标签:
关于重连测试的一点研究
在最近的异常测试中,发现长连接协议的客户端存在较多的坑点,除了需要关注一般的网络错误、超时之外,长连接本身就具有无连接时创建连接,连接异常时重连这样的特性,是额外需要关注的地方。如果处理不好,往往会造成无限重连socket占满,或者是网络断开没有触发重连导致后续请求全都发不出去这样的大问题
然而我在做这类测试的时候也是一头雾水,尝试用iptables reject或者drop了连接,触发了几次报错或者重连是否就真的对这样的场景验证完全了呢?到底应该iptables掉的是客户端发送的包还是客户端接收的包,这2种姿势哪种才是对的呢?我陷入了深深的迷茫之中
周末埋头研究了一下,尝试理了一下思路,整理如下
谈到重连,那就必须从关闭连接说起
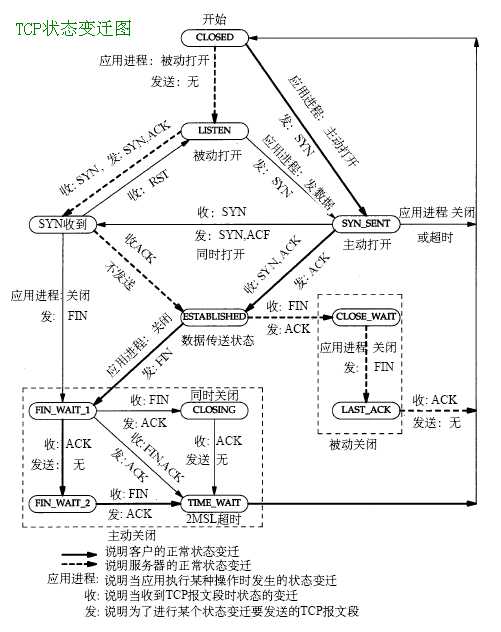
TCP状态转移图大家都很熟悉,看到有关闭连接那部分, 如图所示关闭连接是由FIN发起的
简单的从wireshark抓包看建立连接->发请求->断开连接的过程也能看到FIN 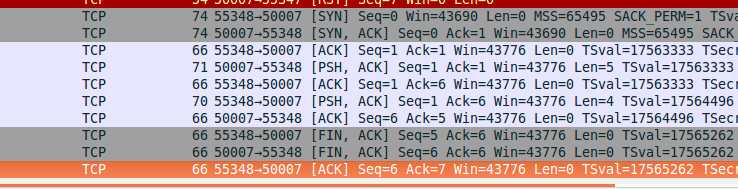
然而除了正常的FIN的方式断开连接,还有一种RST的方式用来异常的关闭连接,比如telnet了一个本地一个不存在的端口返回了RST: 
需要注意的是RST报文段不会导致另一端产生任何响应,另一端根本不进行确认。收到RST的一方将终止该连接,并通知应用层连接复位。出现RST的一般都是异常情况:
这时候对于短连接来讲本次连接失败了抛异常连接关闭,但对于长连接来讲,需要客户端保持和服务器的连接以便能够继续发消息,往往需要触发重连的操作
重连本身没有太多好讲的,即关闭原有连接再重新连接,我们更关心的是对于FIN的情况和RST的情况,客户端能否关闭旧连接创建新连接,这构成了我们接下去的测试场景的设计
建立完连接,然后和服务器不断收发请求的过程中,客户端能够实时的感知到网络状态。但如果连接建立但长时间没有发送过请求,会一直保持着连接。这其中如果有一方异常掉线,另一端永远也不可能知道,那么客户端如何才能知道这个情况并进行重连呢,可以采用一种称为心跳检测的方式
有些客户端会使用自己的心跳检测方法,原理和TCP协议自带的类似,所以这里拿TCP自带的keepalive来模拟说明。当建立一个TCP连接时,发送端就会创建一些计时器,其中一些计时器就是处理keeplaive相关问题的。当keepalive的计时器计数到0时,发送端就会向对端发送一些不含数据的keepalive数据包并开启ACK标志。如果得到keepalive探测包的回复,就可以认为当前的TCP连接正常。如果响应失败的次数超过探测包设定的次数,则认为连接失败,关闭连接,
我们可以用cat命令查看到系统中TCP keeplaive相关配置项的值
#cat /proc/sys/net/ipv4/tcp_keepalive_time 7200
#cat /proc/sys/net/ipv4/tcp_keepalive_intvl 75
#cat /proc/sys/net/ipv4/tcp_keepalive_probes 9
含义分别为tcp_keepalive_time(开启keepalive的闲置时长)tcp_keepalive_intvl(keepalive探测包的发送间隔)和tcp_keepalive_probes (如果对方不予应答,探测包的发送次数)。修改配置文件, 对整个系统所有的socket有效.:
#echo 60 > /proc/sys/net/ipv4/tcp_keepalive_time
#echo 75 > /proc/sys/net/ipv4/tcp_keepalive_intvl
#echo 2 > /proc/sys/net/ipv4/tcp_keepalive_probes
写一个长连接的socket和client,诀窍就是用while以后不要退出,不要退出,不要退出
服务端
import time
HOST_LOCAL = ‘‘ # Symbolic name meaning all available interfaces
PORT_LOCAL = 50007 # Arbitrary non-privileged port
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind((HOST_LOCAL, PORT_LOCAL))
s.listen(1)
conn, addr = s.accept()
print ‘Connected by‘, addr
while 1:
data = conn.recv(2048)
if not data: continue
conn.send("hello")
s.close()
客户端
#!/usr/bin/env python
import socket
import time
HOST = ‘‘ # The remote host
PORT = 50007 # The same port as used by the server
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))
while True:
s.send(‘hello world\r\n‘.encode())
time.sleep(10)
s.close()
当请求以10s的间隔发送时,由于小于超时检查时间窗,无需进行心跳检查 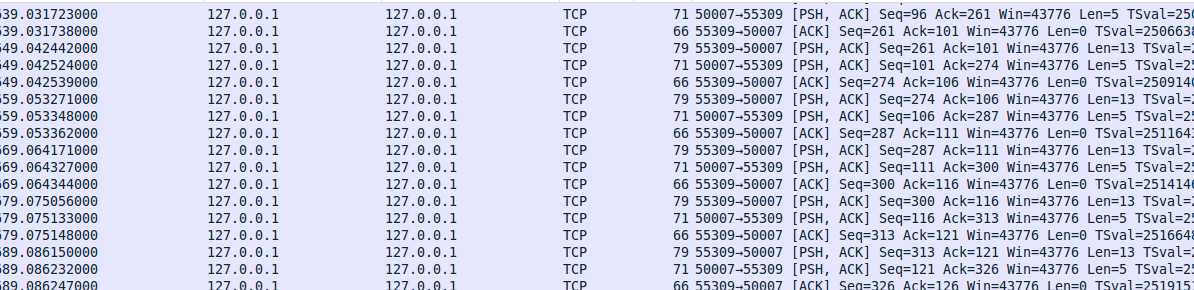
所以修改tcp_client.py设置发送请求间隔为120
time.sleep (120)
服务端加上keepalive
s.setsockopt(socket.SOL_SOCKET,socket.SO_KEEPALIVE,1)
由于超时时间窗为60s,请求间隔为120s,则每次请求1min后会触发一次Keep-alive 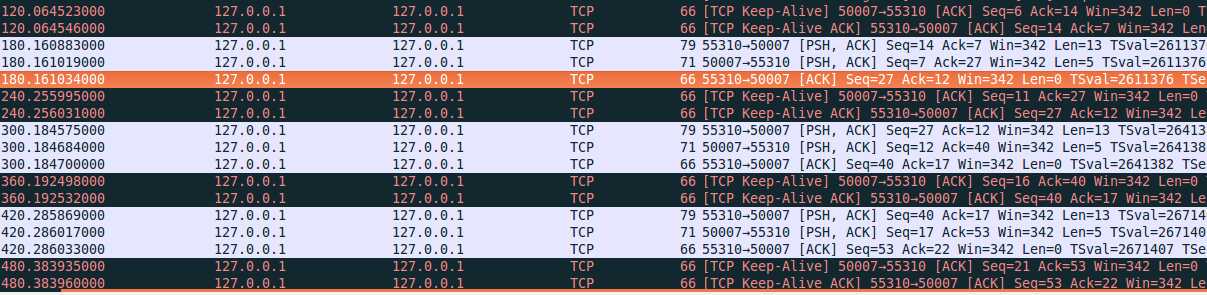
现在加上DROP使客户端发往服务端的包被丢弃
# iptables -I OUTPUT -p tcp --dport 50007 -j DROP
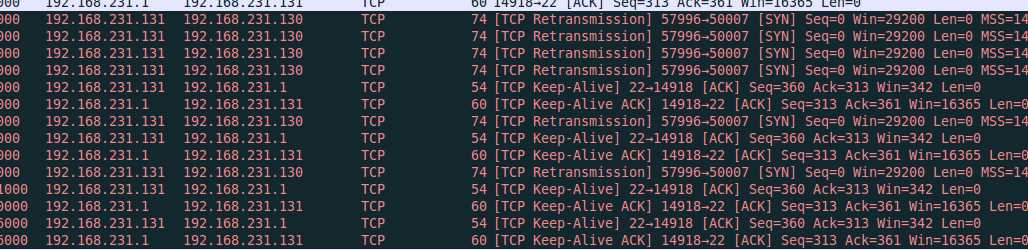
在75s的2次探查失败后(第一列time 840->915->990),服务端向客户端发送了RST,然后查看了下两边连接都已经关闭 
为什么DROP连接后,最后两边连接都能够正常释放?
如果把接受服务端的包DROP掉,客户端可能就无法觉察到连接的异常
DROP掉服务端发往客户端的包,在不断有请求发送的情况下,客户端不断重传请求,最终超时退出,返回socket.error: [Errno 110] Connection timed out 
DROP掉服务端发往客户端的包,如果两边没有数据发送,, 就算服务端关闭连接了,客户端也没感知到网络断了,如下面那所示,服务器因为心跳检测关闭已关闭连接,而客户端还没有,连接是半打开(Half-Open)的了
# netstat -lan|grep 50007
tcp 0 0 0.0.0.0:50007 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:50007 127.0.0.1:55321 ESTABLISHED
tcp 5 0 127.0.0.1:55321 127.0.0.1:50007 ESTABLISHED
# iptables -I OUTPUT -p tcp --dport 55321 -j DROP
# netstat -lan|grep 50007
tcp 5 0 127.0.0.1:55321 127.0.0.1:50007 ESTABLISHED
所以不仅服务端需要有心跳检查,客户端也需要有自己的心跳,在客户端加上心跳检测后,客户端能检测到连接异常,而能够关掉当前连接 
有心跳检测但没有重连处理造成的异常,常常发生在测试环境,比如过了一个周末回来发现有服务连不上,重启后生活才能自理,所以对于有心跳检查机制的客户端,需要观察下空闲情况下的网络异常是否会触发重连
通过上面2个部分的描述,我们大概能够规划出如何有哪些场景是用来测试重连的
主要观察本次连接失败,连接是否释放,下次连接是否能成功
用心跳检测时写的那个python客户端访问一个不存在的端口,也可认为是原本存在,但服务挂了就不存在了
socket.error: [Errno 111] Connection refused
wireshark抓包看有收到了RST包 
我们通常用iptables REJECT掉发往目标地址的请求,同样能返回[Errno 111] Connection refused
但是这2个真的是一回事么,尝试下,可以发现其实返回的是icmp报错
iptables -I INPUT -p tcp --dport 50007 -j REJECT

而更接近的方式应该是iptables -I INPUT -p tcp –dport 50007 -j REJECT –reject-with tcp-reset

reject-with还有其他的返回错误可以选择,简单列举一下
iptables -I OUTPUT -p tcp --dport 50007 -j REJECT --reject-with icmp-host-prohibited
[Errno 113] No route to host

[Errno 101] Network is unreachable

[Errno 113] No route to host

[Errno 111] Connection refused

[Errno 92] Protocol not available

[Errno 101] Network is unreachable

刚才采用的方式是REJECT客户端发出的包,但如果尝试REJECT从服务端返回的包呢?那实际上是模拟网络超时
# iptables -I INPUT -p tcp --sport 50007 -j REJECT
服务端收到了请求但客户端的请求被REJECT掉了,导致客户端会重新尝试建立连接,wireshark抓包的结果如下 
三次握手是需要一些时间的,内核中对connect的超时限制大概是75秒,就是说如果超过75秒则connect会由于超时而返回失败,最后连接建立失败,对客户端来说是socket.error: [Errno 110] Connection timed out
对客户端来说DROP或者REJECT掉从服务端返回的包效果是基本一样的,只是对服务端来说REJECT返回了错误信息,处理上会有些区别
另一种超时是DROP发给服务端的包,由于没有返回错误信息,所以会重传SYN直到超时,返回[Errno 110] Connection timed out
# iptables -I INPUT -p tcp --dport 50007 -j DROP
主要观察网络断开或不可用时:
如果在服务端改成返回响应后就关闭连接,这是短连接的处理方式,返回正常的FIN
直接kill服务来模拟服务重启、连接关闭,可以发现返回的是RST 
在测试过程中的话,不能直接上别人家拆别人家的房子时,可以采用端口转发的方式模拟连接关闭,好处就是不需要kill别人的服务,另外连接配置起来比较方便,不用反复改服务的配置文件,推荐下Linux下简单好用的工具rinetd,能实现端口映射/转发/重定向。
rinetd软件下载
wget http://www.boutell.com/rinetd/http/rinetd.tar.gz
解压安装
tar zxvf rinetd.tar.gz
make
make install
加入一行本地地址 本地端口 远端地址 远端端口,然后运行rinetd
# vim /etc/rinetd.conf
0.0.0.0 1111 192.168.231.130 50007
# rinetd
# ./tcp_client.py
可以看到实际上通过rinetd在客户端和服务端分别建立了连接,可以像直连那样正常访问别人的服务
# netstat -lan|grep 1111
tcp 0 0 0.0.0.0:1111 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:1111 127.0.0.1:39233 ESTABLISHED
tcp 20 0 127.0.0.1:39233 127.0.0.1:1111 ESTABLISHED
# netstat -lan|grep 50007
tcp 0 0 192.168.231.131:38295 192.168.231.130:50007 ESTABLISHE
模拟连接中断,只要用pkill rinetd杀掉rinetd进就好了,效果同kill服务
Reject客户端发出的请求,非tcp-reset的返回错误,由于代码里没有处理错误,连接还保持着。一般客户端可以自行判断错误决定保持连接重试或者关掉原有连接重连,实际表现以代码为准 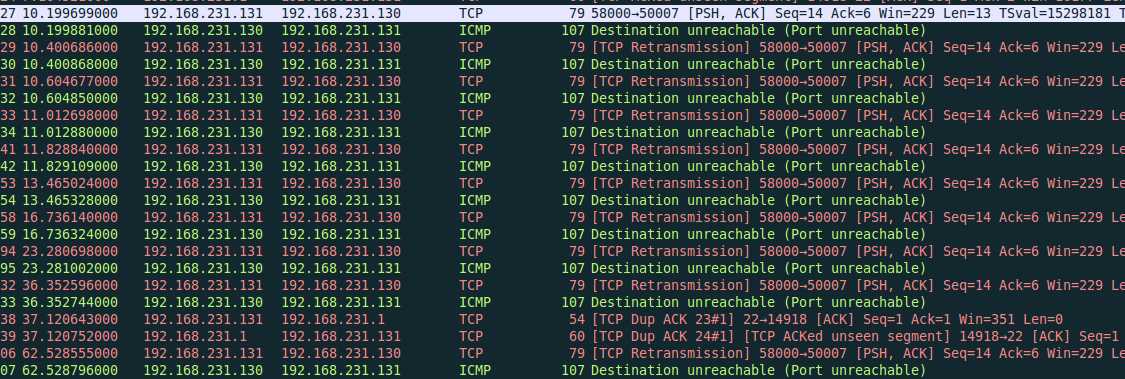
若设置的是tcp-reset,返回RST,重置连接
[Errno 104] Connection reset by peer

这类异常的模拟最好DROP掉的是服务器返回客户端的包,原因是排除掉服务器的FIN和RST, 客户端的重连不要强依赖服务器的关闭连接请求。
Drop包可以模拟发送请求超时或者连接已建立但是已不可用的情况,方法和心跳检测那节说的类似,主要需要观察断开连接的时机和触发重连的时机,有心跳检测的观察下心跳是否成功,如果长时间Drop请求再恢复后无法重连成功,那就有问题了
标签:
原文地址:http://www.cnblogs.com/opama/p/4768279.html