标签:
学习文献主要是:
http://blog.csdn.net/heiyeshuwu/article/details/44117473
http://my.oschina.net/leejun2005/blog/150086
simHash产生背景:
1:事件,爬虫中不可避免会爬出许多相似的html文本信息,全部存储是意义不大,而且展现出现体验也会下降。
2:传统的方式有,直接使用距离来体现文本的相似程度,有欧氏距离、海明距离或者余弦角度等等;-------无法扩展到海量数据
传统hash方式,例如md5,设计目的就是使得均匀分布,也就是差异小的文本,也会有较大的差异值;----hash值不能反映内容的差异度
simHash产生过程如下:

说明:
1:对文档分词,产生特征向量,也就是用特征向量来替换原文档。例如文档1=V(v1,v2,...vn)
2:统计词的频数作为该词的权重,也就是频次越大则权重值越大,当然也可以用其他的来代替,比如只用是否存在,存在为1也就是权重为1,不存在就为0,表示权重为0
3:选择一个hash函数,对特征值进行hash,hash到f位上,有就是1,否则为0
4:转型,若f位中1则为1,0则为-1
5:同位相加,则会得到f个数值,最后判定压缩,大于0则为1,否则为0
相同思想的随机超平面hash算法:
随机超平面hash算法非常简单,对于一个n维向量v,要得到一个f位的签名(f<<n),算法如下:
1,随机产生f个n维的向量r1,…rf;
2,对每一个向量ri,如果v与ri的点积大于0,则最终签名的第i位为1,否则为0.
为什么simhash能够压缩数据,降维度?
实际场景,查看某个网页是不是和网页库中是否有相似的网页,有则丢弃了,没有就需要加入库中,那么如何做到识别出相同呢?
这里用到的是simhash值的汉明距离,通过应用在simhash位数是64位时,认为距离为3或者以下的相似度为高度相似,也就认为是相同的。
问题转变成如何快速判断是否存在汉明距离是等于或者小于3。
方案1:64bit在3个有变化或者2个或1个,或者0个,也就是C643,C642,C641,C640和为43745,大致有4万组合,也就是4万多个需要查询看库中是否和它相同。(已经有了simhash库了)

方案2:扩展原库,也就是将原来每个simhash值进行组合,也就要是要扩大是4万多倍的空间,时间才达到一次查询,(已经有了simhash库了)

实际应用的方法,利用抽屉原理,也就是最多3个出现变化,如果将64位分块分成4块,这样至少有块肯定没有变化,那么意味着有16bit会完全相同。
思维过程就是:
对原始的simhash进行复制4份,那么相当于空间上增加了4倍,这样让查询上,只需要4次查询,就会使得由原始库10亿变成了234-16也就是100万左右的记录数了,显然大大缩减了;
变成了数据集是100万左右的记录数48bit的simhash的库,对应查询目标也变成了48bit的量了。如果再用类似处理方案一来处理,那么就是变成了18473次查询,考虑前期也查了也就是共有18473+4=18477次查询。
显然通过增加4倍的空间,使得查询量由4万多缩减到接近2万了。
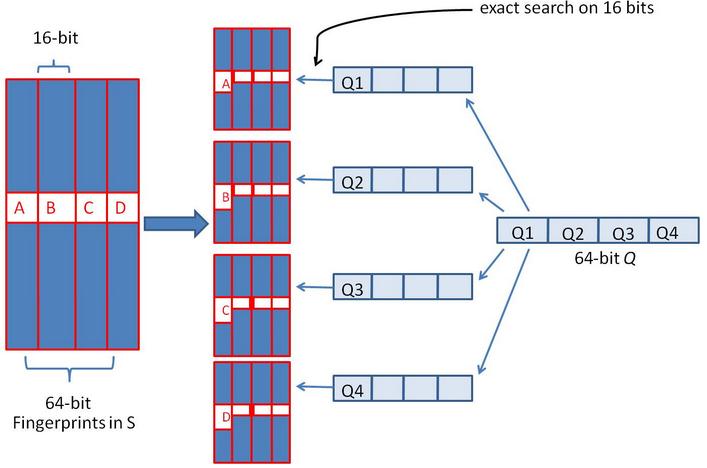
当然我们也可以继续进行分块,也就是类似处理,100万进行复制,整体就是利用空间来减少查询次数。这两个是一对矛盾。
论文:detecting near-duplicates for web crawling
http://www.docin.com/p-46955266.html
至此,simhash的介绍就到此了,其他就是各种应用场景了,文章2个链接存有就不重复了;
这里主要是通过这3个文献,记录了自己的学习simhash的理解心得分享给大家,理解有问题之处,还望大家指出。
路漫漫,求索之
标签:
原文地址:http://www.cnblogs.com/miner007/p/4790428.html