标签:
1 样本的采样有哪些方式?- 按query进行采样?
- 随机选择query, 一旦选择了某个query, 则该query的所有url都被选择了.
需要注意的时, 对于不同的query, 它的url个数是不一样的(尽管对于query而言, 采样是等概率的, 而对于url而言不是等概率的).
- 按url进行采样
- 是事先对每个query的url组成url对, 然后随机采样url对?
- 还是对url进行采样, 然后对采用到的url进行pairing(要注意只有在同一个query下的url才可以pairing).
不同query的url进行采样时, 它们显得更随机(但是对于query而言, 还是多url的query被抽到的概率偏大)
但是有可能导致抽到query的url不足以pairing.
- 哪种更好? 优缺点?
query的: 对于query而言是随机的, 但是对于query的url而言是绝对的, 可保证每个query的url能够pairing
url的: 更随机, 对于url而言是等概率的.
由于训练样本是url对, 所以希望在抽样的时候, 抽到url的概率是随机的, 所以选择"url"方案
2 gbdt在gbrank中有什么作用? gbrank可以用其它的方法来替代gbdt? 如果有, 该方法是怎么工作的?
gbdt在gbrank的作用是在每次迭代中, 用负梯度来产生一颗回归树来拟合样本的负梯度, 用拟合后的负梯度来更新模型..
如果能够用其它的方法来拟合每次迭代中的负梯度, 那么该方法就可以替代gbdt.
具体来说, 就是利用替代方法来拟合每个样本的负梯度即可, 本质上是个回归问题.
所以可以用一些回归的方法来替代gdbt.
3 gbrank如何防止过拟合?
- 在迭代中, 动态调整学习率.
- 对样本进行采样(类似bagging)
就是建树的时候, 不是把所有的样本都作为输入, 而是选择一个子集.
- 对特征进行采样
类似样本采样一样, 每次建树的时候, 只对部分的特征进行切分.
但采样有个很严重的问题, 就是不可复现, 也就是每次的训练结果不一样, 不知道是调了参数导致效果好, 还是采样导致效果好, 还是其他的?
- 对回归树进行剪枝
- 减少回归树的个数, 尤其那些作用不大的回归树(在验证集上进行测试).
(跟样本数, 特征数有关?)
- 迭代中更关注上次迭代分错的样本? (但是华哥说, 这是为了更好的拟合目标函数, 而不是防止过拟合).
- 通过对比训练集上的loss和验证集上的accuracy, 当发现loss持续减少, 而accuracy不再提高的时候, 可以判读出现了过拟合. 这时要么停止训练, 要么调小学习率, 继续训练?
- 增加样本(data bias or small data的缘故), 移除噪声
- 减少特征, 保留重要的特征(可以用PCA等对特征进行降维)
4 cross entropy loss的物理意义是啥?
根据公式 - log2(p^y * (1-p)^(1-y)) ==> -y*log2(p) - (1-y)*log(1-p) (由于出于方便, 就不写完整的公式).
当预测的概率p和真实label y一致时, loss理应很小; 当它们不一致时, loss会呈指数级增加, 从而惩罚不一致的样本.
所以在训练的时候, 通过惩罚不一致的情况, 来拟合真实情况.
一句话概括: 就是尽可能地让学到的分布与真实分布一致.;
5 ltr相对于传统方法有什么好处? ltr输入是啥?
- 可以自动学习模型的权重 (当然也可以加入领域知识来优化约束).
- 易扩展: 对于新增的样本或者特征, 容易加入到原来的模型中, 再重新训练模型.
- 成本低(相对于人工调参而言)
(快速验证模型的好坏 (相对于传统模型, 训练过程快) ==> 个人想法有待验证)
以上都是针对样本数量大, 特征维度高的情况, 要不然, 直接人工模型即可.
- 迁移学习
ltr的输入:
- 样本集的feature + label
- 样本集的feature + 新特征 + label
- 其他模型的输出 + labels
- 其他模型的输出 + 其他模型的feature + label
- 其他模型的输出 + 新特征 + label
- 其他模型的输出 + 其他模型的特征 + 新特征 + label
- ...
- end-to-end的过程, 即模型训练和特征学习是同时进行的. (raw input ?)
6 ltr的流程是什么? (pointwise, pairwise, listwise.) 它们有什么优缺点?
输入:<query, <url>*>*
输出: 每个query排序好的urls
ltr主要有三种方法:
- pointwise: 对<query, url>中的url进行相关性的分类或者回归 (打分)
- pairwise: 对<query, <url1, url2>>中的url1和url2的相关性优先关系进行二分类或者回归
- listwise: 对<query, <url1, url2, url3, ...>>中的urls进行相关性排序.
它们的优缺点:
- pointwise: 模型简单, 可以对不同等级/分档的urls进行相关性排序, 不可对同等级/分档的urls进行相关性排序.
- pairwise: 为了解决pointwise中urls不能对相关性进行排序的情况, 它的大概思想是简单地将排序问题转化为二分类问题或者回归问题, 来解决成对urls的相关性排序. 一旦知道任何一对urls的相关性的先后顺序, 就可以通过拓扑排序得到urls的全排序的结果. (实际上在预测时, 是对每一个url进行一个打分, 然后通过对这个打分进行排序来得到全排序的结果).
- listwise: 通过把全排序的问题转为预测permutation的概率, 选择概率最高的permutation. (首先对每个url进行打分, 通过设置不同的函数来对打分进行permutation的概率预测). 缺点是: 模型过于复杂, 难以设计较好的函数来对permutation进行预测. 另外效果上和pairwise的差不多.
7 gbdt在训练和预测的时候, 都用到了步长, 两个步长是一样的? 有什么用, 如果不一样, 为什么? 怎么设步长的大小? (太小? 太大?) 在预测时, 设太大对排序结果有什么影响? 跟shrinking里面的步长一样么?
训练跟预测时, 两个步长是一样的, 也就是预测时的步长为训练时的步长, 从训练的过程可以得知(更新当前迭代模型的时候).
它的作用就是使得每次更新模型的时候, 使得loss能够平稳地沿着负梯度的方向下降, 不至于发生震荡.
步长的大小不能过大, 也不能过下:
如果步长过大, 在训练的时候容易发生震荡, 使得模型学不好, 或者完全没有学好, 导致精度不好.
而步长过小, 或导致训练时间过长, 即迭代次数较大, 导致生成较多的树, 使得模型变得复杂, 造成过拟合以及增大计算量.
不过步长较小的话, 使训练比较稳定, 总能找到一个稳定的局部最优解.
个人觉得过大过小的话, 模型的预测值都会偏离真实情况(可能比较严重), 从而导致模型的精度不好.
那么怎么设步长的大小么?
有两种方法, 一种就是按策略来决定步长, 另一种就是在训练模型的同时, 学习步长.
- 策略: 1 每个树步长恒定且相等, 一般设较小的值; 2 开始的时候给步长设一个较小值, 随着迭代次数动态改变, 或者说衰减.
- 学习: 因为在训练第k棵树的时候, 前k-1棵树时已知的, 而且求梯度的时候是利用前k-1棵树来获得, 所以这个时候, 就可以把步长当作一个变量来学习.
8 gbrank的h(x)函数为什么要加一个变量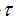 不加可不可以? 加了有什么作用? 设多大才合适? 太大对排序有什么影响么?
不加可不可以? 加了有什么作用? 设多大才合适? 太大对排序有什么影响么? - 可以不加, 但是加它是为了防止函数h变成常量函数,
- 一般它在(0, 1]之间的取值, 把它设为常量 (这样做是为了简化模型的复杂度)
- 可以把它设为较大一点, 也就是拉大url相关性偏序程度, 让模型学到成对urls对于query的相关性程度.
先看下公式中

, 需要注意到
的正则化.
一般情况
不宜过大, 往往设为(0, 1]之间的值.
如何设置好?
- 当
设的较小时, 会导致
不起作用.
- 当
设的较大的时候, 会出现什么情况:
- 我们的目标是 当xi >= yi成立的时候, h(xi) >= h(yi) +
成立, 反之亦然.
- 根据hinge loss的特点, 模型更新的条件是上述情况不成立.
- 一旦 设的很大, 对于大多数的样本来说,
xi >= yi成立的时候, h(xi) >= h(yi) + 是不
成立得, 反之亦然. - 由于设的过大, 导致大多数的样本都参与了每次迭代模型更新, 换句话说, 模型没有学好.
- 在测试的时候, 由于模型没有学好, 从而导致大多数的测试样本对都不会满足"
xi >= yi成立的时候, h(xi) >= h(yi) + 也成立", 从而导致测试效果不好.
所以需要对
进行约制, 一般的方法就是正则化, 可以用L1/L2来正则化
.
(个人觉得
的作用类似svm里面的惩罚因子C).
9 树(CART)为什么要剪枝? 如何剪枝的?
当生产的树对训练数据拟合得很好, 但是对验证集/测试集/未知数据的拟合的不好的时候, 该树过拟合.(过拟合的原因在于学习时, 过多地考虑如何提高训练数据的效果, 从而构建了过于复杂的决策树.)
解决过拟合的方法就是考虑决策树的复杂度, 对已生成的决策树进行简化.
(剪枝: 将已生成的树进行简化的过程. 具体来说, 剪枝从已生成的树上裁掉一些子树或者叶结点, 并将其根节点或者父节点作为新的叶子节点, 从而简化分类器模型.)
树的剪枝分为两种:
- 预剪枝
预剪枝就是生成树时的停止条件 (见15)
- 后剪枝
后剪枝就是对生成的树, 进行剪枝(去掉一些子节点/子树)
这里主要说下CART的后剪枝:
CART剪枝算法从"完全生长"的决策树的底端剪去一些子树, 使决策树变小/模型变得简单, 从而能够对验证集/测试集/未知数据有更好的预测/拟合.
CART剪枝由两步组成:
- 利用训练数据对已生成的决策树T0的底端叶子节点开始, 自底向上地不断剪枝(每次剪枝都会形成一个子树Ti), 直到T0的的根节点, 从而形成一个子树集{T0, T1, T2, ,,,, Tn }
- 利用验证集对生成的子树集{T0, T1, T2, ,,,, Tn }中的每颗子树进行测试, 选择验证效果最好的子树, 作为最终的决策树.
问题定义:
- 树的剪枝往往通过极小化树的整体损失函数或者代价函数(生成树)来实现的, 整体损失函数或者代价函数需要考虑模型的复杂度..
- 定义剪枝的损失函数/代价函数:
在剪枝过程中, 计算子树的损失函数为: 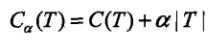
其中T为任意子树, C(T)为对训练数据的预测误差(如最小平方误差), |T|为子树T的叶结点个数. 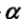
为常数(>=0).
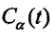 为参数为时的子树T的整体误差. 参数权衡着训练数据的拟合程度和模型的复杂度.
为参数为时的子树T的整体误差. 参数权衡着训练数据的拟合程度和模型的复杂度. - 显然, 对于给定的
, 一定存在使损失函数
最小的子树, 则该子树在损失函数最小意义下是最优的(想想为什么? -> 最小能确保模型拟合的好的同时, 减少模型的复杂度). 容易验证这样的子树是唯一的.
- 现在考虑极端情况:
= 0, 整棵树是最优的,
= 正无穷大, 更节点组成的单节点树是最优的.
- Breiman等人的证明:

变量定义:
- 树为T0, 树的节点数为M=|T0|, 树的叶子节点数为N
- 对于每一个节点, 由T0剪掉以该节点作为根节点的子树(保留该节点), 从而得到树Ti, i=1, ..., M. (包括原树T0, 共有M+1棵子树)
具体过程:
- 遍历所有可能的 = 0: 正无穷 - 对于每一个子树Ti = 0: M+1
- 根据损失函数, 用训练集求出子树Ti的损失
- 根据子树的损失, 找到损失最小的子树作为当前的最优子树
-
- 对于每一个
, 用验证集来计算其最优子树的效果.
- 选择效果最好的子树作为树T0剪枝后的树.
上述的过程是暴力的方法, 其计算复杂度是不可控的.
所以需要优化.其实我们并不需要知道的具体取值是多少. 而是知道什么情况下剪掉子树即可, 即剪枝后整体损失函数减少的程度. 根据Breiman等人的证明: 具体地, 从整体树T0开始剪枝, 对于任何的节点t, 都可以:
10 boosting的本意是什么? 跟bagging, random forest, adaboost, gradient boosting有什么区别?
bagging:
可以看成是一种圆桌会议, 或是投票选举的形式. 通过训练多个模型, 将这些训练好的模型进行加权组合来获得最终的输出结果(分类/回归), 一般这类方法的效果, 都会好于单个模型的效果. 在实践中, 在特征一定的情况下, 大家总是使用Bagging的思想去提升效果. 例如kaggle上的问题解决, 因为大家获得的数据都是一样的, 特别是有些数据已经过预处理.
基本的思路比较简单, 就是:训练时, 使用replacement的sampling方法, sampling一部分训练数据k次并训练k个模型;预测时, 使用k个模型, 如果为分类, 则让k个模型均进行分类并选择出现次数最多的类(每个类出现的次数占比可以视为置信度);如为回归, 则为各类器返回的结果的平均值. 在该处, Bagging算法可以认为每个分类器的权重都一样
random forest:
随机森林在bagging的基础上做了修改.
- 从样本集散用Boostrap采样选出n个样本, 预建立CART
- 在树的每个节点上, 从所有属性中随机选择k个属性/特征, 选择出一个最佳属性/特征作为节点
- 重复上述两步m次, i.e.build m棵cart
- 这m棵cart形成random forest.
随机森林可以既处理属性是离散的量, 比如ID3算法, 也可以处理属性为连续值得量, 比如C4.5算法.
这里的random就是指:
- boostrap中的随机选择样本
- random subspace的算法中从属性/特征即中随机选择k个属性/特征, 每棵树节点分裂时, 从这随机的k个属性/特征, 选择最优的.
boosting:
由来:
- Kearns & Valiant (1984)
PAC学习模型 - 提出问题:
- 强学习算法:存在一个多项式时间的学习算法以识别一组概念,且识别的正确率很高。
- 弱学习算法:识别一组概念的正确率仅比随机猜测略好。
- 弱学习器与强学习器的等价问题。如果两者等价,只需找到一个比随机猜测略好的学习算法,就可以将其提升为强学习算法。
- Kearns & Valiant (1989)
证明了弱学习器和强学习器的等价问题。
- Schapire (1989)
第一个提出了一个可证明的多项式时间的Boosting算法。
- Schapire, etc. (1993)
第一次把Boosting算法思想用于实际应用:OCR。
- Freund & Schapire (1995)
AdaBoost算法
- boosting是”提升”的意思. 一般Boosting算法都是一个迭代的过程, 每一次新的训练都是为了改进上一次的结果.
- boosting在选择hyperspace的时候给样本加了一个权值,使得loss function尽量考虑那些分错类的样本(如分错类的样本weight大). 怎么做的呢?
- boosting重采样的不是样本,而是样本的分布,对于分类正确的样本权值低,分类错误的样本权值高(通常是边界附近的样本),最后的分类器是很多弱分类器的线性叠加(加权组合).
或者这么理解也是可以的:
如果弱学习器与强学习器是等价的, 当强学习器难以学习时(如强学习器高度非线性等), 问题就可以转化为这样的学习问题:
学习多个弱分类器(弱分类器容易学习), 并将多个弱分类器组合成一个强分类器(与原来的强学习器等价).
adaboosting:
这其实思想相当的简单, 大概是对一份数据, 建立M个模型(比如分类), 而一般这种模型比较简单, 称为弱分类器(weak learner). 每次分类都将上一次分错的数据权重提高一点, 对分对的数据权重降低一点, 再进行分类. 这样最终得到的分类器在测试数据与训练数据上都可以得到比较好的效果.
每次迭代的样本是一样的, 即没有采样过程, 不同的是没有样本的权重不一样. (当然也可以对样本/特征进行采样, 这个不是adaboosting的原意).
另外, 每个分类器的步长由在训练该分类器时的误差来生成.
gradient boosting:
每一次的计算是为了减少上一次的残差(residual), 而为了消除残差, 我们可以在残差减少的梯度 (Gradient)方向上建立一个新的模型. 所以说在Gradient Boost中, 每个新模型是为了使之前模型的残差往梯度方向减少, 与传统Boost对正确, 错误的样本进行加权有着很大的区别. (或者这样理解: 每一次建立模型是在之前建立模型损失函数的梯度下降方向. 这句话有一点拗口, 损失函数(loss function)描述的是模型的不靠谱程度, 损失函数越大, 则说明模型越容易出错(其实这里有一个方差、偏差均衡的问题, 但是这里就假设损失函数越大, 模型越容易出错). 如果我们的模型能够让损失函数持续的下降, 则说明我们的模型在不停的改进, 而最好的方式就是让损失函数在其Gradient的方向上下降).
11 cross-entropy loss对于hinge loss有什么好处?
- cross-entropy的解释性强
- 通过作图可以看出, cross-entropy是平滑的, 而hinge loss不是平滑的
- hinge loss 对于正例的loss是0, 反例不是0, 这样导致其在每次迭代中, 只用到反例来更新模型(也就是只用了反例来建树, 丢失了正例的信息)
- 从它们的loss上看, hinge loss对反例的惩罚是呈指数增长的, 而hinge loss是线性增长的.
12 决策树有什么有优缺点?
优点:
- 可解释强
- 学习能力强, 高效地处理非线性问题
- 应用范围广, 处理分类, 回归, 排序问题
- 数据准备代价低
缺点:
- 容易过拟合
- 训练代价相对高
- 特征分析相对难
13 ensemble的思想
- 单个弱学习器决策能力有限
- 继承多个弱学习器可以获得更强的决策能力
- 泛化能力好 (多样性, 准确性)
14 gbdt哪些部分可以并行?
- 计算每个样本的扶负梯度
- 分裂挑选最佳特征及其分割点时, 对特征计算相应的误差及均值时
- 更新每个样本的负梯度时
- 最后预测过程中, 每个样本将之前的所有树的结果累加的时候
15 单棵树停止生长的条件?
- 节点分裂时的最小样本数
- 最大深度
- 最多叶子节点数
- loss满足约束条件
16 另外树的个数越多越好么? 还是越小越好? 怎么确定树的个数?
- 树的棵树过少的话, 容易导致欠拟合, 即模型的精度不高
- 树的棵树过多的话, 容易导致模型过拟合, 而模型的复杂度大, 导致计算量大
- 所以树的个数要适中
如何确定树的棵数?
- 先选取一个比较大的数, 然后用二分法逐步减少树的数目, 分别计算相应的点画图, 看哪个过拟合了, 哪个变得平滑, 就确定这个数.
- 但是这个是在验证集上检验.
17 怎么对数据特征分析来帮助模型训练?- 特征的分布: 按特征的取值分段, 每一段包含的样本数量, 特征均值, 方差等.
- 目标分布 (同上)
- 特征目标关系: 特征分段, 每段中包含的样本的目标取值.
- 目标特征关系: 目标分段, 每段中包含的样本的特征取值.
18 模型在类似Cross-Validation上测试效果不错, 但在开发测试上效果不佳?- 选取的训练数据的覆盖度不够, 即数据集不具有代表性(不过完备), 不能体现真实数据的分布.
- 模型迁移 (model drift), 随着时间的转移, 特征数据也会跟着变化. 比如3个月前的模型对现在的特征可能不会有好的结果.
Reference
GBrank_问题列表
标签:
原文地址:http://www.cnblogs.com/xuanyoumeng/p/4762918.html