标签:
主成分分析主要用于数据的降维。原始数据中数据特征的维度可能是很多的,但是这些特征并不一定都是重要的,如果我们能够将数据特征进行精简,不但能够减少存储空间,而且也有可能降低数据中的噪声干扰。
举个例子:这里有一组数据,如下 表1
2.5 1.2 -2.3 -2.8 -1 0.3
3.3 0.8 -1.8 -2.5 -0.8 0.2
每一列代表一组数据,每一行代表一种特征,可见有2个特征,即数据是2维的,我们所要做的是尽可能的降低数据复杂度,同时也要保证数据中的信息不丢失。
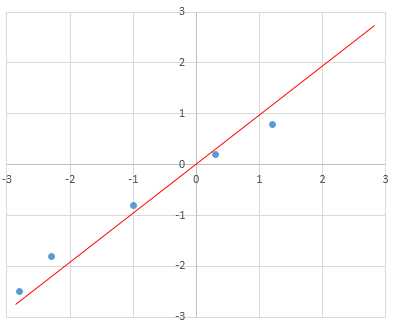
将2维的数据画在坐标系中,我们发现如果以红色的轴作为x轴(y轴与x轴垂直),那么就可以数据坐标值就变成了,x轴方向值差距较大,而y轴方向值想接近,也可以用方差来描述,x轴方向的方差较大,y轴方向的方差较小,那么如果允许少量的信息失去,仅留下x轴方向的值,那么原数据就由2维降到了1维,这就是主成分分析的主要原理,由此可见,主要就是“坐标轴的变换”,将原来2维的数据“投影”到这个1维的轴上,那么方法的关键就是如何找到这个新的“坐标轴”。
直观地理解,因为我们想尽可能的保留信息,所以在垂直于这个“新坐标轴”的方向上数据点的分布应该尽量的“扁”一些,换句话说,就是数据点在“新坐标轴”上的分布尽量的分散一些,用数学的语言表达就是使得数据点在“新坐标轴”上投影的方差尽量的大。这样,不同的两个点,投影之后也不是重叠的,最大地保留了信息。保留方差大的维度,忽略方差较小的维度,以此来降维。下面给出方差公式:
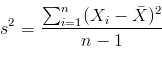
这样就足够了吗?
我们考虑一组数据从3维降为2维的情况。也就是说要找到2个“新坐标轴”,那么该如何选,前面已经知道,我们要尽量使得数据在新坐标轴方向的投影尽量的分散,也就是方差尽量的大。同时这两条坐标轴一定要正交(你可以理解为垂直)。
为什么一定要这样呢?
因为如果两个坐标轴不互相垂直,那么其中一条坐标轴一定可以沿另一条坐标轴方向分解,这样这两条坐标轴所表达的“信息”事实是有重叠的,所以要让两条坐标轴表达的“信息”相互独立,即“新坐标轴”要正交。
这个用数学的语言来表达就是所有的数据在两个“新坐标轴”的投影的协方差为0,即关于特征的两个行向量协方差为0。这个“新坐标轴”也被称为基,这个坐标轴变换也被称为基变换。
下面是协方差公式:
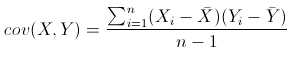
(X,Y表示两个维度的数据,相当于表1中的两行)
总结一下,就是两个方面:
1)行向量的方差尽量大,Cov(X,X) Cov(Y,Y) (方差)
2)行向量间的协方差为0 Cov(X,Y) Cov(Y,X)
列向量指的是数据降维后在“新坐标轴”投影的下的值所组成的向量
我们将这两个方面组合一个矩阵,这个矩阵称为协方差矩阵,我们的目标是使得其对角线以外的协方差为0,对角线上尽量保留方差大的维度(忽略方差较小的维度,以此来降维)。
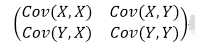
那么这个协方差矩阵如何快速得到?
由协方差的计算公式我们可以得到,将原矩阵每行都减去该行的均值,得到矩阵A,然后矩阵A乘以矩阵A的转置,最后除以N-1(N是矩阵行数)
那么如何求得”新坐标轴“(一组基)和原始数据在”新坐标轴“下的表示?
(下面引用张洋的博客,因为他写的实在太精彩了)
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据(Y即为压缩后的数据)。设Y的协方差矩阵为D,我们推导一下D与C的关系: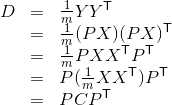
现在事情很明白了!我们要找的P不是别的,而是能让原始协方差矩阵对角化的P。换句话说,优化目标变成了寻找一个矩阵P,满足(公式)是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
(想看更加详细的解释,请移步 http://blog.codinglabs.org/articles/pca-tutorial.html)
关于矩阵P的求法,由于协方差矩阵C是实对称阵,只要求出协方差矩阵C的特征值及对应的特征向量,将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
我们先介绍主成分分析法的原理,再来体验一下计算过程(使用Matlab)。
首先初始化矩阵

矩阵减去每行的均值

计算协方差矩阵C

求解协方差矩阵的特征向量和特征值

则P = eigenvectors
由于38.0823>0.5460
保留第二个特征向量(-0.7175, -0.6966)

计算压缩后的数据Y
参考博客:
http://blog.codinglabs.org/articles/pca-tutorial.html
http://www.360doc.com/content/14/0526/06/15831056_380900310.shtml
标签:
原文地址:http://www.cnblogs.com/coolalan/p/4779923.html