标签:style blog http color 使用 strong
1.hashing
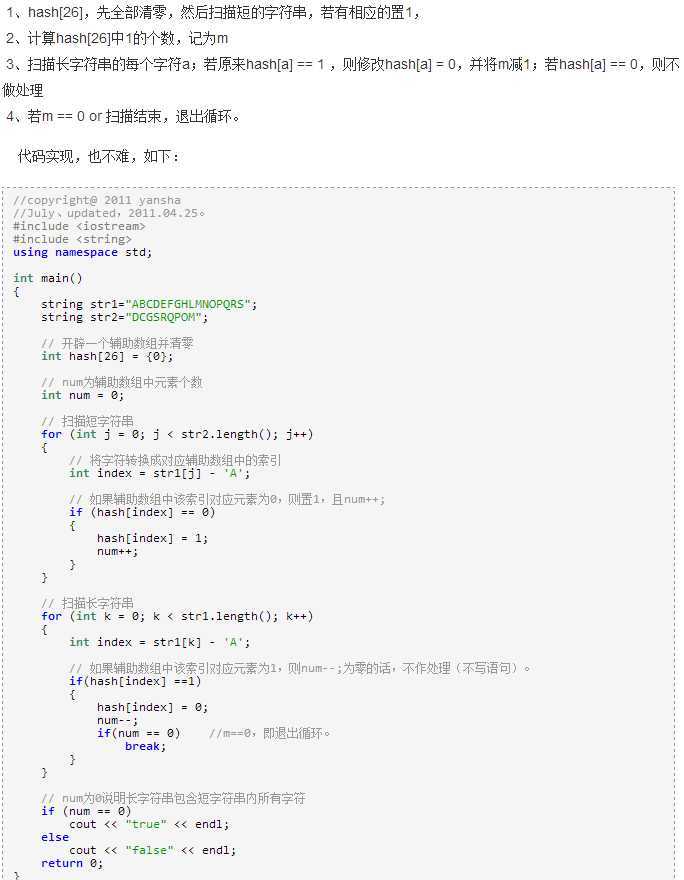
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
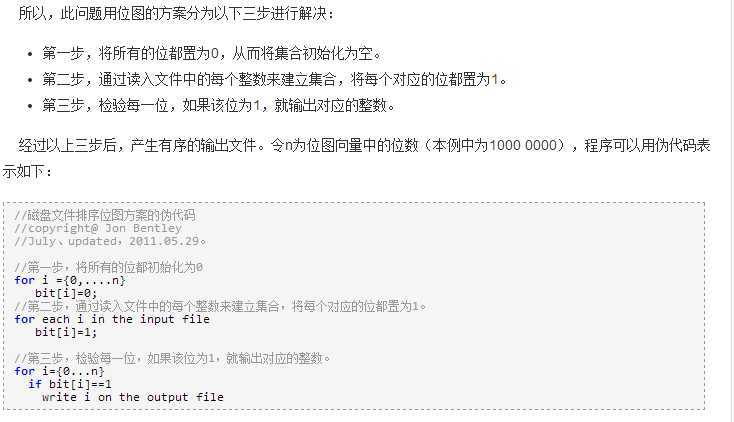
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
这个看的不是很明白。
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what","is"和"it"将对应集合的交集。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用外排序。内存可以当输入缓冲区使用。首先就是hashmap到不同文件中。

标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/menghuizuotian/p/3841747.html
