标签:
在项目中集合的使用非常频繁,最原始的就是数组Array,集合List提供了增加和删除的便利以及扩展,同时为了更快的搜寻效率,我们选择Map映射表。Map中我们用的最多的是hashMap,它提供了较好的查询速度,时间复杂度在O(1)。这些都是常规使用的集合。但是时常会有并发的要求,对于Map类,有一个HashTable可选,这个即实现了键值对的映射功能,同时也支持并发操作。HashTable实现原理主要是在hashMap上加了一个锁,操作hashtable时会对它上锁。这样效率就大大下降。对于低并发可能还不是很大影响,如果同时并发成百上千的访问,那么等待代价太大。
基于以上问题,java.util.concurrent包提供了一个更好的并发映射集合类ConcurrentHashMap,从字面意思可以理解为并发的哈希映射表。那么为什么这个类的效率就逼HashTable高呢,下面来分析一下ConcurrentHashMap的结构。
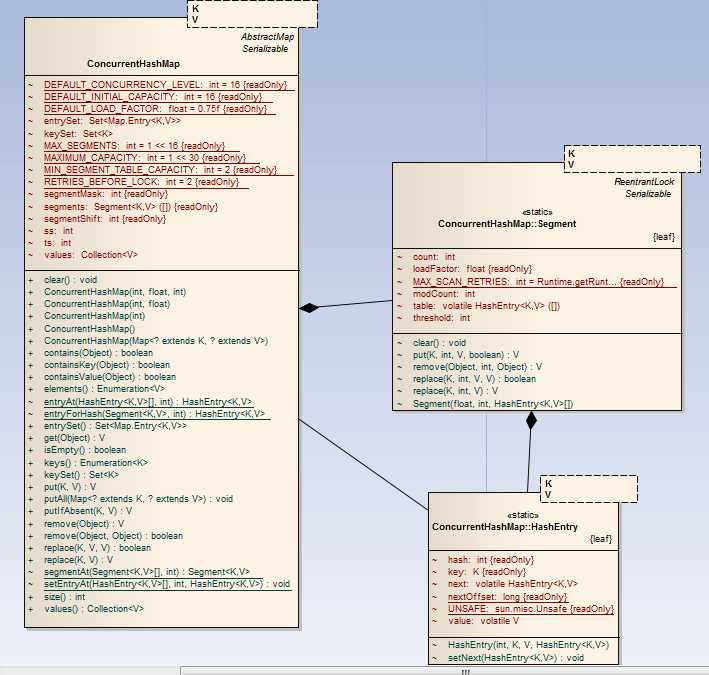
类中包含两个重要的内部类,一个为Segment,可以理解为一个段,每个段包含键值对
一个为HashEntry,储存键值对实体。
实现原理是:每次put数据时,并不会对整个类进行加锁。首先获取的是键的哈希值,根据哈希值找到对应Segment,然后对segment进行加锁。这样当多个线程对该集合操作是,如果不是元素不是在同一个Segment内,那么它们之间并不会阻塞,自然效率较高。Segment 实现类似于HashMap.
取数据则沿着存取路径反取,先找到具体Segment,然后在Segment中根据哈希值找键值对。
这是对ConcurrentHashMap的初步了解,后面会对源码分析。
标签:
原文地址:http://www.cnblogs.com/2015zzh/p/4786254.html