标签:style blog http color 使用 strong
接上面的题目,假若待排序的数据有重复的呢?这里采用的是归并排序。
ok,接下来,我们来编程实现上述磁盘文件排序的问题,本程序由两部分构成:
1)、内存排序
由于要求的可用内存为1MB,那么每次可以在内存中对250K的数据进行排序,然后将有序的数写入硬盘。
那么10M的数据需要循环40次,最终产生40个有序的文件。
2)、归并排序
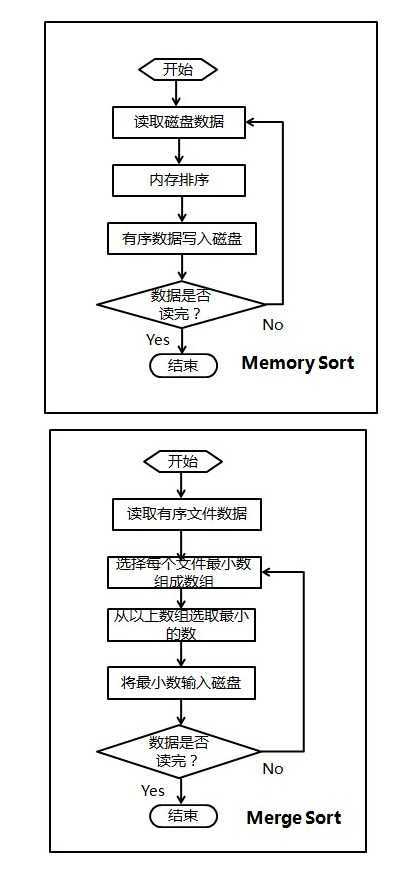
while(true){ num=ReadFile( fp_unSortFile, each_file);//从未排序的数据中读取dataSize个数据if(num ==0)break;//所有数据读完的条件,也是while结束的条件 qsort(fp_unSortFile,dataSize,sizeof(int),compare);//然后排序WriteFile(fp_sortFile, each_file, dataSize);//接着分别写入file_num个文件夹}fscanf(fp_array[index],"%d",&first_data[index]);FILE**fp_array =newFILE*[file_num];//索引每个文件,先申请内存for(int i =0; i < file_num; i++) fscanf(fp_array[i],"%d",&first_data[i]);//这里将每个文件的第一个数字存储到first_data中while(true){所有文档都都没剩余的就终止int pMinData = first_data[index]; findMinData(first_data,pMinData,index)//找到最小值,还要记得把这个值得index记录下来 fscanf(fp_array[index],"%d",&first_data[index]);//移动index的最小指针}//快排并将结果放在磁盘中intMemorySort(){FILE* fp_unSortFile = fopen("d:\\unSort.txt","r");CheckFile(fp_unSortFile);int num;int count =0;//记录用快排后的文件数量while(true){int*each_file =newint[dataSize]; num=ReadFile( fp_unSortFile, each_file);if(num ==0)//终止条件,当读取的数字个数为0的时候,也就是全部读完以后就终止。break; count++; qsort(fp_unSortFile,dataSize,sizeof(int),compare); string new_name = new_file_name(count);FILE*fp_sortFile = fopen(new_name.c_str(),"w");//fopen 第一个参数类型是const char*,这里用c_str()进行转换WriteFile(fp_sortFile, each_file, dataSize); fclose(fp_sortFile);//记得关掉delete[]each_file;//记得释放} fclose(fp_unSortFile);return count;//返回文件数目}voidMergeSort(int file_num){FILE*fp_sortFile = fopen("d:\\sortResult.txt","w");CheckFile(fp_sortFile);FILE**fp_array =newFILE*[file_num];//索引每个文件,先申请内存for(int i =0; i < file_num; i++)//理解怎么索引到每个文件的{ string file_name = new_file_name(i +1); fp_array[i]= fopen(file_name.c_str(),"r");}int*first_data =newint[file_num];//要找到每个文件最小的数字,必须先把所有文件最小数字先保存起来for(int i =0; i < file_num; i++) fscanf(fp_array[i],"%d",&first_data[i]);//这里将每个文件的第一个数字存储到first_data中bool*finish =newbool[file_num];//主要用来保证所有的文件都读取完了 memset(finish,false,sizeof(bool)*file_num);while(true){//终止条件int index =0;while(index < file_num&&finish[index]) index++;if(index >= file_num)break;int pMinData = first_data[index];for(int i = index +1; i < file_num; i++){if(pMinData>first_data[i]&&(!first_data[index])){ pMinData = first_data[i]; index = i;}} fprintf(fp_sortFile,"%d",pMinData);if(first_data[index]== EOF)//如果都读完了,那么这个文件就不用再读了。 finish[index]=true; fscanf(fp_array[index],"%d",&first_data[index]);//这一句是代码的核心,每当将最小数存入fp_sortFile后,就将其读取指针移动一位。 }}constint dataNumber =10000000;constint dataSize =250000;voidCheckFile(FILE* fp){if(fp == NULL){ cout <<"打开文件出错!!!"<< endl; exit(1);}}intReadFile(FILE* fp,int*space)//将fp指向的数据读入space数组中,并返回读入的大小{int index =0;while(index<dataSize&&(fscanf(fp,"%d",&space[index])!= EOF)) index++;return index;}voidWriteFile(FILE*fp,int*space,int num)//从space中将数据存入fp指向的文件,num限制写入的大小{int index =0;while(index<num){ fprintf(fp,"%d", space[index]); index++;}}int compare(constvoid*a,constvoid*b)//按照从小到大的顺序排列{return*(int*)a -*(int*)b;}string new_file_name(int count){char name_buffer[20]; sprintf(name_buffer,"data%d.txt",count);//注意sprintf 、fprintf区别,前者针对缓冲流,后者针对文件return name_buffer;}1)、关于本章中位图和多路归并两种方案的时间复杂度及空间复杂度的比较,如下:
时间复杂度 空间复杂度
位图 O(N) 0.625M
多位归并 O(Nlogn) 1M
2)、bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloom filter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
3)、[外排序适用范围]--归并排序
大数据的排序,去重基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树扩展。问题实例:1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
参考:http://blog.csdn.net/v_JULY_v/article/details/6451990
如何给10^7个数据量的磁盘文件进行排序--归并排序,布布扣,bubuko.com
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/menghuizuotian/p/3840974.html