标签:style blog http color 使用 strong
转自:http://blog.csdn.net/hguisu/article/details/7449955
使用TCP/IP协议进行网络应用开发的朋友首先要面对的就是对IP地址信息的处理。IP地址其实有三种不同的表示格式:
1)Ascii(网络点分字符串)-
2) 网络地址(32位无符号整形,网络字节序,大头)
3)主机地址 (主机字节序)
IP地址是IP网络中数据传输的依据,它标识了IP网络中的一个连接,一台主机可以有多个IP地址,IP分组中的IP地址在网络传输中将保持不变。下面具体介绍IP地址的三种不同表示格式。
这是我们最常见的表示格式,比如某机的IP地址可能为“202.101.105.66”。事实上,对于Ipv4(IP版本)来说,IP地址是由一个32位
的二进制数所构成,但这样一串数字序列无疑是十分冗长并且难以阅读和记忆的。为了方便人们的记忆和使用,就将这串数字序列分成4组,每组8位,并改为用
10进制数进行表示,最后用小原点隔开,于是就演变成了“点分10进制表示格式”。
来看看刚才那个IP地址的具体转化过程:
IP实际地址:11001010011001010110100101000010
分成4组后: 11001010 01100101 01101001 01000010
十进制表示: 202 101 105 66
点分表示: 202.101.105.66
网络字节顺序格式和主机字节顺序格式一样,都只在进行网络开发中才会遇到。因此,在下面的介绍中,我假设读者对Socket编程知识有一定的基础。
在网络传输中,TCP/IP协议在保存IP地址这个32位二进制数时,协议规定采用在低位存储地址中包含数据的高位字节的存储顺序(大头),这种顺序格式就被称为网络字节顺序格式。在实际网络传输时,数据按照每32位二进制数为一组进行传输,由于存储顺序的影响,实际的字节传输顺序是由高位字节到低位字节的传输顺序。
为了使通信的双方都能够理解数据分组所携带的源地址、目的地址以及分组的长度等二进制信息,无论是主机还是路由器,在发送每一个分组以前,都必须将二
进制信息转换为TCP/IP标准的网络字节顺序格式。网络字节顺序格式的地址不受主机、路由器类型的影响,它的表示是唯一的。
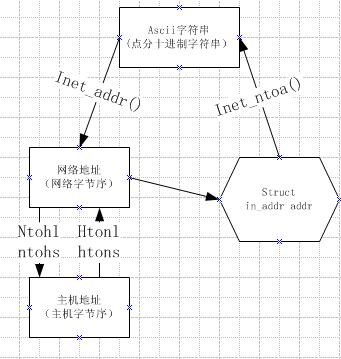
在Socket编程开发中,通过函数inet_addr和inet_ntoa可以实现点分字符串与网络字节顺序格式IP地址之间的转换。
inet_addr函数原型如下:
函数中的参数cp指向网络中标准的点分地址字符串,其中每个以点分开的数字不可以大于255,这些数字可以是十进制、八进制、十六进制或者混合使用。如
“10.23.2.3”、“012.003.002.024”、“0xa.0x3.0x14.0x2”、“10.003.2.0x12”。
我们在前面的socket编程提到client端的代码,连接本地端口:
主机字节顺序格式顾名思义,其IP地址的格式是和具体主机或者路由器相关的。对于不同的主机,在进行IP地址的存储时有不同的格式,比如对于
Motorola 68k系列主机,其HBO与NBO是相同的。而对于Intel x86系列,HBO与NBO则正好相反。
在Socket编程中,有四个函数来完成主机字节顺序格式和网络字节顺序格式之间的转换,它们是:htonl、htons、ntohl、和ntohs。
htons和ntohs完成16位无符号数的相互转换,htonl和ntohl完成32位无符号数的相互转换。
在实际应用中我们常见到将端口号转换的例子(如上例)。这是因为,如果用户输入一个数字,而且将指定使用这一数字作为端口号,应用程序则必须在使用它建立
地址以前,把它从主机字节顺序转换成网络字节顺序(使用htons()函数),以遵守TCP/IP协议规定的存储标准。相应地,如果应用程序希望显示包含
于某一地址中的端口号(例如从getpeername()函数中返回的),这一端口号就必须在被显示前从网络顺序转换到主机顺序(使用ntohs()函
数)。
那么,对于IP地址,主机字节顺序格式的转换又有哪些应用呢?
应用一,如果想知道从202.156.2.23到202.156.9.65这两个IP之间到底有多少个主机地址怎么办?这时就可以将两个IP地址转换为主机字节顺序的格式然后相减来得到,具体的实现如下:
应用二,如果对一个网段进行扫描,比如,当前正在扫描202.156.23.255,怎么让程序知道下一个应扫的IP是202.156.24.0?这时可以将当前IP转换成主机字节顺序格式并加1后,在转换回网络格式
即可,具体实现如下:
总结
介绍了IP地址的三种不同表示格式,包括各种格式产生的原因、具体含义以及在Socket编程开发中的一些应用。在实际应用中,必须遵循应用时所应采用的格式标准,同时还应灵活运用格式间的相互转换以及计算技巧。
|
字节序又称端序,尾序,英文:Endianness。在计算机科学领域中,字节序是指存放多字节数据的字节(byte)的顺序,典型的情况是整数在内存中的存放方式和网络传输的传输顺序。Endianness有时候也可以用指位序(bit)。 一般而言,字节序指示了一个UCS-2字符的哪个字节存储在低地址。如果LSByte 在MSByte的前面,即LSB为低地址,则该字节序是小端序;反之则是大端序。在网络编程中,字节序是一个必须被考虑的因素,因为不同的处理器体系可能采用不同的字节序。在多平台的代码编程中,字节序可能会导致难以察觉的bug。 名词: 最低有效位(the least significant
bit,lsb):是指一个二进制数字中的第0位(即最低位),具有权值为2^0,可以用它来检测数的奇偶性。与之相反的称之为最高有效位。在大端序中,lsb指最右边的位。
最高有效位(the Most Significant Bit,msb):是指一个n位。与之相反的称之为大端序中,msb即指最左端的位。 |
|
单字节(abyte):大部分处理器以相同的顺序处理位元(bit),因此单字节的存放方法和传输方式一般相同。 多字节:如整数(32位机中一般占4字节),多字节对象被存储为连续的字节序列,数据的内存地址则是该内存地址的最小地址。如long型数据的地址是ox001, ox002, ox003,ox004。则该数据的内存地址是ox001。 在不同的处理器的存放多字节数据的方式主要有两种: 大端序(英文名称为big endian):指从最高位起存,位数最大的数字在最前,即高字节存于内存低地址,低字节存于内存高地址, 从最高有效字节到最低有效字节的顺序存储对象。 小端序(英文名称为little endian):指从对低位起存,位数最小的数字在最前。 即低字节存于内存低地址,高字节存于内存高地址,从最低有效字节到最高有效字节的顺序存储对象。 简单打个比方说,十进制数12345。1的位数最高,是万位;5的位数最低,是个位。 大端序的话,就是从万位开始存,表示为12345; 再如一个long型数据0x12345678的存储表示: 大端序存储表示:
小端序的存储表示:
|
2)网络序
网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP协议中定义大端序为网络字节序。
socketAPI定义了一组转换函数,用于16和32bit整数在网络序和本机字节序之间的转换。htonl,htons用于本机序转换到网络序;ntohl,ntohs用于网络序转换到本机序。
3)位序
一般用于描述串行设备的传输顺序。一般硬件传输采用小端序(先传低位),但I2C协议采用大端序。网络协议中只有数据链路层的底端会涉及到。
4)处理器体系
1)小端序体系:x86,MOS Technology 6502,Z80,VAX,PDP-11等处理器为Littleendian。
2)大端序体系:Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等处理器为Big endian
3)可配置:ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARCV9, MIPS, PA-RISC and IA64的字节序是可配置的。
5) 编程判断大端序和小端序
打开VS的内存窗口,查看内存存储方式:
设定断点:
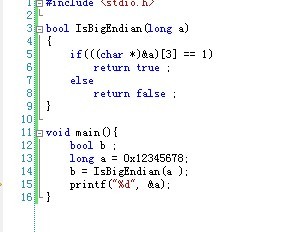
打开 debug——>window——>Memory
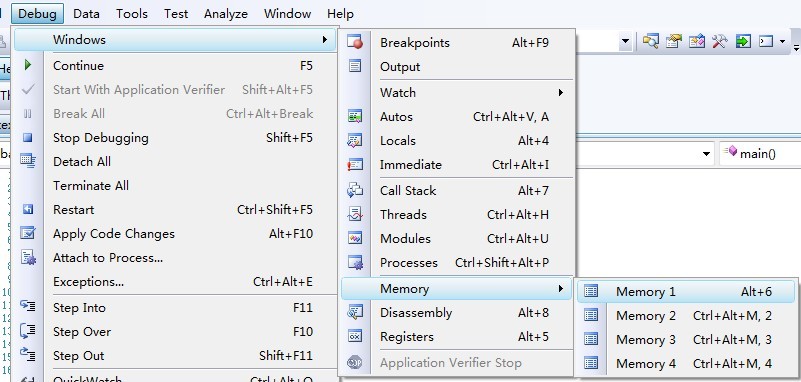
查看变量a 的地址:0x002BFE50

查看内存地址:
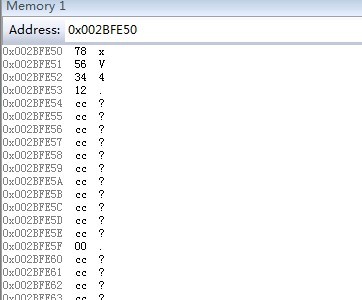
从上面看出我使用的x86 ,是小端序。
从而验证 b =false是正确的。
IP地址的三种表示格式及在Socket编程中的应用,布布扣,bubuko.com
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/segdump/p/3843812.html