标签:
问题描述
一个d 维的特征向量 x=(x1,x2,...xd)T,属于M个类Ck,k=1,2,...M,在NN分类器中,每个类有nk个prototypes,记为mkj,j=1,2,...nk&&k=1,2,...M。
总体框架
特征向量x判定给离它最近的prototype所在的类,每个prototype的decision region叫做Voroni cell,而所有同类的Voronoi cell形成了这个类的decision region。
基于参数优化来学习这些prototypes,设置了一个energy function(error,risk or loss),通过最小化这个energy function来optimize the prototypes。
E=∫Lx(h(x)|x)p(x)dx
其中Lx(h(x)|x)是当x通过h(x)分类后的损失函数,p(x)表示pattern space的PDF
在实际中使用的是经验损失函数
E=1N∑n=1NLx(h(xn)|xn)
通过对梯度下降使E最小化同时最优化参数Θ(n+1)=Θ(n)?αn▽E
其中的αn需要满足一下条件
limn→∞αn=0
∑n=1∞αn=∞
∑n=1∞α2n=∞
要满足上面3个式子的话,αn=1n是可行的
符号表示
- Pk(x) x判为类别k的概率
- Pkj(x) x判为类别k,第j个prototype的概率
- C(x) x的类别
- dkj(x) x与prototype mkj的距离
原型学习算法
LVQ2.1
对于一个input pattern x,找到离它最近的两个prototypemi和mj,其中mi是x所属的类,且满足下式
min(didj,djdi)>1?w1+2
其中w是一个窗口的宽度。
那么,可以按下式更新:
mi=mi+α(t)(x?mi)
mj=mj?α(t)(x?mj)
LVQ3
相比于LVQ2.1,新增了当最近的两个prototype都是x所属的类的情况,更新如下:
mk=mk+ε(t)α(t)(x?mk),k=i,j
MLVQ3
相比于LVQ3,新增了当最近的两个prototype都不是x所属的类的情况,更新如下:
mk=mk?α(t)(x?mk),k=i,j
decision surface mapping(DSM)
比较于前面的LVQ,它没有窗口的概念,仅当距离最近的两个原型且其中距离较小的原型分类错误时才更新,假设mki是正确的但距离较大mrj错误的但距离较小则
mki=mki+α(t)(x?mki)
mrj=mrj?α(t)(x?mrj)
minimum classification error(MCE)
相比于MSE,定义了一个基于判别函数的loss function,通过最小化经验损失来最优化分类器参数,其中判别函数定义为input pattern x 与 genuine class中的最近原型mki的距离的负值
gk(x)=?minjd(x,mkj)
misclassification measure of a pattern from class k is:
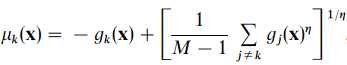
当η趋于正无穷时,可以写成μk(x)=?gk(x)+gr(x),其中r是距离x最近的非同类原型
将gk(x)带入\mu_k(x)中,则在1-NN中μk(x)=d(x,mki)?d(x,mrj)
可知,分类正确,则μk为负;分类错误,则μk为正
如此,则将损失函数定义为lk(x)=lk(μk)=11+e?ξμk
在一个training sample set中,经验平均损失为
L0=1N∑n=1N∑k=1Mlk(xn)I(xn∈Ck)
其它的原型学习方法还有SAA,DA,MSE,MAXP,在此不再复述
本文主要引自paper Evaluation of prototype learning algorithms for nearest-neighbor classifier in application to handwritten character recognition
本文讲述的内容并不完全正确,如有错误欢迎指点 ^)^
prototype learning
标签:
原文地址:http://www.cnblogs.com/MaiYatang/p/4787121.html