标签:
redis存储方式有很多种,但是我个人觉得最好用的并非是String存储类型,而是Hash存储类型,如果在使用redis的时候单纯的只使用到String存储类型的话,我个人觉得完全体现不了redis的特性。
redis 是一个key-value数据库,但在我看来他并不是单纯的key-value数据库,因为他相对于其他同类型的nosql数据来讲,redis提供了更多数据类型存储格式。比如如果需要使用nosql类型的数据库作为应用的缓存,我相信memcached比redis更适合,但是现实中往往很多人使用redis就仅仅只是使用String类型来做缓存。
redis有hash类型的value存储数据格式,不知道说到这里,大家有没有想到我们传统的关系型数据的数据存储格式。
其实我一直都想把redis做成一个应用与传统关系型数据库之间的媒介,从而实现尽量在高负载的环境下减少数据库的IO,并实现数据库持久化,且能够更好的实现异步与传统数据库的数据同步。
Hash
常用命令:
hget,hset,hgetall 等。
应用场景:
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
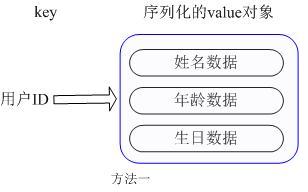
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
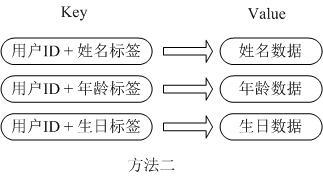
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:

也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
hash操作对应数据库的表数据存储方式其实是一样的,所以我们能够很容易切入到redis中,并把传统数据库的表数据存入到redis的hash数据类型中。这里我需要跟大家分享的是如果快速的插入对象到redis中。
网上很多资料上都有pojo存入到redis的hash中,但是大多操作都比较繁琐,这里说的繁琐是开发者需要做更多的事并不是代码的繁琐,我这里跟大家分享一个更简单方便的方法:
/**
*
* @Title: set
* @Description: 保存实体
* @return void (region + ":H:" + setKey(region)) key标示。
* @throws
*/
@SuppressWarnings({ "unchecked", "rawtypes" })
public void save(V v) {
Map<K, V> map = new JacksonHashMapper(entityClass).toHash(v);
redisTemplate.boundHashOps((K) (region + ":H:" + setKey(region)))
.putAll(map);
};
存储之后格式是: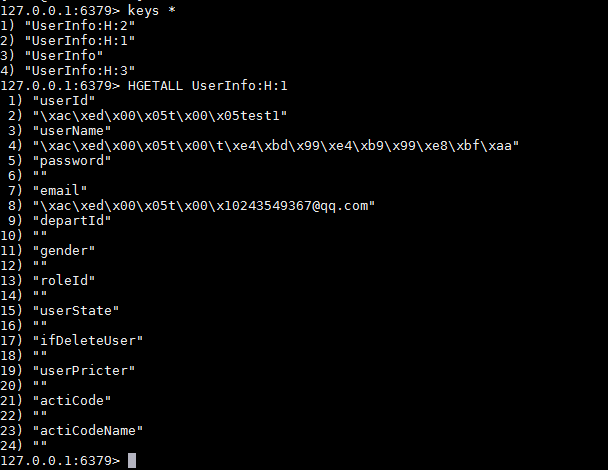
获取数据:
/**
*
* @Title: get
* @Description: 根据redis 中对象的key 获取对象信息 想请请看entries()方法,connection.hGetAll
* @return E
* @throws
*/
@SuppressWarnings({ "unchecked", "rawtypes" })
public E get(String key) {
Map<K, V> map = (Map<K, V>) redisTemplate.boundHashOps(
(K) (region + ":H:" + key)).entries();
return (E) new JacksonHashMapper(entityClass).fromHash(map);
}
以上介绍的是单个pojo的数据存储于获取,但是如果是大批量的数据,我们会不会也只是多次执行同一个方法的方式去获取对象集合的呢?答案是否定的,因为redis已经为我们提供了更好的处理方法Pipelined 管道操作,意指多个数据统一返回。
/**
*
* @Title: listConn
* @Description: 管道批量获取对象集合 传入对象的key 官方提供方法
* @return List<E>
* @throws
*/
@SuppressWarnings("unchecked")
public List<E> listPipe(final List<String> keys) {
List<Object> result = redisTemplate.executePipelined(new RedisCallback<List<Object>>() {
@Override
public List<Object> doInRedis(RedisConnection connection)
throws DataAccessException {
for (int i = 0; i < keys.size(); i++) {
byte[] key = redisTemplate.getStringSerializer().serialize(
(region + ":H:"+keys.get(i)));
connection.hGetAll(key);
}
return null;
}
});
return ((List<E>) result);
}
自己实现的方法:executeConn
@SuppressWarnings("unchecked")
public List<E> listConn(final List<String> keys) {
HashMapper<E, K, V> jhm = (HashMapper<E, K, V>) new JacksonHashMapper<E>(entityClass);
List<Object> result = redisTemplate.executeConn(new RedisCallback<Map<byte[], byte[]>>() {
@Override
public Map<byte[], byte[]> doInRedis(RedisConnection connection)
throws DataAccessException {
Map<byte[], byte[]> map = new HashMap<byte[], byte[]>();
for (int i = 0; i < keys.size(); i++) {
byte[] key = redisTemplate.getStringSerializer().serialize(
(region + ":H:"+keys.get(i)));
connection.hGetAll(key);
}
return null;
}
},jhm);
return ((List<E>) result);
}
上述方法会返回一个结果集,但是我发现返回的结果集中序列化的属性并没有反序列化完全导致输出出现乱码,先看下springdataredis提供的反序列化方法:
@SuppressWarnings({ "unchecked", "rawtypes" })
private List<Object> deserializeMixedResults(List<Object> rawValues, RedisSerializer valueSerializer,
RedisSerializer hashKeySerializer, RedisSerializer hashValueSerializer) {
if (rawValues == null) {
return null;
}
List<Object> values = new ArrayList<Object>();
for (Object rawValue : rawValues) {
if (rawValue instanceof byte[] && valueSerializer != null) {
values.add(valueSerializer.deserialize((byte[]) rawValue));
} else if (rawValue instanceof List) {
// Lists are the only potential Collections of mixed values....
values.add(deserializeMixedResults((List) rawValue, valueSerializer, hashKeySerializer, hashValueSerializer));
} else if (rawValue instanceof Set && !(((Set) rawValue).isEmpty())) {
values.add(deserializeSet((Set) rawValue, valueSerializer));
} else if (rawValue instanceof Map && !(((Map) rawValue).isEmpty())
&& ((Map) rawValue).values().iterator().next() instanceof byte[]) {
values.add(SerializationUtils.deserialize((Map) rawValue, hashKeySerializer, hashValueSerializer));
} else {
values.add(rawValue);
}
}
return values;
}
SerializationUtils类:
public static <HK, HV> Map<HK, HV> deserialize(Map<byte[], byte[]> rawValues, RedisSerializer<HK> hashKeySerializer,
RedisSerializer<HV> hashValueSerializer) {
if (rawValues == null) {
return null;
}
Map<HK, HV> map = new LinkedHashMap<HK, HV>(rawValues.size());
for (Map.Entry<byte[], byte[]> entry : rawValues.entrySet()) {
// May want to deserialize only key or value
HK key = hashKeySerializer != null ? (HK) hashKeySerializer.deserialize(entry.getKey()) : (HK) entry.getKey();
HV value = hashValueSerializer != null ? (HV) hashValueSerializer.deserialize(entry.getValue()) : (HV) entry
.getValue();
map.put(key, value);
}
return map;
}
再看下我修改的之后的反序列话方法:
@SuppressWarnings({ "unchecked", "rawtypes" })
private List<Object> deserializeMixedResults(List<Object> rawValues,RedisSerializer hashKeySerializer, RedisSerializer hashValueSerializer,HashMapper<E, K, V> jhm) {
if (rawValues == null) {
return null;
}
List<Object> values = new ArrayList<Object>();
for (Object rawValue : rawValues) {
Map<byte[], byte[]> obj = (Map<byte[], byte[]>) rawValue;
Map<K, V> map = new LinkedHashMap<K, V>(obj.size());
for (Map.Entry<byte[], byte[]> entry : obj.entrySet()) {
map.put((K) hashKeySerializer.deserialize((entry.getKey())), (V) hashValueSerializer.deserialize((entry.getValue())));
}
values.add(jhm.fromHash(map));
}
return values;
}
以上就是我处理管道结果反序列化乱码的解决方法。如果有不明白的地方,请大家指正。谢谢。
标签:
原文地址:http://my.oschina.net/yuyidi/blog/499951