标签:style blog http color 使用 strong
学习是一个循序渐进的过程,我们首先来认识一下,什么是决策树。顾名思义,决策树就是拿来对一个事物做决策,作判断。那如何判断呢?凭什么判断呢?都是值得我们去思考的问题。
请看以下两个简单例子:
第一个例子
现想象一个女孩的母亲要给自己家的闺女介绍男朋友,女孩儿通过对方的一些情况来考虑要不要去,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑
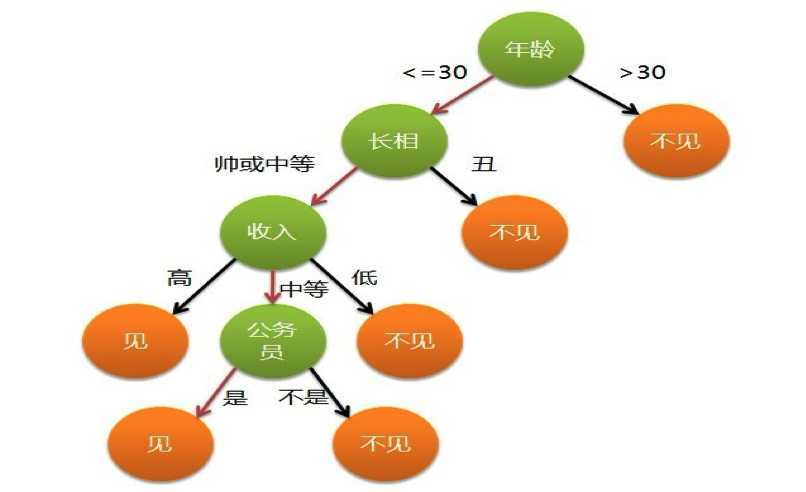
图1
第二个例子
此例子来自Tom M.Mitchell著的机器学习一书:
小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,他了解到人们决定是否打球的原因最主要取决于天气情况。而天气状况有晴,云和雨;气温用华氏温度表示;相对湿度用百分比;还有有无风。如此,我们便可以构造一棵决策树,如下(根据天气这个分类决策这天是否合适打网球):
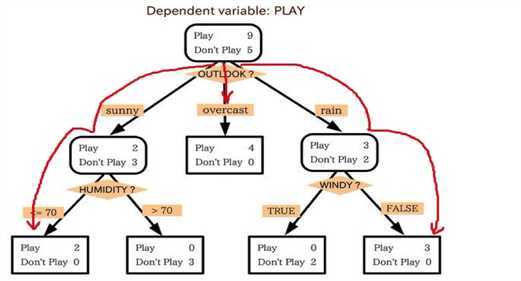
图2
上述决策树对应于以下表达式:
(Outlook=Sunny ^Humidity<=70)V (Outlook = Overcast)V (Outlook=Rain ^ Wind=Weak)
看完两个例子之后,给出决策树的定义:一种类似于流程图的树结构,其中,
每个非叶子结点表示在一个属性上的测试;
每个分支代表该测试的一个输出;
每个叶子结点代表一个类标号。
看到这里,心里应该大概有了一个决策树的样子了。然后,引出两个问题:
1:如何使用决策树分类?
怎么用?那是很简单的,给定一个元组,我从决策树的根开始,一一地找到一条从根到叶子结点符合条件的路径,那么叶子结点上保存的类预测就是我们想要的答案。因此,决策树容易转换成一种分类规则(把某个类分到哪一条路径上去)。
2:为什么决策树分类器如此流行?
1:决策树的构造不需要任何领域知识或参数设置,因此适合于探测式知识发现;
2:决策树可以处理高维数据;
3:决策树的表现形式直观,容易被理解;
4:一般来说,决策树分类器具有很好地准确率;
有了以上简单的预备知识,相信你已经迫不及待地想去构造一棵决策树玩玩了。那么,问题来了,怎么去构造这棵美丽的树呢?
很显然,有些东西我们可以猜想一下:
1、既然他是一棵树,如果要构造他,一定要从根开始构造吧?!没有根的存在其他的结点毫无意义,因此,决策树的构造将会是一个自顶向下的过程(根在最顶部);
2、当我们要向下进行延拓这棵树,那么每一次选择属性进行延拓的过程就是一个递归的过程,至于选择哪一个属性用来延拓,我们一定会学习到相应地度量方法。
下面,为大家隆重推出两个方法(算法)来解决这个问题。他们就是ID3和C4.5。因为C4.5算法是ID3算法的改进版,因此,首先来介绍一下ID3是怎么回事。
打开维基百科:
ID3算法(Iterative Dichotomiser 3 迭代二叉树3代)是一个由Ross Quinlan发明的用于决策树的算法。
这个算法是建立在奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树(简单理论)。尽管如此,该算法也不是总是生成最小的树形结构。而是一个启发式算法。奥卡姆剃刀阐述了一个信息熵的概念:
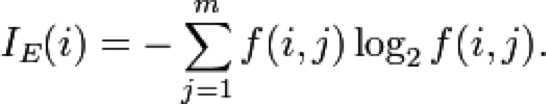
这个ID3算法可以归纳为以下几点:
看到这里,心里差不多对ID3有点感觉了。下面,引用一个网上的关于ID3思想的总结:

在大概了解了ID3是如何构造决策树之后,我们来对仍不太清楚的环节进行讨论。
a:在构造决策树的过程中,如何判断哪个属性是最佳属性,即我们要用哪个属性进行延拓决策树?
显然,这是一个属性相互PK的过程,谁输谁赢,要有一个评判的标准,专业名称就是属性选择度量。一般有三种常用的属性选择度量——信息增益(ID3),增益率(C4.5)和基尼指数(Gini指数,CART)。ID3使用信息增益作为属性选择度量,因此,本文只讲信息增益。他是由香农在研究消息的值或“信息内容”的信息论中提出来的。设结点N代表或存放分区D的元组。选择具有最高信息的属性作为结点N的分裂属性。该属性使结果分区中对元组分类所需要的信息量最小,并反映这些分区中的最小随机性或“不纯性”。这种方法使得对一个对象分类所需要的期望测试数目最小,并确保找到一棵简单的树(还记得“奥卡姆剃刀”么?)。


(因为书上讲的足够详细,且并不晦涩。所以,在次引用书本上的内容。)
下面作一些补充:
在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。所谓信息量,就是熵。
因此,我们在计算出每个属性的Gain()值之后,要挑最大的!
既然已经了解了熵以及信息增益的概念与计算方法。我们就拿一个例子来练练手吧。
eg: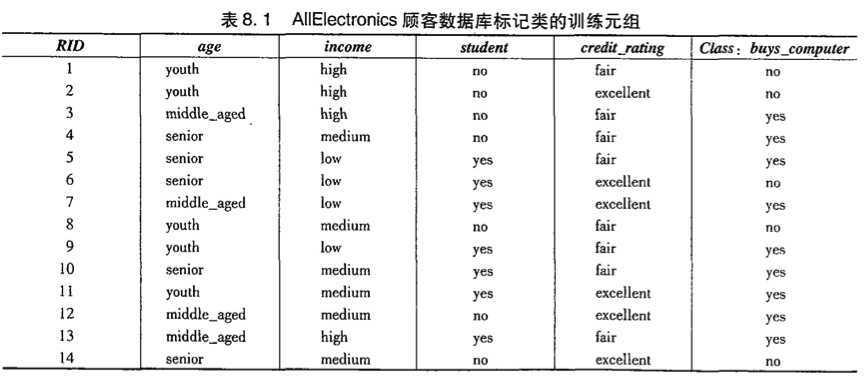
问题描述:根据以上表中的信息,得到一棵预测顾客是否会购买电脑的决策树。
步骤:
1、计算Info(buy_computer);
buy_computer是离散的(这个例子中所有的属性都是离散的,如果是连续的,可以对其进行离散化)
表中可以看出,类no对应5个元组,类yes对应9个元组。
故得:
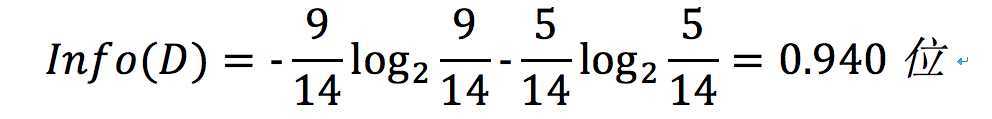
2、计算其余每个属性的期望信息需求。
age的熵:
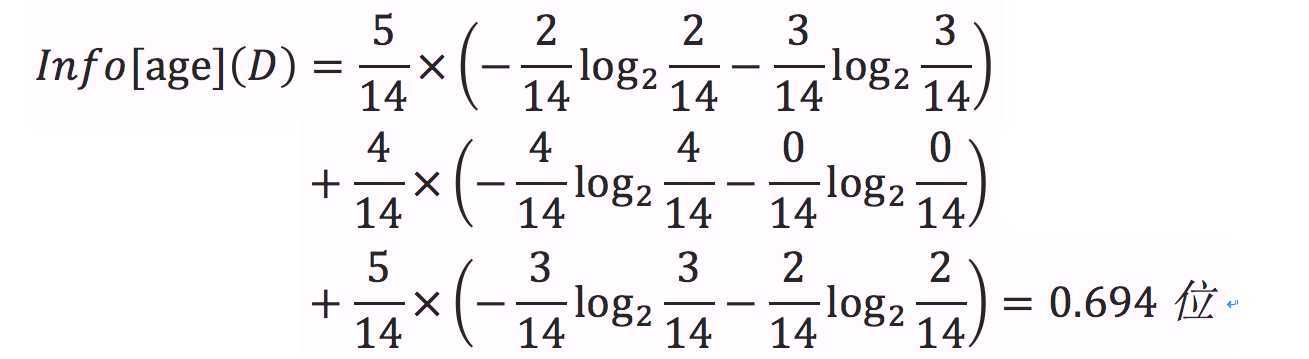
age的信息增益:
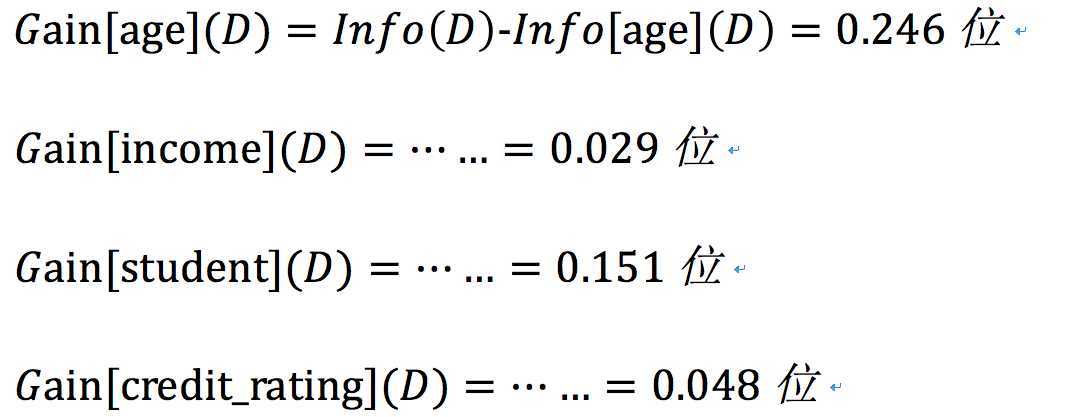
显然,age在属性中具有最高的信息增益,所以它被选作分裂属性。
得到:
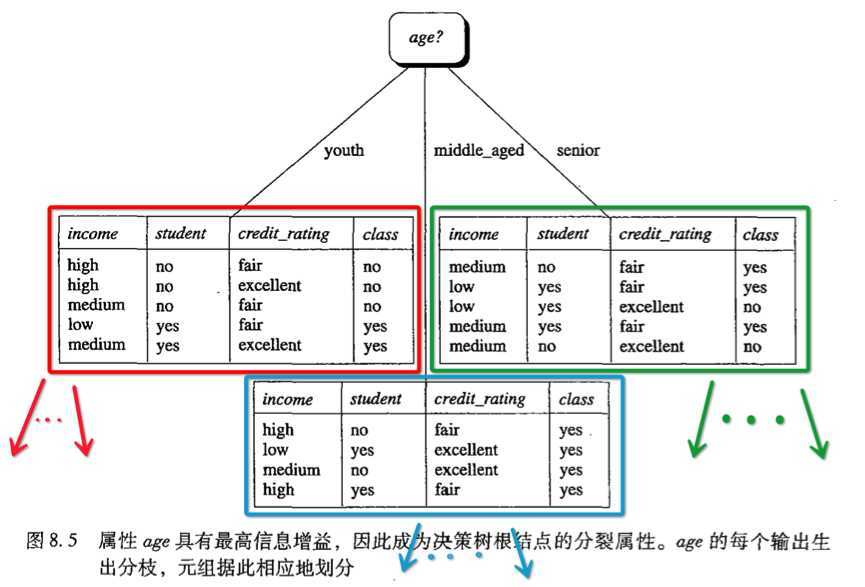
接下来,我们要做的事情就是递归下去。也就是把问题分为了3个子问题进行求解。
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/XBWer/p/3841326.html