标签:
从官方的文档我们可以知道,Spark的部署方式有很多种:local、Standalone、Mesos、YARN.....不同部署方式的后台处理进程是不一样的,但是如果我们从代码的角度来看,其实流程都差不多。
从代码中,我们可以得知其实Spark的部署方式其实比官方文档中介绍的还要多,这里我来列举一下:
1、local:这种方式是在本地启动一个线程来运行作业;
2、local[N]:也是本地模式,但是启动了N个线程;
3、local[*]:还是本地模式,但是用了系统中所有的核;
4、local[N,M]:这里有两个参数,第一个代表的是用到的核个数;第二个参数代表的是容许该作业失败M次。上面的几种模式没有指定M参数,其默认值都是1;
5、local-cluster[N, cores, memory]:本地伪集群模式,参数的含义我就不说了,看名字就知道;式;
6、spark:// :这是用到了Spark的Standalone模
7、(mesos|zk)://:这是Mesos模式;
8、yarn-standalone\yarn-cluster\yarn-client:这是YARN模式。前面两种代表的是集群模式;后面代表的是客户端模式;
9、simr://:这种你就不知道了吧?simr其实是Spark In MapReduce的缩写。我们知道MapReduce 1中是没有YARN的,如果你在MapReduce 1中使用Spark,那么就用这种模式吧。
总体来说,上面列出的各种部署方式运行的流程大致一样:都是从SparkContext切入,在SparkContext的初始化过程中主要做了以下几件事:
1、根据SparkConf创建SparkEnv
| 01 |
// Create the Spark execution environment (cache, map output tracker, etc) |
| 02 |
private[spark] val env = SparkEnv.create( |
| 05 |
conf.get("spark.driver.host"), |
| 06 |
conf.get("spark.driver.port").toInt, |
| 09 |
listenerBus = listenerBus) |
2、初始化executor的环境变量executorEnvs
这个步骤代码太多了,我就不贴出来。
3、创建TaskScheduler
| 1 |
// Create and start the scheduler |
| 2 |
private[spark] var taskScheduler = SparkContext.createTaskScheduler(this, master) |
4、创建DAGScheduler
| 1 |
@volatile private[spark] var dagScheduler: DAGScheduler = _ |
| 3 |
dagScheduler = new DAGScheduler(this) |
| 5 |
case e: Exception => throw |
| 6 |
newSparkException("DAGScheduler |
| 7 |
cannot be initialized due to %s".format(e.getMessage)) |
5、启动TaskScheduler
| 1 |
// start TaskScheduler after taskScheduler |
| 2 |
// sets DAGScheduler reference in DAGScheduler‘s |
那么,DAGScheduler和TaskScheduler都是什么?
DAGScheduler称为作业调度,它基于Stage的高层调度模块的实现,它为每个Job的Stages计算DAG,记录哪些RDD和Stage的输出已经实物化,然后找到最小的调度方式来运行这个Job。然后以Task Sets的形式提交给底层的任务调度模块来具体执行。
TaskScheduler称为任务调度。它是低层次的task调度接口,目前仅仅被TaskSchedulerImpl实现。这个接口可以以插件的形式应用在不同的task调度器中。每个TaskScheduler只给一个SparkContext调度task,这些调度器接受来自DAGScheduler中的每个stage提交的tasks,并负责将这些tasks提交给cluster运行。如果提交失败了,它将会重试;并处理stragglers。所有的事件都返回到DAGScheduler中。
在创建DAGScheduler的时候,程序已经将taskScheduler作为参数传进去了,代码如下:
| 01 |
def this(sc: SparkContext, taskScheduler: TaskScheduler) = { |
| 06 |
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster], |
| 07 |
sc.env.blockManager.master, |
| 11 |
def this(sc: SparkContext) = this(sc, sc.taskScheduler) |
也就是DAGScheduler封装了TaskScheduler。TaskScheduler中有两个比较重要的方法:
| 1 |
// Submit a sequence of tasks to run. |
| 2 |
def submitTasks(taskSet: TaskSet): Unit |
| 5 |
def cancelTasks(stageId: Int, interruptThread: Boolean) |
这些方法在DAGScheduler中被调用,而TaskSchedulerImpl实现了TaskScheduler,为各种调度模式提供了任务调度接口,在TaskSchedulerImpl中还实现了resourceOffers和statusUpdate两个接口给Backend调用,用于提供调度资源和更新任务状态。
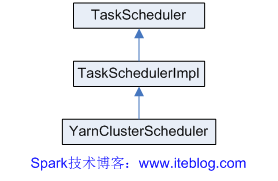
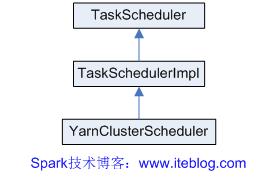
在YARN模式中,还提供了YarnClusterScheduler类,他只是简单地继承TaskSchedulerImpl类,主要重写了getRackForHost(hostPort: String)和postStartHook() 方法。继承图如下:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop
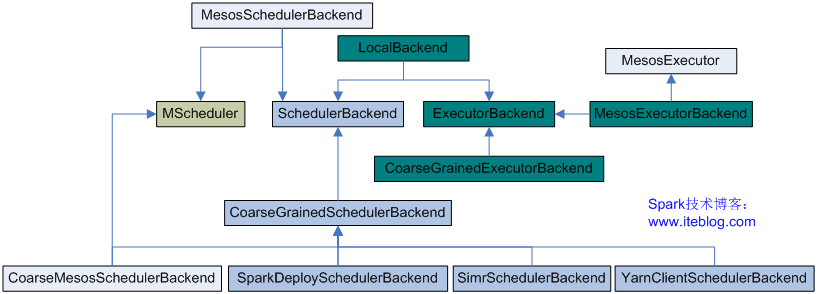
在下篇文章中,我将介绍上面九种部署模式涉及到的各种类及其之间的关系。欢迎关注本博客!这里先列出下篇文章用到的类图
Spark源码分析:多种部署方式之间的区别与联系(1)
标签:
原文地址:http://my.oschina.net/Rayn/blog/500691