标签:
上网数据
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
数据一共有11列,每一列的说明如图
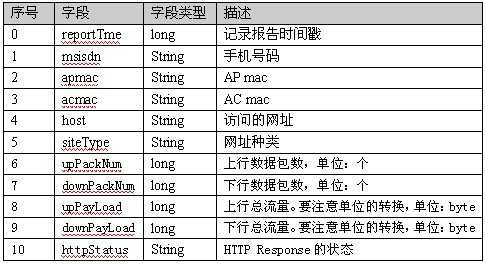
要求:求每一个用户的上行数据包数总量,下行数据包数总量,上行总流量,下行总流量
分析:
1、按照用户进行排序,
2、将不同时间段的相同用户进行分组
3、相同的用户的上网流量进行相加
下面我们将通过两种方式进行操作,虽然方式不同,但思想很重要
1、普通方法(shell 方法)
由于是找出每个用户的上网流量,所以我们对数据进行了提取,只提取手机号、上行包、下行包、上行流量、下行流量
cat file|awk -F\\t ‘{print $2,$7,$8,$9,$10}‘
排序
cat file|awk -F\\t ‘{print $2,$7,$8,$9,$10}‘|sort -k 2
13480253104 3 3 180 180
13502468823 57 102 7335 110349
13560439658 15 9 918 4938
13560439658 18 15 1116 954
13600217502 18 138 1080 186852
13602846565 15 12 1938 2910
13660577991 24 9 6960 690
13719199419 4 0 240 0
13726230503 24 27 2481 24681
13760778710 2 2 120 120
13823070001 6 3 360 180
13826544101 4 0 264 0
13922314466 12 12 3008 3720
13925057413 69 63 11058 48243
13926251106 4 0 240 0
13926435656 2 4 132 1512
15013685858 28 27 3659 3538
15920133257 20 20 3156 2936
15989002119 3 3 1938 180
18211575961 15 12 1527 2106
18320173382 21 18 9531 2412
84138413 20 16 4116 1432
分组
对于上面排好的数据进行分组,就行把相同的用户的流量合并的一起(没有相加计算,只是简单的放在一起),如
13480253104 3 3 180 180
13502468823 57 102 7335 110349
13560439658 [15 9 918 4938] [18 15 1116 954]
shell中的分组可以利用awk 中的数组
相同用户流量相加
cat HTTP_20130313143750.dat |sort -k2|awk -F\\t ‘{print $2,$7,$8,$9,$10}‘|awk ‘{a[$1]+=$2;b[$1]+=$3;c[$1]+=$4;d[$1]+=$5}END{for(i in a)print(i,a[i],b[i],c[i],d[i])}‘|sort
13480253104 3 3 180 180
13502468823 57 102 7335 110349
13560439658 33 24 2034 5892
13600217502 18 138 1080 186852
13602846565 15 12 1938 2910
13660577991 24 9 6960 690
13719199419 4 0 240 0
13726230503 24 27 2481 24681
13760778710 2 2 120 120
13823070001 6 3 360 180
13826544101 4 0 264 0
13922314466 12 12 3008 3720
13925057413 69 63 11058 48243
13926251106 4 0 240 0
13926435656 2 4 132 1512
15013685858 28 27 3659 3538
15920133257 20 20 3156 2936
15989002119 3 3 1938 180
18211575961 15 12 1527 2106
18320173382 21 18 9531 2412
84138413 20 16 4116 1432
对于上面的shell脚本我们进行了两次的awk 两次sort,显然没有必要,整理一下
cat HTTP_20130313143750.dat |awk -F\\t ‘{a[$2]+=$7;b[$2]+=$8;c[$2]+=$9;d[$2]+=$10}END{for(i in a)print(i,a[i],b[i],c[i],d[i])}‘|sort
2、由于数据量比较小可以用shell脚本解决,但是数据量大的话,处理时间变长,内存崩溃,这时就需要mr来实现
根据mr的map、reduce 函数的定义,我们很容易的找到这两个阶段的输入、输出
map阶段
输入就是每行的记录
输出是用户 每个时间段的上网流量
reduce阶段
输入是map的输出
输出是相加后的流量和
实现
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k2 = new Text();
Text v2 = new Text();
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
String[] splited = v1.toString().split("\t");
String telno = splited[1];
String uppacknum = splited[6];
String dwpacknum = splited[7];
String uppayload = splited[8];
String dwpayload = splited[9];
String data = uppacknum + "," + dwpacknum + "," + uppayload + ","
+ dwpayload;
k2.set(telno);
v2.set(data);
System.out.println(data);
context.write(k2, v2);
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
Text v3 = new Text();
@Override
protected void reduce(
Text k2,
Iterable<Text> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
long uppacknum = 0L;
long dwpacknum = 0L;
long uppayload = 0L;
long dwpayload = 0L;
String data = "";
for (Text v2 : v2s) {
String[] split = v2.toString().split(",");
uppacknum += Long.parseLong(split[0]);
dwpacknum += Long.parseLong(split[1]);
uppayload += Long.parseLong(split[2]);
dwpayload += Long.parseLong(split[3]);
data = uppacknum + "," + dwpacknum + "," + uppayload + ","
+ dwpayload;
System.out.println(data);
}
v3.set(data);
context.write(k2, v3);
}
}
这里用的是hadoop的基本类型,没有自己定义序列化类型
最后的结果
13480253104 3,3,180,180
13502468823 57,102,7335,110349
13560439658 33,24,2034,5892
13600217502 18,138,1080,186852
13602846565 15,12,1938,2910
13660577991 24,9,6960,690
13719199419 4,0,240,0
13726230503 24,27,2481,24681
13760778710 2,2,120,120
13823070001 6,3,360,180
13826544101 4,0,264,0
13922314466 12,12,3008,3720
13925057413 69,63,11058,48243
13926251106 4,0,240,0
13926435656 2,4,132,1512
15013685858 28,27,3659,3538
15920133257 20,20,3156,2936
15989002119 3,3,1938,180
18211575961 15,12,1527,2106
18320173382 21,18,9531,2412
84138413 20,16,4116,1432
标签:
原文地址:http://www.cnblogs.com/ggbond1988/p/4781318.html