标签:
|
|
课程 数据挖掘 2014 -2015 学年 第 二 学期
========================================== (题目) 关联分析之理想解法模型——对教练进行排名 要点: 1、 实验数据集可以从网上下载,也可以用以前做Clementine 用的数据集。若从网上下载,一定要注意下载地址,并对数据集做简要说明。 2、 可以用所学的任一种或多种分析方法(必须至少运用关联分析、聚类分析、分类算法其中一种),对数据集分析。 3、 挖掘过程要详细,要注意含挖掘目的,挖掘过程、算法,挖掘结果要以可视化方式展示,对挖掘结果要进行测试、分析。 4、 根据挖掘结果提出指导实践的思路、方法等。 5、 严禁抄袭。题目自拟。 6、 一定要用本设计报告模板,正文A4纸3-5页,双面打印。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
目录 一.背景介绍 2 二.模型概述 2 三.模型算法 3 Step1 归一化重大比赛获奖指标 3 Step2 数据预处理 4 Step 3 构造加权矩阵 4 Step4 计算正理想解和负理想解 4 Step5 计算各方案到正理想解和负理想解之间的距离 4 Step6 计算各方案的综合指标值并排序 5 三. 模型求解 5 四. 参考 7 五. 算法代码 8
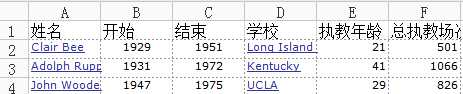
一.背景介绍 本文数据集来自美国http://www.ncaa.org/网站,完整数据在附件中。通过对这些数据进行挖掘我们可以得到一定的成果。基于关联分析的理想解法利用各大指标之间的关系,使用特定算法对数据进行处理最后得到一个排序值从而得出教练的排名。具体算法代码见附录。 我们对教练进行评比时要选取更多指标建立相对详细的评价模型。我们选取了执教年数、学员参赛场数、获胜率和重大比赛如:常规赛冠军次数、联盟锦标赛冠军次数、进入NCAA锦标赛初赛,进入NCCA四强的次数和获得NCCA冠军次数,但是这些重大比赛反映的是同一层意思,所以我们将其综合成一项指标,然后再将它与其余3个指标构成第二轮评价的指标体系。 数据格式如下:
二.模型概述 (1)先用贡献率作为权重,将常规赛冠军、联盟锦标赛冠军、NCCA锦标赛、NCCA四强、NCCA冠军,这五个指标综合成一个指标(命名为大型比赛获胜率);
(2)将执教年数、执教场次、获胜率、大型比赛获胜率,这四个指标用理想解法进行打分排名,筛选出前10名。
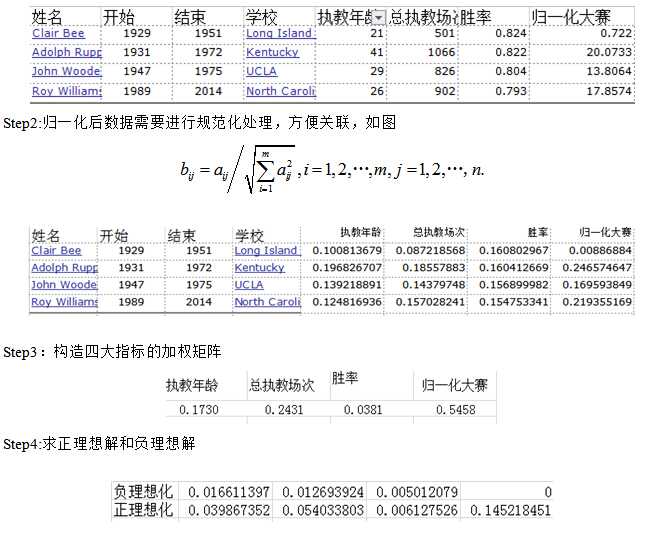
其中,理想解法中的权重用变异系数法确定。 而理想解法分为六个步骤: (1)将四个指标标准化处理; (2)将标准化后的指标进行加权求和; (3)分别求出正理想解和负理想解; (4)求出50组数据与正理想解与负理想解之间的距离; (5)求综合评价指数; (6)排名(选出前10名); 三.模型算法
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
姓名 |
执教年龄 |
总执教 场次 |
胜率 |
其他因素归一化 |
负距离 |
正距离 |
排序 |
|
39 |
1277 |
0.764 |
0.1450 |
0.1516 |
0.00747 |
0.9529 |
|
|
38 |
1256 |
0.750 |
0.1381 |
0.1447 |
0.0110 |
0.9293 |
|
|
36 |
1133 |
0.776 |
0.1452 |
0.1500 |
0.0117 |
0.9277 |
|
|
41 |
1066 |
0.822 |
0.1346 |
0.1395 |
0.0151 |
0.9026 |
|
|
34 |
1061 |
0.731 |
0.1332 |
0.1376 |
0.0190 |
0.8784 |
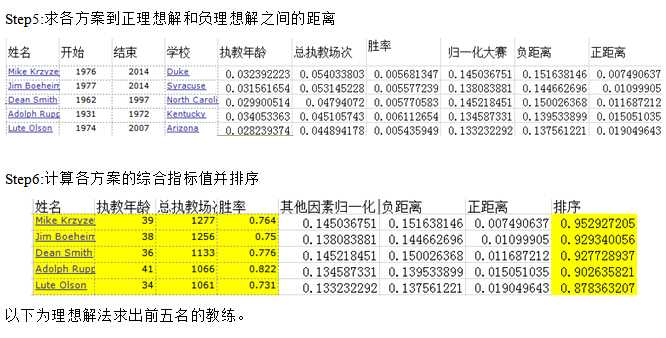
以下为结合层次分析等算法多轮筛选求出前十名的教练。
表 前10名教练
|
名次 |
1 |
2 |
3 |
4 |
5 |
|
教练 |
Mike Krzyzewski |
Jim Boeheim |
Dean Smith |
Adolph Rupp |
Lute Olson |
|
综合评价指数 |
0.9529 |
0.9293 |
0.9277 |
0.9026 |
0.8784 |
|
名次 |
6 |
7 |
8 |
9 |
10 |
|
教练 |
Bob Knight |
Jim Calhoun |
Eddie Sutton |
Denny Crum |
Roy Williams |
|
综合评价指数 |
0.8775 |
0.8619 |
0.8292 |
0.8109 |
0.7771 |
四.参考
[1] Frank R. Giordano, William P. Fox, Steven B. Horton, and Maurice D. Weir: A First Course in Mathematical Modeling, Fourth Edition.
[2] Matlab The Language of Technical Computing
五.算法代码
使用matlab软件进行数据处理,代码如下
%规范化处理 归一化-贡献值
%作者:陈锦瀚
%时间:2015.1.17
clc,
clear
load(‘second2.mat‘);%数据存放处
i=1;
j=[];
while(i<=2)
temp=var(a1(:,i:i));
j=[j,temp];
i=i+1;
end
temp=sum(j); %均值暂存处
disp(‘方差‘);
disp(j); %方差暂存处
j=j./temp;
disp(‘归一化‘);
disp(j); %变异系数暂存处
k=1;
s=[]; %归一化后数据存放处
while(k<=50)
s=[s;dot(j,a1(k:k,:))];%加权求和
k=k+1;
end
disp(s)
%TOPSIS向量规范化处理:适合虚拟方案,欧式距离
%作者:陈锦瀚
%时间:2015.1.17
clc;
clear;
load(‘second2.mat‘);%加载数据b
result=[]; %预处理数据存放处
jresult=[] ;%加权数据存放处
idearesultz=[]; %正理想化解
idearesultf=[]; %负理想化解
d=b.^2;
for i=1:4
c=sqrt(sum(d(:,i:i)));
result(:,i:i)=b(:,i:i)./c;
end
%数据预处理结束
%变异系数开始
w=[];
for i=1:4
w=[w,std(result(:,i))/mean(result(:,i))];
end
temp=sum(w);
w=w./temp;
for i=1:4
jresult(:,i:i)=result(:,i:i).*w(1,i);
end
%加权处理完毕
for i=1:4
idearesultz=[idearesultz,max(jresult(:,i:i))];
idearesultf=[idearesultf,min(jresult(:,i:i))];
end
%理想解处理完毕
sz=[]; %正距离暂存处
szz=[];
sf=[]; %负距离暂存处
sff=[];
f=[];
for i=1:50
sz=[sz;(jresult(i:i,:)-idearesultz).^2];
szz=[szz;sqrt(sum(sz(i:i,:)))];
sf=[sf;(jresult(i:i,:)-idearesultf).^2];
sff=[sff;sqrt(sum(sf(i:i,:)))];
f=[f;sff(i)/(sff(i)+szz(i))];%排序值
end
标签:
原文地址:http://www.cnblogs.com/nima/p/4784967.html