标签:
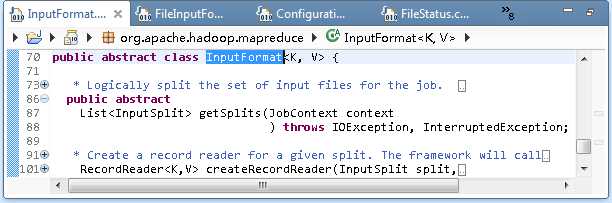
输入格式类InputFormat
用于描述MR作业的输入规范,主要功能:输入规范检查(比如输入文件目录的检查)、对数据文件进行输入切分和从输入分块中将数据记录逐一读取出来、并转化为Map输入的键值对。
 FileInputFormat类
FileInputFormat类
主要功能是为子类提供统一的getSplits()方法实现。其中最核心的两个算法是:
1).文件切分算法. 主要用于确定InputSplit的个数以及每个InputSplit对应的数据段。FileInputFormat以文件为单位切分生成各个InputSplit,对于每个文件,由三个属性值确定其对应的InputSplit的个数。详见Job流程:决定map个数的因素
2).host选择算法. 待InputSplit切分方案确定后,下一步确定每个InputSplit的元数据信息。这通常由四部分组成:<file,start,length,hosts>,分别表示InputSplit所在的文件、起始位置、字节长度以及所在的host(节点)列表。其中,前三项很容易确定,难点在于host列表的选择方法。
虽然InputSplit对应的block可能位于多个节点上,但考虑到任务调度的效率,通常不会把所有节点加到InputSplit的host列表中,而是选择包含该InputSplit数据总量最大的前几个节点(默认是10个,多余的过滤掉),以作为任务调度时判断任务是否具有本地性的主要凭证。为此,FileInputFormat设计了一个简单有效的启发式算法:
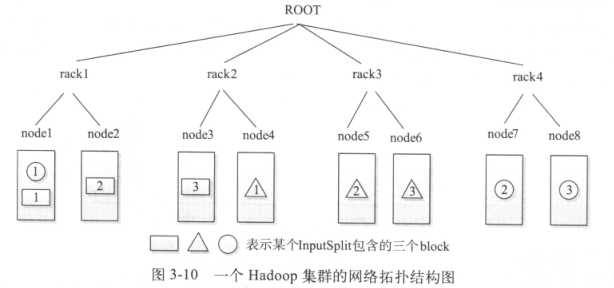
例子:某个Hadoop集群的网络拓扑图如图所示,HDFS中block副本数为3,某个InputSplit包含3个block,大小依次是100、150和75,很容易计算,4个rack包含的(该InputSplit的)数据量分别是175、250、150和75。rack2中的node3和node4,rack1中的node1将被添加到该InputSplit的host列表中。
host选择算法过程:对4个rock包含(该InputSplit的)数据量的大小进行排序:rock2 > rock1 > rock3 > rock4,所以选择 rock2 中node3和node4的file1和file2,rack1中node1的file3加载到该InputSplit的host列表中。
从以上host选择算法可知,当InputSplit尺寸大于block尺寸时Map Task并不能实现完全数据本地性,也就是说,总有一部分数据需要从远程节点上读取,因而可以得出以下结论~:
当使用基于FileInputFormat实现InputFormat时,为了提高Map Task的数据本地性,应尽量使InputSplit大小与block大小相同。
TextInputFormat类
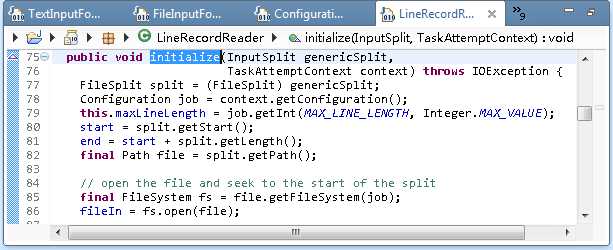
TextInputFormat继承自FileInputFormat类,间接继承自InputFormat类。TextInputFormat类中包含两个方法:
LineRecordReader类中有一个initialize()方法,它用于对InputSplit进行初始化。类中的其他方法则是将其解析成一个个键值对输出。
 输出格式化类OutPutFormat
输出格式化类OutPutFormat
OutputFormat是一个抽象类,主要用于描述输出数据的格式,将用户提供的key/value对写入特定格式的文件中。
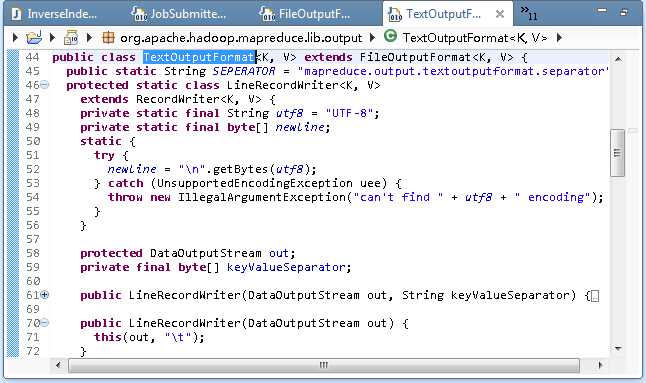
TextOutputFormat
FileOutputFormat类也是一个抽象类,具体的实现类在于TextOutputFormat类,其中包含一个LineRecordWriter的静态内部类,该类负责输出一行MR结果。
标签:
原文地址:http://www.cnblogs.com/skyl/p/4763085.html