合,聚合根为各自本身。
首先是“客户-信用卡”聚合,这个聚合表示了一个客户可以拥有多张信用卡,类似于上面所讲的 “客户-送货地址”的概念;其次是“订单-订单行”的聚合,类似地,虽然订单行也是一个实体,因为在应用中需要对每个订单行进行区分,但是订单行离开订单就变得毫无意义,它是“订单”概念的一部分;最后是“产品分类-产品”的聚合。
每个聚合都有一个根实体(聚合根,Aggregate Root),这个根实体是聚合所表述的领域概念的主体,外部对象需要访问聚合内的实体时,只能通过聚合根进行访问,而不能直接访问。从技术角度考虑,聚合确定了实体生命周期的关注范围,即当某个实体被创建时,同时需要创建以其为根的整个聚合,而当持久化某个实体时,同样也需要持久化整个聚合。比如,在从外部持久化机制重建“客户”对象的同时,也需要将其所拥有的“信用卡”赋给“客户”实体(具体如何操作,根据需求而定)。不要去关注聚合内实体的生命周期问题,如果你真的这么做了,那么你就需要考虑下你的设计是否合理。
由此引出了“领域对象生命周期”的问题,这个问题我会在后面两节单独讨论,但目前至少知道:
1.领域对象从无到有的创建,不是针对某个实体的,而是针对某个聚合的
2.领域对象的持久化(通常所说的“保存”)、重建(通常所说的“查询”)和销毁(通常所说的“删除”)也不是针对某个实体的,而是针对某个聚合的
很可惜,微软的EntityFramework(实体框架,EF)目前并不支持“聚合”的概念,所有的实体都被一股脑地塞到 ObjectContext中:
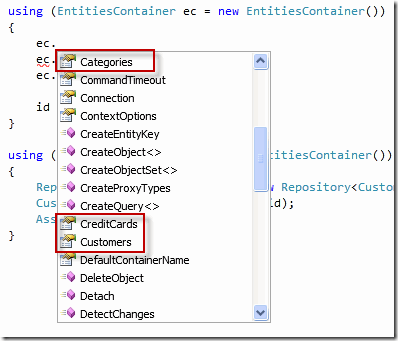
为了实现聚合的概念,我们又一次地需要用到“部分类(partial class)”的功能。我们首先定义一个IAggregateRoot的接口,修改每个聚合根的实体类,使其实现IAggregateRoot接口,如下:
public interface IAggregateRoot
{
}
|
[AggregateRoot("Orders")]
partial class Order : IAggregateRoot
{
public Single TotalDiscount
{
get
{
return this.Lines.Sum(p => p.Discount);
}
}
public Single TotalAmount
{
get
{
return this.Lines.Sum(p => p.LineAmount);
}
}
}
|
到这里又有问题了,接口IAggregateRoot中什么都没有定义?!我在我的技术博客中,特别解释了C#中接口的三种用途,请参考这篇文章:《C#基础:多功能的接口》。在这里,我们将IAggregateRoot接口用作泛型约束。在看完后续的两篇介绍领域对象生命周期的文章后,你就能够更好地理解这个问题了。事实上,在领域驱动设计的社区中,不少人都是这样用的。
最后说明一下,由于实体框架使所有的实体类继承于EntityObject类,而从面向对象的角度,接口是没办法去继承于类的,因此,在这里我们的 IAggregateRoot接口好像跟实体没什么太大的关系,而事实上聚合根应该是一种实体。在很多领域驱动的项目中,设计人员专门设计了 IEntity接口,所有实现了该接口的类都被认定为实体类,于是,IAggregateRoot接口也就很自然地继承IEntity接口,以表示“聚合根是一种实体”的概念,代码大致如下:
public interface IEntity
{
Guid Id { get; set; }
}
public interface IAggregateRoot : IEntity
{
}
|
总的来说,领域模型需要根据领域概念分成多个聚合,每个聚合都有一个实体作为“聚合根”,通俗地说,领域对象从无到有的创建,以及CRUD操作都应该作用在聚合根上,而不是单独的某个实体。当你的代码需要直接对聚合内部的实体进行CRUD操作时,就说明你的模型设计已经存在问题了。
模型对象的生命周期 - 工厂
首先应该认识到,是对象就有生命周期。这一点无论在面向对象语言还是在领域驱动设计中都适用。在领域驱动设计中,模型对象生命周期可以简要地用下图表示:
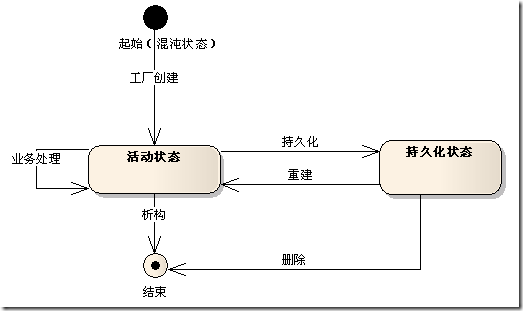
通过上图可以看到,对象通过工厂从无到有创建,创建后处于活动状态,此时可以参与领域层的业务处理;对象通过仓储实现持久化(也就是我们常说的“保存”)和重建(也就是我们常说的“读取”)。内存中的对象通过析构而消亡,处于持久化状态的对象则通过仓储进行撤销(也就是我们常说的“删除”)。整个状态转换过程非常清晰。
现在引出了管理模型对象生命周期的两种角色:工厂和仓储。同时也需要注意的是,工厂和仓储的操作都是基于聚合根(Aggregate Root)的,而不仅仅是针对实体的。关于仓储,内容会比较多,我在下一节单独讲述。在本节介绍一下工厂在.NET实体框架(EntityFramework)中的实现。
在打开了.NET实体框架自动生成的Entity Data Model Source Code文件后,我们发现,.NET实体框架为每一个实体添加了一个工厂方法,该方法包含了一系列原始数据类型和值类型的参数。比如,我们案例中的 Customer实体就有如下的代码:
/// <summary>
/// Create a new Customer object.
/// </summary>
/// <param name="id">Initial value of the Id property.</param>
/// <param name="name">Initial value of the Name property.</param>
/// <param name="billingAddress">Initial value of the BillingAddress property.</param>
/// <param name="deliveryAddress">Initial value of the DeliveryAddress property.</param>
/// <param name="loginName">Initial value of the LoginName property.</param>
/// <param name="loginPassword">Initial value of the LoginPassword property.</param>
/// <param name="dayOfBirth">Initial value of the DayOfBirth property.</param>
public static Customer CreateCustomer(global::System.Int32 id, Name name, Address billingAddress,
Address deliveryAddress, global::System.String loginName,
global::System.String loginPassword, global::System.DateTime dayOfBirth)
{
Customer customer = new Customer();
customer.Id = id;
customer.Name = StructuralObject.VerifyComplexObjectIsNotNull(name, "Name");
customer.BillingAddress = StructuralObject.VerifyComplexObjectIsNotNull(billingAddress, "BillingAddress");
customer.DeliveryAddress = StructuralObject.VerifyComplexObjectIsNotNull(deliveryAddress, "DeliveryAddress");
customer.LoginName = loginName;
customer.LoginPassword = loginPassword;
customer.DayOfBirth = dayOfBirth;
return customer;
}
|
那么在创建一个Customer实体的时候,就可以使用 Customer.CreateCustomer工厂方法。看来.NET实体框架已经离领域驱动设计的思想比较接近了,下面有几点需要说明:
到这里你会发现,工厂和仓储好像有这一种联系,即它们都能够创建对象,而区别在于,工厂是对象从无到有的创建,仓储则更偏向于“重建”。仓储要比工厂更为复杂,因为仓储需要跟持久化机制这一技术架构打交道。在接下来的文章中,我会介绍一种基于.NET实体框架,但又不被实体框架制约的仓储的实现方式。
模型对象的生命周期 - 仓储
上文中已经提到了管理领域模型对象生命周期的两大角色,即工厂与仓储,并对工厂的EntityFramework实践作了详细的描述。本节主要介绍仓储的概念,由于仓储的内容比较多,我将在接下来的两节中具体讲解仓储的架构设计与实践经验。
仓储(Repository),顾名思义,就是一个仓库,这个仓库保存着领域模型的实体对象。在业务处理的过程中,我们有可能需要把正在参与处理过程的对象保存到仓储中,也有可能会从仓储中读取需要的实体对象,抑或将对象直接从仓储中删除。上文也用一张简要的状态图描述了仓储在管理领域模型对象生命周期中所处的位置。
与工厂相同,仓储的关注对象也应该是聚合根,而不是聚合中的某个实体,更不应该是值对象。或许你会说,我当然可以针对销售订单行(Order Line)进行增删改查等操作,而无需跟销售订单(Sales Order)打交道。当然,你的确可以这样做,但如果你一定要坚持自己的观点,那么你就是把销售订单行(Order Line)当成是聚合根了,也就是说,你默许Order Line在你的领域模型中,是一种具有独立概念的实体。关于这个问题,在领域驱动设计的社区中,有人发表了更为“强势”的观点:
One interesting DDD rule is: you should create repositories only for aggregate roots.
When I read about it the first time I interpreted it this way: create repositories at least for all aggregate roots, but when you need a little repository for something else go ahead and implement it (and nobody will know what you did).
So I was thinking that the rule is somehow flexible. It turns out that it‘s not, and this is good: it keeps the domain stable and coherent. If entity A is an aggregate root, entity B is part of that aggregate, and you need to load B separated from the concept of A, this is a sign that the implementation does not reflect the business needs (anymore). In this case, B should probably become the root of its own aggregate
意思是说,如果实体A是聚合根,而B是该聚合中的一个实体,而你的设计希望绕过A而直接从仓储中获得B,那么,这就是一个信号,预示着你的设计可能存在问题,也就是说,B很有可能被当成是另一个聚合的根,而这个聚合只有一个对象,就是B本身。由此看来,聚合的划分与仓储的设计,在领域驱动设计的实践中是非常重要的内容。
工厂是从无到有地创建对象,从代码上看,工厂里充斥着new关键字,用以创建对象,当然,工厂的职责并不完全是new出一个对象那么简单。而仓储则更偏向于对象的保存和获得,在获得的时候,同样也会有新的对象产生,这个新的对象与保存进去的对象相比,引用不同了,但数据和业务ID值(也就是我们常说的实体键)是不变的,因此,在领域层看来,从仓储中读取得到的对象与当时保存进去的对象并没有什么两样。
你可能已经体会到,仓储就是一个数据库,它与数据库一样,有读取、保存、查询、删除的操作。我只能说,你已经了解到仓储的职能,并没有了解到它的角色。仓储是领域层与基础结构层的一个衔接组件,领域层通过仓储访问外部存储机制,这样就使得领域层无需关心任何技术架构上的实现细节。因此,仓储这个角色的职责不仅仅是读取、保存、查询、删除,它还解耦了领域层与基础结构层。在实践中,可以使用依赖注入的方式,将仓储实例注入到领域层,从而获得灵活的体系结构。
下面是我们案例中,仓储接口的代码:
public interface IRepository<TEntity>
where TEntity : EntityObject, IAggregateRoot
{
void Add(TEntity entity);
TEntity GetByKey(int id);
IEnumerable<TEntity> FindBySpecification(Func<TEntity, bool> spec);
void Remove(TEntity entity);
void Update(TEntity entity);
}
|
IRepository是一个泛型接口,泛型类型被where子句限定为EntityFramework中的EntityObject,与此同时,where子句还限定了泛型类型必须实现IAggregateRoot接口。换句话讲,IRepository接口的泛型类型必须是继承于EntityObject类,并实现了IAggregateRoot接口的引用类型。根据我们在 “聚合”一文中的表述,我们可以实现针对Customer、Order以及Category实体类的仓储类。
这里只给出了仓储实现的一个引子,至少到目前为止我们已经简单地定义了仓储实现的一个框架,也就是上面这个IRepository泛型接口。接口中具体要包括哪些方法,不是本系列文章要讨论的关键问题。为了描述与演示,我们只为IRepository接口设计如上四个方法,即Add、GetByKey、Remove和Update。接下来,我将详细描述在基于实体框架(EntityFramework)的仓储设计中所遇到的困难,以及如何在实践中解决这些困难。
仓储的实现:基本篇
我们先从技术角度考虑仓储的问题。实体框架(EntityFramework)中,操作数据库是非常简单的:在ObjectContext中使用LINQ to Entities即可完成操作。开发人员也不需要为事务管理而操心,一切都由EF包办。与原本的ADO.NET以及LINQ to SQL相比,EF更为简单,LINQ to Entities的引入使得软件开发变得更为“领域化”。
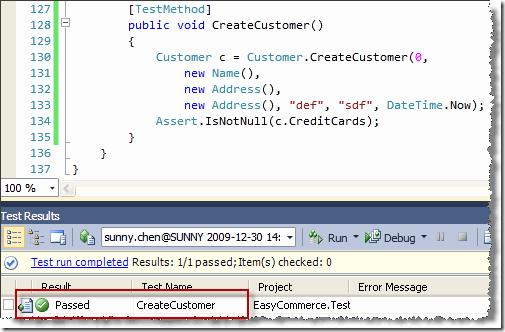
下面的代码测试了持久化一个 Customer实体,并从持久化机制中查询这个Customer实体的正确性。从代码中可以看到,我们用了一种很自然的表达方式,表述了“我希望查询一个名字为Sunny的客户”这样一种业务逻辑。
[TestMethod]
public void FindCustomerTest()
{
Customer customer = Customer.CreateCustomer("daxnet", "12345",
new Name { FirstName = "Sunny", LastName = "Chen" },
new Address(), new Address(), DateTime.Now.AddYears(-29));
using (EntitiesContainer ec = new EntitiesContainer())
{
ec.Customers.AddObject(customer);
ec.SaveChanges();
}
using (EntitiesContainer ec = new EntitiesContainer())
{
var query = from cust in ec.Customers
where cust.Name.FirstName.Equals("Sunny")
select cust;
Assert.AreNotEqual(0, query.Count());
}
}
|
如果你需要实现的系统并不复杂,那么按上面的方式添加、查询实体也不会有太大问题,你可以在 ObjectContext中随心所欲地使用LINQ to Entities来方便地得到你需要的东西,更让人兴奋的是,.NET 4.0允许支持并行计算的PLINQ,如果你的计算机具有多核处理器,你将非常方便地获得效率上的提升。然而,当你的架构需要考虑下面几个方面时,单纯的 LINQ to Entities方式就无法满足需求了:
于是,也就回到了上篇博客中我描述的问题:仓储不是Data Object,也不仅仅是进行数据库CRUD操作的Data Manager,它承担了解耦领域模型和技术架构的重要职责。为了完美地解决上面提到的问题,我们仍然采用领域驱动设计中仓储的设计模式,而将实体框架作为仓储的具体实现部分。在详细介绍仓储的设计与实现之前,让我们回顾一下上文最后部分我提到的那个仓储的接口:
public interface IRepository<TEntity>
where TEntity : EntityObject, IAggregateRoot
{
void Add(TEntity entity);
TEntity GetByKey(int id);
IEnumerable<TEntity> FindBySpecification(Func<TEntity, bool> spec);
void Remove(TEntity entity);
void Update(TEntity entity);
}
|
在本文的案例中,仓储是这样实现的:
1.将上述仓储接口定义在实体、值对象和服务所在的领域层。有朋友问过我,既然仓储需要与外部存储机制打交道,那么它必定需要知道技术架构方面的细节,而将其定义在领域层,就会使得领域层依赖于具体的技术实现方式,这样就会使领域层变得“不纯净” 了。其实不然!请注意,我们这里仅仅只是将仓储的接口定义在了领域层,而不是仓储的具体实现(Concrete Repository)。更通俗地说,接口作为系统架构的基础元素,决定了整个系统的架构模式,而基于接口的具体实现只不过是一种可替换的组件,它不能成为系统架构中的一部分。由于领域层需要用到仓储,我便将仓储的接口定义在了领域层。当然,从.NET的实现技术考虑,你可以新建一个Class Library,并将上述接口定义在这个Class Library中,然后在领域层和仓储的具体实现中分别引用这个Class Library
2.新建一个Class Library(在本文的案例中,命名为EasyCommerce.Infrastructure.Repositories),添加对领域层 assembly的引用,并实现上述接口。由于我们采用实体框架作为仓储的具体实现,因此,将这个仓储命名为EdmRepository(Entity Data Model Repository)。EdmRepository有着类似如下的实现:
internal class EdmRepository<TEntity> : IRepository<TEntity>
where TEntity : EntityObject, IAggregateRoot
{
#region Private Fields
private readonly ObjectContext objContext;
private readonly string entitySetName;
#endregion
#region Constructors
/// <summary>
///
/// </summary>
/// <param name="objContext"></param>
public EdmRepository(ObjectContext objContext)
{
this.objContext = objContext;
if (!typeof(TEntity).IsDefined(typeof(AggregateRootAttribute), true))
throw new Exception();
AggregateRootAttribute aggregateRootAttribute = (AggregateRootAttribute)typeof(TEntity)
.GetCustomAttributes(typeof(AggregateRootAttribute), true)[0];
this.entitySetName = aggregateRootAttribute.EntitySetName;
}
#endregion
#region IRepository<TEntity> Members
public void Add(TEntity entity)
{
this.objContext.AddObject(EntitySetName, entity);
}
public TEntity GetByKey(int id)
{
string eSql = string.Format("SELECT VALUE ent FROM {0} AS ent WHERE ent.Id=@id", EntitySetName);
var objectQuery = objContext.CreateQuery<TEntity>(eSql,
new ObjectParameter("id", id));
if (objectQuery.Count() > 0)
return objectQuery.First();
throw new Exception("Not found");
}
public void Remove(TEntity entity)
{
this.objContext.DeleteObject(entity);
}
public void Update(TEntity entity)
{
// TODO
}
public IEnumerable<TEntity> FindBySpecification(Func<TEntity, bool> spec)
{
throw new NotImplementedException();
}
#endregion
#region Protected Properties
protected string EntitySetName
{
get { return this.entitySetName; }
}
protected ObjectContext ObjContext
{
get { return this.objContext; }
}
#endregion
}
|
从上面的代码可以看到,EdmRepository将实体框架抽象到ObjectContext这一层,这也使我们没法通过LINQ to Entities来查询模型中的对象。幸运的是,ObjectContext为我们提供了一系列函数,用以实现实体的CRUD。为了使用这些函数,我们需要知道与实体相关的EntitySetName,为此,我定义了一个AggregateRootAttribute,并将其应用在聚合根上,以便在对实体进行操作的时候,能够正确地获得EntitySetName。类似的代码如下:
[AggregateRoot("Customers")]
partial class Customer : IAggregateRoot
{
}
|
回头来看EdmRepository的构造函数,在构造函数中,我们使用.NET的反射机制获得了定义在聚合根类型上的EntitySetName
3. 使用IoC/DI(控制反转/依赖注入)框架,将仓储的实现(EdmRepository)注射到领域模型中。至此,领域模型一直保持着对仓储接口的引用,而对仓储的具体实现方式一无所知。由于IoC/DI的引入,我们得到了一个纯净的领域模型。在这里我也想提出一个衡量系统架构优劣度的重要指标,就是领域模型的纯净度。常见的 IoC/DI框架有Spring.NET和Castle Windsor MicroKernel。在本文的案例中,我采用了Castle Windsor。以下是针对Castle Windsor的配置文件片段:
<castle>
<components>
<!-- Object Context for Entity Data Model -->
<component id="ObjectContext"
service="System.Data.Objects.ObjectContext, System.Data.Entity, Version=4.0.0.0, Culture=neutral,
type="EasyCommerce.Domain.Model.EntitiesContainer, EasyCommerce.Domain"/>
<component id="CustomerRepository"
service="EasyCommerce.Domain.IRepository`1[[EasyCommerce.Domain.Model.Customer, EasyCommerce.Doma
type="EasyCommerce.Infrastructure.Repositories.EdmRepositories.EdmRepository`1[[EasyCommerce.Doma
<objContext>${ObjectContext}</objContext>
</component>
</components>
</castle>
|
通过这个配置片段我们还可以看到,在框架创建针对“客户”实体的仓储实例时,我们案例中的领域模型容器(EntitiesContainer)也以构造器注入的方式,被注射到了EdmRepository的构造函数中。接下来我们做一个单体测试:
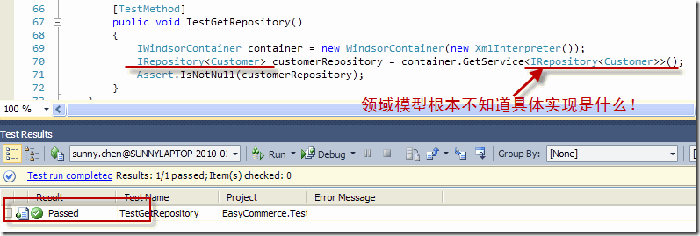
考察上面的代码,仓储的使用者(Client,可以是领域模型中的任何对象)对仓储的具体实现一无所知
总结
总之,仓储的实现可以用下图表述:
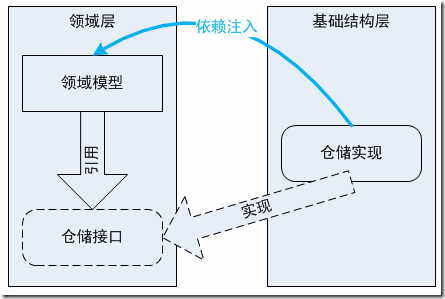
回头来看本文刚开始的三个问题:依赖注入可以解决问题1和3,而仓储接口的引入,也使得规约模式的应用成为可能。.NET中有一个泛型委托,称为Func<T, bool>,它可以作为LINQ的where子句参数,实现类似规约的功能。有关规约模式,我将在其它的文章中讨论。
从本文还可以了解到,依赖注入是维持领域模型纯净度的一大利器;另一大利器是领域事件,我将在后续的文章中详述。对于本文开始的第三个问题,也就是仓储实现的可扩展性,将在下篇文章中进行讨论,包括的内容有:事务处理和可扩展的仓储框架的实现。
仓储的实现:深入篇
早在年前的时候就已经在CSAI博客发表了上一篇文章:《仓储的实现:基础篇》。苦于日夜奔波于工作与生活之间,一直没有能够抽空继续探讨仓储的实现细节,也让很多关注EntityFramework和领域驱动设计的朋友们备感失望。
闲话不多说,现在继续考虑,如何让仓储的操作在相同的事物处理上下文中进行。DDD引入仓储模式,其目的之一就是能够通过仓储隐藏对象持久化的技术细节,使得领域模型变得更为“纯净”。由此可见,仓储的实现是需要基础结构层的组件支持的,表现为对数据库的操作。在传统的关系型数据库操作中,事务处理是一个很重要的概念,虽然从目前某些大型项目看,事务处理会降低效率,但它保证了数据的完整性。关系型数据库仍然是目前数据持久化机制的主流,事务处理的实现还是很有必要的。
为了迎合仓储模式,就需要对经典的ObjectContext使用方式作一些调整。比如,原本我们可以非常简单地使用using (EntitiesContainer ec = new EntitiesContainer())语句来界定LINQ to Entities的操作范围,并使用ObjectContext的SaveChanges成员方法提交事务,而在引入了仓储的实现中,就不能继续采用这种经典的使用方式。这让EntityFramework看上去变得很奇怪,也很牵强,我相信很多网友会批评我的做法,因为我把问题复杂化了。
其实,这应该是关注点不同罢了。关注EntityFramework的开发人员,自然觉得经典的调用方式简单明了,而从DDD的角度看呢?只能把关注点放在仓储上,而把EntityFramework当成是仓储的一种技术选型(当然从DDD角度讲,我们完全可以不选择EntityFramework,而去选择其它技术)。所以本文暂且抛开EntityFramework,继续在上文的基础上,讨论仓储的实现。
前面提到,仓储的实现需要考虑事务处理,而且根据DDD的经验,针对每一个聚合根,都需要有个仓储对其进行持久化以及对象重新组装等操作。为此,我的想法是,将仓储操作“界定”在某一个事务处理上下文(Context)中,仓储的实例是由Context获得的,这有点像EntityFramework中ObjectContext与EntityObject的关系那样。由于仓储是来自于transaction context,所以它知道目前处于哪个事务上下文中。我定义的这个transaction context如下:
public interface IRepositoryTransactionContext : IDisposable
{
IRepository<TEntity> GetRepository<TEntity>()
where TEntity : EntityObject, IAggregateRoot;
void BeginTransaction();
void Commit();
void Rollback();
}
|
上面第三行代码定义了一个接口方法,这个方法的主要作用就是返回一个针对指定聚合根实体的仓储实例。剩下那三行代码就很明显了,那是标准的transaction操作:启动事务、提交事务以及回滚事务。
在设计上,可以根据需要,选择合适的技术来实现IRepositoryTransactionContext。我们现在讨论的是EntityFramework,所以我将给出EntityFramework的具体实现。当然,如果你不选用EntityFramework,而是用NHibernate实现数据持久化,这样的设计同样能够使你达到目的。以下是基于EntityFramework的实现:EdmRepositoryTransactionContext的伪代码。
internal class EdmRepositoryTransactionContext : IRepositoryTransactionContext
{
private ObjectContext objContext;
private Dictionary<Type, object> repositoryCache = new Dictionary<Type, object>();
public EdmRepositoryTransactionContext(ObjectContext objContext)
{
this.objContext = objContext;
}
#region IRepositoryTransactionContext Members
public IRepository<TEntity> GetRepository<TEntity>() where TEntity : EntityObject, IAggregateRoot
{
if (repositoryCache.ContainsKey(typeof(TEntity)))
{
return (IRepository<TEntity>)repositoryCache[typeof(TEntity)];
}
IRepository<TEntity> repository = new EdmRepository<TEntity>(this.objContext);
this.repositoryCache.Add(typeof(TEntity), repository);
return repository;
}
public void BeginTransaction()
{
// We do not need to begin a transaction here because the object context,
// which would handle the transaction, was created and injected into the
// constructor by Castle Windsor framework.
}
public void Commit()
{
this.objContext.SaveChanges();
}
public void Rollback()
{
// We also do not need to perform the rollback operation because
// entity framework will handle this for us, just when the execution
// point is stepping out of the using scope.
}
#endregion
#region IDisposable Members
public void Dispose()
{
this.repositoryCache.Clear();
this.objContext.Dispose();
}
#endregion
}
|
EdmRepositoryTransactionContext被定义为internal,这个设计是合理的,因为Domain层是不需要知道事务上下文的具体实现,它将会被IoC/DI容器注入到Domain层中(本系列文章采用Castle Windsor框架)。在EdmRepositoryTransactionContext的构造函数中,它需要EntityFramework的ObjectContext对象来初始化实例。同样,由于IoC/DI的使用,我们在代码中也是不需要去创建这个ObjectContext的,交给Castle Windsor就OK了。第13行的GetRepository方法简单地采用了Dictionary对象来实现缓存仓储实例的效果,当然这种做法还有待改进。
EdmRepositoryTransactionContext是不需要BeginTransaction的,我们将方法置空,因为EntityFramework的事务会由ObjectContext来管理,同理,Rollback也被置空。
EdmRepository的实现就比较显而易见了,请参见上文。
此外,我们还可以针对NHibernate实现仓储模式,只需要实现IRepositoryTransactionContext和IRepository接口即可,比如:
internal class NHibernateRepositoryTransactionContext : IRepositoryTransactionContext
{
ITransaction transaction;
Dictionary<Type, object> repositoryCache = new Dictionary<Type, object>();
public ISession Session { get { return DatabaseSessionFactory.Instance.Session; } }
#region IRepositoryTransactionContext Members
public IRepository<TEntity> GetRepository<TEntity>()
where TEntity : EntityObject, IAggregateRoot
{
if (repositoryCache.ContainsKey(typeof(TEntity)))
{
return (IRepository<TEntity>)repositoryCache[typeof(TEntity)];
}
IRepository<TEntity> repository = new NHibernateRepository<TEntity>(this.Session);
this.repositoryCache.Add(typeof(TEntity), repository);
return repository;
}
public void BeginTransaction()
{
transaction = DatabaseSessionFactory.Instance.Session.BeginTransaction();
}
public void Commit()
{
transaction.Commit();
}
public void Rollback()
{
transaction.Rollback();
}
#endregion
#region IDisposable Members
public void Dispose()
{
transaction.Dispose();
ISession dbSession = DatabaseSessionFactory.Instance.Session;
if (dbSession != null && dbSession.IsOpen)
dbSession.Close();
}
#endregion
}
|
internal class NHibernateRepository<TEntity> : IRepository<TEntity>
where TEntity : EntityObject, IAggregateRoot
{
ISession session;
public NHibernateRepository(ISession session)
{
this.session = session;
}
#region IRepository<TEntity> Members
public void Add(TEntity entity)
{
this.session.Save(entity);
}
public TEntity GetByKey(int id)
{
return (TEntity)this.session.Get(typeof(TEntity), id);
}
public IEnumerable<TEntity> FindBySpecification(Func<TEntity, bool> spec)
{
throw new NotImplementedException();
}
public void Remove(TEntity entity)
{
this.session.Delete(entity);
}
public void Update(TEntity entity)
{
this.session.SaveOrUpdate(entity);
}
#endregion
}
|
在NHibernateRepositoryTransactionContext中使用了一个DatabaseSessionFactory的类,该类主要用于管理NHibernate的Session对象,具体实现如下(该实现已被用于我的Apworks应用开发框架原型中):
/// <summary>
/// Represents the factory singleton for database session.
/// </summary>
internal sealed class DatabaseSessionFactory
{
#region Private Static Fields
/// <summary>
/// The singleton instance of the database session factory.
/// </summary>
private static readonly DatabaseSessionFactory databaseSessionFactory = new DatabaseSessionFactory();
#endregion
#region Private Fields
/// <summary>
/// The session factory instance.
/// </summary>
private ISessionFactory sessionFactory = null;
/// <summary>
/// The session instance.
/// </summary>
private ISession session = null;
#endregion
#region Constructors
/// <summary>
/// Privately constructs the database session factory instance, configures the
/// NHibernate framework by using the assemblies listed in the configured spaces(paths)
/// that are decorated by <see cref="EntityVisibleAttribute"/>.
/// </summary>
private DatabaseSessionFactory()
{
Configuration nhibernateConfig = new Configuration();
nhibernateConfig.Configure();
nhibernateConfig.AddAssembly(typeof(IAggregateRoot).Assembly);
sessionFactory = nhibernateConfig.BuildSessionFactory();
}
#endregion
#region Public Properties
/// <summary>
/// Gets the singleton instance of the database session factory.
/// </summary>
public static DatabaseSessionFactory Instance
{
get
{
return databaseSessionFactory;
}
}
/// <summary>
/// Gets the singleton instance of the session. If the session has not been
/// initialized or opened, it will return a newly opened session from the session factory.
/// </summary>
public ISession Session
{
get
{
ISession result = session;
if (result != null && result.IsOpen)
return result;
return OpenSession();
}
}
#endregion
#region Public Methods
/// <summary>
/// Always opens a new session from the session factory.
/// </summary>
/// <returns>The newly opened session.</returns>
public ISession OpenSession()
{
this.session = sessionFactory.OpenSession();
return this.session;
}
#endregion
}
|
简单小结一下。通过上面的例子可以看到,仓储的实现是不能依赖于任何技术细节的,因为领域模型并不关心技术问题。这并不是DDD一书中怎么说,我们就得怎么做。事实上的确如此,因为DDD的思想,使得我们应该把关注点放在业务分析与领域建模上,而仓储实现的分离正是这一思想的具体表现形式。不管怎么样,采用其它的手段也罢,我们还是应该遵循“将关注点放在领域”这一宗旨。
接下来看如何在领域层结合IoC框架使用仓储。仍然以Castle Windsor为例。配置文件如下(超长部分我用省略号去掉了):
<castle>
<components>
<!-- Object Context for Entity Data Model -->
<component id="ObjectContext"
service="System.Data.Objects.ObjectContext, System.Data.Entity, Version=4.0.0.0,......"
type="EasyCommerce.Domain.Model.EntitiesContainer, EasyCommerce.Domain"/>
<component id="GeneralRepository"
service="EasyCommerce.Domain.IRepository`1[[EasyCommerce.Domain.Model.Customer, ......"
type="EasyCommerce.Infrastructure.Repositories.EdmRepositories.EdmRepository`1[[EasyCo......">
<objContext>${ObjectContext}</objContext>
</component>
<component id="TransactionContext"
service="EasyCommerce.Domain.IRepositoryTransactionContext, EasyCommerce.Domain......"
type="EasyCommerce.Infrastructure.Repositories.EdmRepositories.EdmRepositoryTransactionContext, ...">
</component>
</components>
</castle>
|
以下是调用代码:
[TestMethod]
public void TestCreateCustomer()
{
IWindsorContainer container = new WindsorContainer(new XmlInterpreter());
using (IRepositoryTransactionContext tx = container.GetService<IRepositoryTransactionContext>())
{
tx.BeginTransaction();
try
{
Customer customer = Customer.CreateCustomer("daxnet", "12345",
new Name { FirstName = "Sunny", LastName = "Chen" },
new Address(), new Address(), DateTime.Now.AddYears(-29));
IRepository<Customer> customerRepository = tx.GetRepository<Customer>();
customerRepository.Add(customer);
tx.Commit();
}
catch
{
tx.Rollback();
throw;
}
}
}
|
测试结果及数据库数据结果:

【注意】:在使用NHibernate的仓储实现时,由于NHibernate的延迟加载特性,需要将实体的属性设置为virtual,以便由NHibernate产生Proxy Class进而实现延迟加载;但是由EntityFramework自动生成的源代码并不会将实体属性设置为virtual,而采用partial class也无法解决这个问题。因此需要在代码生成技术上做文章。我的做法是,针对edmx产生一个基于T4的代码生成模板,然后修改这个模板,分别在WritePrimitiveTypeProperty和WriteComplexTypeProperty方法中的适当位置加上virtual关键字:
private void WritePrimitiveTypeProperty(EdmProperty primitiveProperty, CodeGenerationTools code)
{
MetadataTools ef = new MetadataTools(this);
#>
/// <summary>
/// <#=SummaryComment(primitiveProperty)#>
/// </summary><#=LongDescriptionCommentElement(primitiveProperty, 1)#>
[EdmScalarPropertyAttribute(EntityKeyProperty=<#=code.CreateLiteral(ef.IsKey(primitiveProperty))#>,
IsNullable=<#=code.CreateLiteral(ef.IsNullable(primitiveProperty))#>)]
[DataMemberAttribute()]
<#=code.SpaceAfter(NewModifier(primitiveProperty))#><#=Accessibility.ForProperty(primitiveProperty)#> virtual
<#=code.Escape(primitiveProperty.TypeUsage)#> <#=code.Escape(primitiveProperty)#>
{
<#=code.SpaceAfter(Accessibility.ForGetter(primitiveProperty))#>get
{
<#+ if (ef.ClrType(primitiveProperty.TypeUsage) == typeof(byte[]))
{
#>
return StructuralObject.GetValidValue(<#=code.FieldName(primitiveProperty)#>);
|
private void WriteComplexTypeProperty(EdmProperty complexProperty, CodeGenerationTools code)
{
#>
/// <summary>
/// <#=SummaryComment(complexProperty)#>
/// </summary><#=LongDescriptionCommentElement(complexProperty, 1)#>
[EdmComplexPropertyAttribute()]
[DesignerSerializationVisibility(DesignerSerializationVisibility.Content)]
[XmlElement(IsNullable=true)]
[SoapElement(IsNullable=true)]
[DataMemberAttribute()]
<#=code.SpaceAfter(NewModifier(complexProperty))#><#=Accessibility.ForProperty(complexProperty)#> virtual
<#=MultiSchemaEscape(complexProperty.TypeUsage, code)#><#=code.Escape(complexProperty)#>
{
<#=code.SpaceAfter(Accessibility.ForGetter(complexProperty))#>get
{
<#=code.FieldName(complexProperty)#> = GetValidValue(<#=code.FieldName(complexProperty)#>,
"<#=complexProperty.Name#>",
false, <#=InitializedTrackingField(complexProperty, code)#>);
<#=InitializedTrackingField(complexProperty, code)#> = true;
|
始终坚持一个原则:不要在生成的代码上直接修改,一是工作量巨大,另一方面就是,代码是自动生成的,今后模型修改了,代码将会重新生成。
规约(Specification)模式
本来针对规约模式的讨论,我并没有想将其列入本系列文章,因为这是一种概念性的东西,从理论上讲,与EntityFramework好像扯不上关系。但应广大网友的要求,我决定还是在这里讨论一下规约模式,并介绍一种专门针对.NET Framework的规约模式实现。
很多时候,我们都会看到类似下面的设计:
public interface ICustomerRespository
{
Customer GetByName(string name);
Customer GetByUserName(string userName);
IList<Customer> GetAllRetired();
}
|
接下来的一步就是实现这个接口,并在类中分别实现接口中的方法。很明显,在这个接口中,Customer仓储一共做了三个操作:通过姓名获取客户信息;通过用户名获取客户信息以及获得所有当前已退休客户的信息。这样的设计有一个好处就是一目了然,能够很方便地看到Customer仓储到底提供了哪些功能。文档化的开发方式特别喜欢这样的设计。
还是那句话,应需而变。如果你的系统很简单,并且今后扩展的可能性不大,那么这样的设计是简洁高效的。但如果你正在设计一个中大型系统,那么,下面的问题就会让你感到困惑:
规约模式就是DDD引入用来解决以上问题的一种特殊的模式。规约是一种布尔断言,它表述了给定的对象是否满足当前约定的语义。经典的规约模式实现中,规约类只有一个方法,就是IsSatisifedBy(object);如下:
public class Specification
{
public virtual bool IsSatisifedBy(object obj)
{
return true;
}
}
|
还是先看例子吧。在引入规约以后,上面的代码就可以修改为:
public interface ICustomerRepository
{
Customer GetBySpecification(Specification spec);
IList<Customer> GetAllBySpecification(Specification spec);
}
public class NameSpecification : Specification
{
protected string name;
public NameSpecification(string name) { this.name = name; }
public override bool IsSatisifedBy(object obj)
{
return (obj as Customer).FirstName.Equals(name);
}
}
public class UserNameSpecification : NameSpecification
{
public UserNameSpecification(string name) : base(name) { }
public override bool IsSatisifedBy(object obj)
{
return (obj as Customer).UserName.Equals(this.name);
}
}
public class RetiredSpecification : Specification
{
public override bool IsSatisifedBy(object obj)
{
return (obj as Customer).Age >= 60;
}
}
public class Program1
{
static void Main(string[] args)
{
ICustomerRepository cr; // = new CustomerRepository();
Customer getByNameCustomer = cr.GetBySpecification(new NameSpecification("Sunny"));
Customer getByUserNameCustomer = cr.GetBySpecification(new UserNameSpecification("daxnet"));
IList<Customer> getRetiredCustomers = cr.GetAllBySpecification(new RetiredSpecification());
}
}
|
通过使用规约,我们将Customer仓储中所有“特定用途的操作”全部去掉了,取而代之的是两个非常简洁的方法:分别通过规约来获得Customer实体和实体集合。规约模式解耦了仓储操作与断言条件,今后我们需要通过仓储实现其它特定条件的查询时,只需要定制我们的Specification,并将其注入仓储即可,仓储的实现无需任何修改。与此同时,规约的引入,使得我们很清晰地了解到,某一次查询过滤,或者某一次数据校验是以什么样的规则实现的,这给断言条件的设计与实现带来了可测试性。
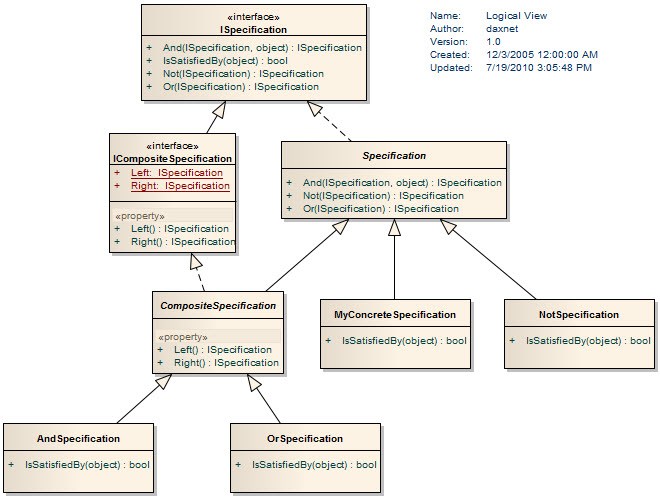
为了实现复合断言,通常在设计中引入复合规约对象。这样做的好处是,可以充分利用规约的复合来实现复杂的规约组合以及规约树的遍历。不仅如此,在.NET 3.5引入Expression Tree以后,规约将有其特定的实现方式,这个我们在后面讨论。以下是一个经典的实现方式,注意ICompositeSpecification接口,它包含两个属性:Left和Right,ICompositeSpecification是继承于ISpecification接口的,而Left和Right本身也是ISpecification类型,于是,整个Specification的结构就可以看成是一种树状结构。
还记得在《EntityFramework之领域驱动设计实践(八)- 仓储的实现:基本篇》里提到的仓储接口设计吗?当初还没有牵涉到任何Specification的概念,所以,仓储的FindBySpecification方法采用.NET的Func<TEntity, bool>委托作为Specification的声明。现在我们引入了Specification的设计,于是,仓储接口可以改为:
public interface IRepository<TEntity>
where TEntity : EntityObject, IAggregateRoot
{
void Add(TEntity entity);
TEntity GetByKey(int id);
IEnumerable<TEntity> FindBySpecification(ISpecification spec);
void Remove(TEntity entity);
void Update(TEntity entity);
}
|
针对规约模式实现的讨论,我们才刚刚开始。现在,又出现了下面的问题:
基于.NET的Specification可以使用LINQ Expression(下面简称Expression)来解决上面所有的问题。为了引入Expression,我们需要对ISpecification的设计做点点修改。代码如下:
public interface ISpecification
{
bool IsSatisfiedBy(object obj);
Expression<Func<object, bool>> Expression { get; }
// Other member goes here...
}
public abstract class Specification : ISpecification
{
#region ISpecification Members
public bool IsSatisfiedBy(object obj)
{
return this.Expression.Compile()(obj);
}
public abstract Expression<Func<object, bool>> Expression { get; }
#endregion
}
|
仅仅引入一个Expression<Func<object, bool>>属性,就解决了上面的问题。在实际应用中,我们实现Specification类的时候,由原来的“实现IsSatisfiedBy方法”转变为“实现Expression<Func<object, bool>>属性”。现在主流的.NET对象持久化机制(比如EntityFramework,NHibernate,Db4o等等)都支持LINQ接口,于是:
public abstract class Specification : ISpecification
{
// ISpecification implementation omitted
public static ISpecification Eval(Expression<Func<object, bool>> expression)
{
return new ExpressionSpec(expression);
}
}
internal class ExpressionSpec : Specification
{
private Expression<Func<object, bool>> exp;
public ExpressionSpec(Expression<Func<object, bool>> expression)
{
this.exp = expression;
}
public override Expression<Func<object, bool>> Expression
{
get { return this.exp; }
}
}
class Client
{
static void CallSpec()
{
ISpecification spec = Specification.Eval(o => (o as Customer).UserName.Equals("daxnet"));
// spec....
}
}
|
下图是基于LINQ Expression的Specification设计的完整类图。与经典Specification模式的实现相比,除了LINQ Expression的引入外,本设计中采用了IEntity泛型约束,用于将Specification的操作约束在领域实体上,同时也提供了强类型支持。
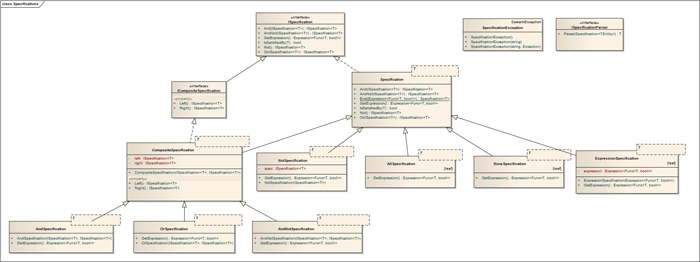
上图的右上角有个ISpecificationParser的接口,它主要用于将Specification解析为某一持久化框架可以认识的对象,比如LINQ Expression或者NHibernate的Criteria。当然,在引入LINQ Expression的Specification中,这个接口是可以不去实现的;而对于NHibernate,我们可以借助NHibernate.Linq命名空间来实现这个接口,从而将Specification转换为NHibernate Criteria。相关代码如下:
internal sealed class NHibernateSpecificationParser : ISpecificationParser<ICriteria>
{
ISession session;
public NHibernateSpecificationParser(ISession session)
{
this.session = session;
}
#region ISpecificationParser<Expression> Members
public ICriteria Parse<TEntity>(ISpecification<TEntity> specification)
where TEntity : class, IEntity
{
var query = this.session.Linq<TEntity>().Where(specification.GetExpression());
//Expression<Func<TEntity, bool>> exp = obj => specification.IsSatisfiedBy(obj);
//var query = this.session.Linq<TEntity>().Where(exp);
System.Linq.Expressions.Expression expression = query.Expression;
expression = Evaluator.PartialEval(expression);
expression = new BinaryBooleanReducer().Visit(expression);
expression = new AssociationVisitor((ISessionFactoryImplementor)this.session.SessionFactory)
.Visit(expression);
expression = new InheritanceVisitor().Visit(expression);
expression = CollectionAliasVisitor.AssignCollectionAccessAliases(expression);
expression = new PropertyToMethodVisitor().Visit(expression);
expression = new BinaryExpressionOrderer().Visit(expression);
NHibernateQueryTranslator translator = new NHibernateQueryTranslator(this.session);
var results = translator.Translate(expression, ((INHibernateQueryable)query).QueryOptions);
ICriteria ca = results as ICriteria;
return ca;
}
#endregion
}
|
其实,Specification相关的话题远不止本文所讨论的这些,更多内容需要我们在实践中发掘、思考。本文也只是对规约模式及其在.NET中的实现作了简要的讨论,文中也会存在欠考虑的地方,欢迎各位网友各抒己见,提出宝贵意见。
EntityFramework之领域驱动设计实践【扩展阅读】:服务(Services)
服务(Services)
从本讲开始,所涉及的DDD话题可能与EntityFramework关系不大了。网友千万别骂我是标题党,呵呵。由于这部分内容并非是特定于EntityFramework的,更多的是在介绍模式及实践心得,所以EntityFramework的内容就会偏少了。为了使得针对一些话题的讨论能够延续下去,我仍然将这些文章安排在本系列中,希望读者朋友能够谅解。我也在标题中标注了【扩展阅读】,表示所讨论的内容已经不仅仅局限于EntityFramework了。
为了表示补偿,透露一下EntityFramework 4.0的最新特性:EF CTP 4.0在“代码优先”开发模式以及提升开发生产率方面做了重要改进。EF CTP 4.0引入了两种新的类型:DbContext和DbSet。DbContext是ObjectContext的简化版。详情请见http://www.infoq.com/news/2010/07/EF-CTP-4。
言归正传,本文将对DDD中的又一重要角色:服务(Services)做一些简单的介绍。提起服务,很多朋友都会想到“SOA”。而在领域驱动设计里,服务贯穿于整个系统的各个层面。根据应用系统的领域驱动分层思想,服务被归类为:应用层服务、领域服务以及基础结构层服务。应用层服务为表现层提供接口,根据DDD的思想,应用层很薄,不承担任何业务逻辑的处理,仅仅是起到coordination的作用。因此,应用层服务也不会牵涉到业务逻辑。在CQRS模式中,Command Service以及Query Service就是应用层服务。基础结构层服务是显而易见的,比如,邮件发送服务、数据服务、事件总线等等。这些服务是与领域无关的,只跟技术实现相关。假想这样一个例子:将货物从仓库A转移到仓库B,如果转仓成功,则向仓库管理员及操作员发送SMS。这是仓储管理领域常见的业务需求,经典的写法类似如下:
public class TransferService : IDomainService
{
public void Transfer(Warehouse a,
Warehouse b,
Item item, Qty qty)
{
using (IRepositoryTransactionContext ctx = Ioc.GetService())
{
Inventory oItemInA = a.GetInventory(item);
if (oItemInA.Qty < qty)
{
// raise not enough inventory event or exception
throw new Exception();
}
Inventory oItemInB = b.GetInventory(item);
if (oItemInB == null)
oItemInB = b.CreateInventory(item);
oItemInA.Qty -= qty;
oItemInB.Qty += qty;
ctx.SaveChanges();
}
}
}
|
在上面的伪代码中,我们已经看到了领域服务(Domain Service)的影子。在DDD里,领域服务用以处理那种“放在哪里都不合适”的业务逻辑。比如上面的转仓业务,从面向对象的角度看,既不是仓库应有的操作,也不是货物(Item)的行为。为了明确领域对象的职责,DDD将这样的业务逻辑“抽”出来,置于领域服务当中。对于发送SMS的需求,就需要由应用层服务通过“协调”进行处理了。比如:在调用了领域服务并获得响应以后,根据响应结果以及外部配置信息,进而调用基础结构层服务(SMSService)实现SMS的发送。
看到这里你会发现,其实哪些业务应该放在实体中,哪些需要使用服务来处理,并没有一个绝对的标准。还是那句老话:凭经验。你还会发现,如果从实体将业务逻辑全部“抽”到服务里,实体将成为仅包含getter/setter的对象,于是贫血模型产生了。正因为DDD提倡面向领域,并将通用语言和领域模型摆在很重要的位置,因此,DDD是不主张贫血模型的。
个人认为,领域服务的引入,增加了模型的抗需求变更的能力。我们可以通过需求分析,找出业务逻辑中易变的部分,以领域服务的方式“注入”到领域模型中,今后若有需求变更,则可以无需更改任何现有组件,完成业务处理逻辑的改变。[TBD: 这样的想法还有待进一步证实]
有关领域服务的内容,本文暂且讨论这些。读者朋友可以在实践中提出问题,然后在此与大家分享讨论。本文还引出了一个话题,就是应用层服务的协调问题。比如,本文的例子中,是在应用层服务中调用SMSService实现SMS发送,如果直接将这部分内容写在应用层服务中,势必降低系统的扩展性。比如,今后希望不仅要发送SMS,而且还要发送Email。DDD的解决方案是引入事件模型。在完成转仓操作时,向事件总线(Event Bus)发送事件,由事件订阅者Subscriber捕获并处理(Handle)事件。于是,今后我们只需要实现一个“WarehouseTransferSendEmailEventHandler”的事件处理器,并在Handle Event的调用中,向相关人员发送Email即可。NServiceBus就是一款经典的基于.NET的企业级应用通信的框架,在基于事件的DDD架构中,NServiceBus发挥了重要作用。
从下一讲开始,我将着重讨论领域事件以及Event Sourcing,并对DDD的CQRS模式作个引子。
EntityFramework之领域驱动设计实践【扩展阅读】:CQRS体系结构模式
CQRS体系结构模式
本文将对CQRS(Command Query Responsibility Segregation,命令查询职责分离)模式做一个相对全面的介绍。可以这么说,CQRS打破了经典的领域驱动设计实践,在应用CQRS的整个过程中,你将会以另一种不同的角度去考虑问题并寻求解决方案。比如,CQRS是事件驱动的体系结构,事件是如何产生如何分发又是如何处理的?事件驱动的体系结构适用于哪些类型的应用系统?CQRS中的仓储,与经典DDD中的仓储又有何异同?等等这些问题,都给我们留下了无限的思考空间。
背景
在讲CQRS之前,我们先了解一下CQS(Command-Query Separation,命令查询)模式。名字上看,两者没什么差别,然而CQRS应该说是,在DDD的实践中引入CQS理论而出现的一种体系结构模式。CQS模式最早由著名软件大师Bertrand Meyer(Eiffel语言之父,面向对象开-闭原则OCP提出者)提出,他认为,对象的行为仅有两种:命令和查询,不存在第三种情况。用他自己的话来说,就是:“提问永远无法改变答案”。根据CQS,任何方法都可以拆分为命令和查询两个部分。比如,下面的代码:
private int i = 0;
private int Add(int factor)
{
i += factor;
return i;
}
|
可以替换为:
private void AddCommand(int factor)
{
i += factor;
}
private int QueryValue()
{
return i;
}
|
当命令和查询被分离的时候,我们将会有更多的机会去把握整个事情的细节。比如我们可以对系统的“命令”部分和“查询”部分分别采用不同的技术架构,以使得系统具有更好的扩展性,并获得更好的性能。在DDD领域中,Greg Young和Eric Evans根据Bertrand Meyer的CQS模式,结合实际项目经验,总结了CQRS体系结构模式。
结构
整个系统结构被分为两个部分:命令部分和查询部分。我根据自己的体会,描绘了CQRS的体系结构简图如下,供大家参考。在讨论CQRS体系结构之前,我们有必要事先弄清楚这样几个概念:对象状态、事件溯源(Event Sourcing)、快照(Snapshots)以及事件存储(Event Store)。讨论的过程中你会发现,很多概念与我们之前对经典DDD的理解相比,有着很大的不同。
对象状态
这是一个大家耳熟能详的概念了。什么是对象状态?在被面向对象编程(OOP)“熏陶”了很久的朋友,一听到“对象状态”,马上想到了一对对的getter/setter属性。尤其是.NET程序员,在C# 3.0及以后版本中,引入了Auto-Property的概念,于是,对象的属性就很容易地成为了对象状态的代名词。在这里,我们应该看到问题的本质,即使是Auto-Property,它也无非是对对象字段的一种封装,只不过在使用Auto-Property的时候,C#编译器会在后台创建一个私有的、匿名的字段(field),而Property则成为了从外部访问该字段的唯一途径。换句话说,对象的状态是保存在这些字段里的,对象属性无非是访问字段的facade。在这里澄清这样一个事实,就是为了当你继续阅读本文的时候,不至于对事件溯源(Event Sourcing)的某些具体实现感到困惑。在Event Sourcing的具体实现中,领域对象不再需要具备公有的属性,至少外界无法通过公有属性改变对象状态(即setter被定义为private,甚至没有setter)。这与经典的DDD设计相比,无疑是一个重大改变。例如,现在我要改变某个Customer的状态,如果采用经典DDD的实现方式,就是:
[TestMethod]
public void TestChangeCustomerName()
{
IocContainer c = IocContainer.GetIocContainer();
using (IRepositoryTransactionContext ctx = c.GetService<IRepositoryTransactionContext>())
{
IRepository<Customer> customerRepository = ctx.GetRepository<Customer>();
Customer customer = customerRepository
.Get(Specification<Customer>
.Eval(p=>p.FirstName.Equals("sunny") && p.LastName.Equals("chen")));
// Here we use the properties directly to update the state
customer.FirstName = "dax";
customer.LastName = "net";
customerRepository.Update(customer);
ctx.Commit();
}
}
|
现在,很多ORM工具都需要聚合根具有public的getter/setter,这本身就是技术实现上的一种约束,比如某些ORM工具会使用reflection,通过读写对象的property来改变对象状态。为什么ORM工具要选择properties,而不是fields?因为这些框架不希望自己的介入会改变对象对其状态的封装级别(也就是访问限制)。在引入CQRS后,ORM已经没有太多的用武之地了,当然从技术选型的角度看,你仍然可以选择ORM,但就像关系型数据库那样,它已经显得没那么重要了。
事件溯源(Event Sourcing)
在某些情况下,我们不仅需要知道对象的当前状态是什么,而且还需要知道,对象经历了哪些路程,才获得了当前这样的状态。Martin Fowler在介绍Event Sourcing的时候,举了个邮包跟踪(Package Tracking)的例子。在经典的DDD实践中,我们只能通过Shipment.Location来获得邮包的当前位置,却没办法获得邮包经历过哪些地址而最终到达当前的地址。
为了使我们的业务系统具有记录对象历史状态的能力,我们使用事件驱动的领域模型来实现我们的业务系统。简而言之,就是对模型对象状态的修改,仅允许通过事件的途径实现,外界无法通过任何其他途径修改对象的状态。那么,记录对象的状态修改历史,就只需要记录事件的类型以及发生顺序即可,因为对象的状态是由领域事件更改的。于是,也就能理解上面所讲的为什么在Event Sourcing的实现中,领域对象将不再具有公有属性,或者说,至少不再具有公有的setter属性。
当对象的状态被修改后,我们可能希望将对象保存到持久化机制,这一点与经典的DDD实践上的考虑是类似的。而与之不同的是,现在我们保存的已不再是某个领域对象在某个时间点上的状态,而是促使对象将其状态改变到当前点的一系列事件。由此,仓储(Repository)的实现需要发生变化,它需要有保存领域事件的功能,同时还需要有通过一系列保存的事件数据,重建聚合根的能力。看到这里,你就知道为什么会有Event Sourcing这个概念了:所谓Event Sourcing,就是“通过事件追溯对象状态的起源(与经过)”,它允许你通过记录下来的事件,将你的领域模型恢复到之前任意一个时间点。你可能会兴奋地说:我的领域模型开始支持事件回放与模型重建了!
Event Sourcing让我们“透过现象看本质”,使我们更进一步地了解到“对象持久化”的具体含义,其实也就是对象状态的持久化。只不过,Event Sourcing并不是直接保存了对象的状态,而是一系列引起状态变化的领域事件。
仍然以上面的更改客户姓名为例,在引入领域事件与Event Sourcing之后,整个模型的结构发生了变化,以下是相关代码,仅供参考。
[Serializable]
public partial class CustomerCreatedEvent : DomainEvent
{
public string UserName { get; set; }
public string Password { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime DayOfBirth { get; set; }
}
[Serializable]
public partial class ChangeNameEvent : DomainEvent
{
public string FirstName{get;set;}
public string LastName{get;set;}
}
public partial class Customer : SourcedAggregationRoot
{
private DateTime dayOfBirth;
private string userName;
private string password;
private string firstName;
private string lastName;
public Customer(string userName, string password,
string firstName, string lastName, DateTime dayOfBirth)
{
this.RaiseEvent<CustomerCreatedEvent>(new CustomerCreatedEvent
{
DayOfBirth = dayOfBirth,
FirstName = firstName,
LastName = lastName,
UserName = userName,
Password = password
});
}
public void ChangeName(string firstName, string lastName)
{
this.RaiseEvent<ChangeNameEvent>(new ChangeNameEvent
{
FirstName = firstName,
LastName = lastName
});
}
// Handles the ChangeNameEvent by using Reflection
[Handles(typeof(ChangeNameEvent))]
private void DoChangeName(ChangeNameEvent e)
{
this.firstName = e.FirstName;
this.lastName = e.LastName;
}
// Handles the CustomerCreatedEvent by using Reflection
[Handles(typeof(CustomerCreatedEvent))]
private void DoCreateCustomer(CustomerCreatedEvent e)
{
this.firstName = e.FirstName;
this.lastName = e.LastName;
this.userName = e.UserName;
this.password = e.Password;
this.dayOfBirth = e.DayOfBirth;
}
}
|
上面的代码中定义了两个Domain Event:CustomerCreatedEvent和ChangeNameEvent。在Customer聚合根的构造函数中,直接触发CustomerCreatedEvent以便该事件的订阅者对Customer对象进行初始化;而在Customer聚合根的ChangeName方法中,则直接触发ChangeNameEvent以便该事件的订阅者对Customer的first name和last name作修改。Customer的基类SourcedAggregationRoot则在领域事件被触发的时候通过Reflection机制获得内部的事件处理函数,并调用该函数完成事件处理。在上面的例子中,也就是DoChangeName和DoCreateCustomer这两个方法。在这里需要注意的是,类似DoChangeName和DoCreateCustomer这样的事件处理函数中,仅允许包含对对象状态的设置逻辑。因为如果引入其它操作的话,很难保证通过这些操作,对象的状态不会发生改变。
深入思考上面的设计会发现一个问题,也就是当模型对象变得非常庞大,或者随着时间的推移,领域事件将变得越来越多,于是通过Event Sourcing来重建聚合根的过程也会变得越来越耗时,因为每一次从建都需要从最早发生的事件开始。为了解决这个问题,Event Sourcing引入了“快照(Snapshots)”。
快照(Snapshots)
Snapshot的设计其实很简单。标准的CQRS实现中,采用“每产生N个领域事件,则对对象做一次Snapshot”的简单规则。设计人员其实可以根据自己的实际情况定义N的取值,甚至可以选用特定的Snapshot规则,以提高对象重建的效率。当需要通过仓储获得某一个聚合根实体时,仓储会首先从Snapshot Store中获得最近一次的快照,然后再在由此快照还原的聚合根实体上逐个应用快照之后所产生的领域事件,由此大大加速了对象重建的过程。快照通常采用GoF Memento模式实现。请注意:CQRS引入快照的概念仅仅是为了解决对象重建的效率问题,它并不能替代领域事件所能表述的含义。换句话说,即使引入快照,也不能表示我们能够将快照之前的所有事件从事件存储(Event Store)中删除。因为,我们记录领域事件的目的,是为了Event Sourcing,而不是Snapshots。
事件存储(Event Store)
通常,事件存储是一个关系型数据库,用来保存引起领域对象状态更改的所有领域事件。如上所述,在CQRS结构的系统实现中,数据库已经不再直接保存对象的当前状态了,保存的只是引起对象状态发生变化的领域事件。于是,数据库的数据结构非常单一,就是单纯的领域事件数据。事件数据的写入、读取都变得非常简单高速,根本无需ORM的介入,直接使用SQL或者存储过程操作事件存储即可,既简单又高效。读到这里,你会发现,虽然系统是用的一个称之为Event Store的机制保存了领域事件,但这个Event Store已经成为了整个系统数据存储的核心。更进一步考虑,Event Store中的事件数据是在仓储执行“保存”操作时,从领域模型中收集并写入的,也就意味着,最新的、最真实的数据仍然存在于领域模型中,正好符合DDD面向领域的思想,同时也引出了另一深层次的考虑:In Memory Domain!
回到结构
在完成对“对象状态”、“事件溯源(Event Sourcing)”、“快照(Snapshots)”以及“事件存储(Event Store)”的讨论后,我们再来看整个CQRS的结构,这样就显得更加清楚。上文【CQRS体系结构模式】图中,用户操作被分为命令部分(图中上半部分)和查询部分(图中下半部分)。
总结
本文介绍了CQRS模式的基本结构,并对其中一些重要概念作了注释,也是我在实践和思考当中总结出来的内容(PS:转载请注明出处)。学习过DDD而刚刚开始CQRS的朋友,在阅读一些资料的时候势必会感到疑惑,希望本文能够帮助到这些朋友。比如最开始阅读的时候,我也不知道为什么一定要通过领域事件去更改对象状态,而不是在对象状态变更的时候,去触发领域事件,因为当时我仍然希望能够在Domain Model中方便地使用getter/setter,我当时也希望能够让Domain Model同时适应于经典DDD和CQRS架构。在经过多次尝试后发现,这种做法是不合理、不可取的,也正如Udi Dahan所说:CQRS是一种模式,既然是模式,就是用来解决特定问题的。
还是一句老话:视需求而定。不要因为CQRS所以CQRS。虽然可以很大程度地提升系统性能,虽然可以使系统具有auditing的能力,虽然可以实现Domain-Centralized,虽然可以让数据存储变得更加简单,虽然给我们提供了很多技术选型的机会,但是,CQRS也有很多不足点,比如结构实现较繁杂,数据同步稳定性难以得到保证,事件溯源(Event Sourcing)出错时,模型对象状态的恢复等等。还是引用Udi Dahan的一句话:简单,但不容易!
是时候总结一下本系列文章了。还是应该自我批评一下,由于个人杂事多,加上工作繁忙,整个系列文章弄了大半年才断断续续写完。在撰写文章的过程中,也得到了大家的理解与支持,并让更多的朋友开始关注领域驱动设计,很是感激!在接下来的其它博文中,我将继续讨论领域驱动设计的实践经验。
本系列文章首先从领域驱动设计的基础思想出发,讨论了基于.NET EntityFramework的领域驱动设计经验,这包括对实体、值对象、工厂和仓储实现方式的讨论、对EntityFramework所提供的开发工具功能点的讨论,还包括了规约模式及其.NET实现。从讨论中我们可以了解到,目前Microsoft .NET EntityFramework在对领域驱动设计的支持上还是有一些不足的地方,比如对值对象的支持、对实体行为以及事件驱动的支持,但同时我们也看到了.NET在DDD上取得的巨大进步,这包括:具有DSL(Domain Specific Language)特质的语言集成查询(LINQ)、面向实体的领域对象模型(LINQ to SQL是面向数据的)、复合数据类型支持。毕竟.NET EntityFramework是一种产品,它需要考虑广大用户的需求,所以也会包括一些Anti-DDD的元素在里面。
在讨论了经典DDD的EntityFramework实践经验之后,本系列文章还引出了两个扩展话题:服务与CQRS体系结构模式。CQRS体系结构模式是近年来DDD社区总结出来的一种新的DDD实践模式,也是目前DDD社区中讨论的较多的一种体系结构模式。它以CQS思想为基础,以事件溯源(Event Sourcing)为核心,将应用系统的命令与查询实现职责分离,从而获得Event Auditing的功能,同时大大提高了系统的运行效率,并为架构技术选型和团队资源配置(Resource Configuration)带来了广阔空间。有关CQRS的设计与实现,我会在后续的文章中继续介绍。
标签:
原文地址:http://www.cnblogs.com/bdbw2012/p/4762719.html