标签:
#include<iostream>
using namespace std;
#include<cstdlib>
#include<iomanip>
#include<ctime>
int main()
{
int p,i,j;
char m[100][100];
srand(time(NULL));
cout<<setfill(‘0‘);
for(i=0;i<100;i++)
{
for(j=0;j<4;j++)
{
p=rand()%26;
m[i][j]=p+‘a‘;
}
m[i][4]=‘\0‘;
cout<<setw(3)<<i+1
<<" "<<m[i]<<"\t";
}
return 0;
}
1-1. 数据压缩的另一个基本问题是“我们要压缩什么”,对此你怎样理解的?
答:压缩对象:信号空间。指:
1.物理空间,如存储器、磁盘、磁带、光盘、usb闪存盘(u盘)等数据存储介质;
2.时间区间,如传输给定消息集合所需要的时间;
3.电磁频段,如为传输给定消息集合所要求的频谱、带宽等。
1-2.数据压缩的另一个基本问题是“为什么进行压缩”,对此你又有怎样的理解?
答:1.较快地传输各种心愿(降低信道占用费用)——时间域的压缩;
2.在现有通信干线上开通更多的并行业务(如电视、传真、电话、可是图文等)——频率域的压缩;
3.降低发射功率————能量域压缩;
4.紧缩数据存储容量(降低存储费用)——空间域的压缩。
1-6.数据压缩技术是如何分类的?
答:数据压缩分为有损压缩和无损压缩。
1.有损压缩就是有失真编码,信息论中称熵压缩(不可逆压缩)。
2.无损压缩又叫做无失真、无差错编码或无噪声编码(可逆压缩)。
1.4 项目与习题
1.用你计算机上的压缩工具压缩不同文件,研究源文件的大小和类型对于压缩文件与原文件大小之比的影响。
答:(1).对于不同大小的原文件压缩后:当源文件很小或为0kb时,压缩后的文件远远大于压缩前的文件。
(2).不同类型的源文件压缩后的大小影响和大。
2.从一本通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,实现压缩。例如,在“This is the dog that belongs to my friend”中,删除is the that和to之后,任然能传递相同的意思,用被删除的单词数
与原文本的总单词数之比来衡量文本中的冗余度。用一本技术期刊的文字来重复这一试验。对于摘自不同来源的文字,我们能付救起冗余度做出定论?
答:不能就其冗余度做出定量论述。对于摘自不同来源的文字,冗余度不一样。
3、
(a)P(a1)=P(a2)=P(a3)=P(a4)=1/4
(b)P(a1)=1/2 , P(a2)=1/4 , P(a3)=P(a4)=1/8
(c)P(a1)=0.505 , P(a2)=1/4 , P(a3)=1/4 , P(a4)=0.12
答:(a): -1/4*4*log21/4
=-log22-2
=2(bit)
(b): -1/2log21/2-1/4*log21/4-2*1/8*log21/8
=1/2+1/2+3/4
=7/4
=1.75(bit)
(c): -0.505*log20.505-1/4*log21/4-1/4*log21/4-0.12*log20.12
=-0.505*log20.505+1/2+1/2-0.12*log20.12
=0.2967+1-0.12*log20.12
=1.2967-0.12*log20.12(bit)
5、
答:首先总的字母有84个,其中字母A出现21次,字母T出现23次,字母G出现16次,字母C出现24次。
则P(A)=21/84=1/4;P(T)=23/84;P(G)=16/84=4/21;P(C)=24/84=2/7.
(a)其各字母的概率值如下:
P(A)=21/84=1/4;P(T)=23/84;P(G)=16/84=4/21;P(C)=24/84=2/7.
则其一阶熵为:
-21*1/4*log2(1/4)-23*23/84*log2(23/84)-16*4/21*log2(4/21)-24*2/7*log2(2/7)=
7、做一个实验,看看一个模型能够多么准确地描述一个信源。
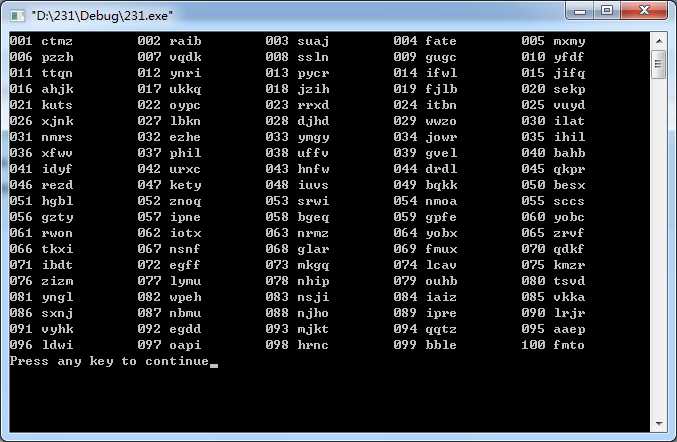
(a)编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
标签:
原文地址:http://www.cnblogs.com/huangxuecai/p/4766001.html