标签:
刚好把Python基础篇看完了,发现还是有很多没看懂滴!就想试试写第一个非常简单的爬虫来感受一下
获取整个页面的数据-用三种方法实现
#!/usr/bin/python
#coding = utf-8
#File Name: test.py
#Author: vforbox
#Mail: vforbox@gmail.com
#Created Time: 2015-9-8
import urllib2
response = urllib2.urlopen("http://tieba.baidu.com/p/2460150866")
print response.read()
#导入urllib2模块
‘‘‘调用urllib2模块里面的urlopen方法,传入一个URL,这个网址是百度贴吧的一个页面,协议是HTTP(可以是 FTP,FILE,HTTPS)
urlopen一般接受三个参数,它的参数为:urlopen(url,data,timeout)
url:即URL
data:访问url时要传送的数据
timeout:默认socket._GLOBAL_DEFAULT_TIMEOUT
第一个参数URL是必须要传送的,在这个例子里传送了百度贴吧的URL
执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面
response对象有一个read方法,可以返回获取到的网页内容‘‘‘
[root@test test]# python test.py
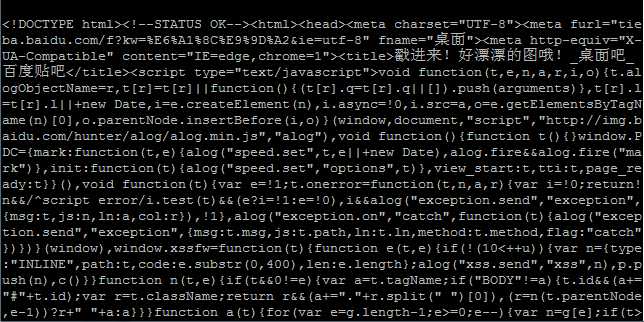
#!/usr/bin/python
#coding = utf-8
#File Name: test.py
#Author: vforbox
#Mail: vforbox@gmail.com
#Created Time: 2015-9-8
import urllib2
request = urllib2.Request("http://tieba.baidu.com/p/2460150866")
response = urllib2.urlopen(request)
print response.read()
#urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data
#和上一个比,中间多了一个request对象
#在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确
#!/usr/bin/python #coding = utf-8 #File Name: test.py #Author: vforbox #Mail: vforbox@gmail.com #Created Time: 2015-9-8
import urllib def setHtml(url): page = urllib.urlopen(url) html = page.read() return html html = setHtml("http://tieba.baidu.com/p/2460150866") print html #Urllib 模块提供了读取web页面数据的接口,可以像读取本地文件一样读取www和ftp上的数据 # 首先,定义了一个setHtml()函数:urllib.urlopen()方法用于打开一个URL地址 # read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来 # 执行程序就会把整个网页打印输出
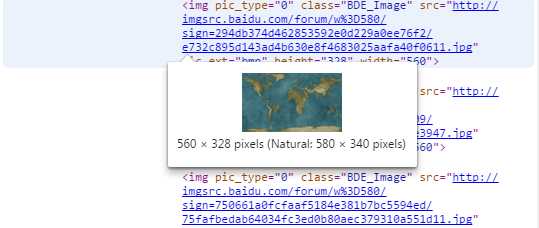
筛选页面中想要的数据
#!/usr/bin/python
#coding=utf-8
#File Name: test.py
#Author: vforbox
#Mail: vforbox@gmail.com
#Created Time: 2015-9-8
import urllib
import re
def Html(url):
h = urllib.urlopen(url)
m = h.read()
return m
def Img(html):
reg = r‘src="(.+?\.jpg)" pic_ext‘
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist
html = Html("http://tieba.baidu.com/p/2460150866")
print Img(html)
#创建了setImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
#re.compile() 可以把正则表达式编译成一个正则表达式对象
#re.findall() 方法读取html 中包含 imgre(正则表达式)的数据
#运行脚本将得到整个页面中包含图片的URL地址
将页面筛选的数据保存到本地
#!/usr/bin/python
#coding=utf-8
#File Name: test.py
#Author: vforbox
#Mail: vforbox@gmail.com
#Created Time: 2015-9-8
import urllib
import re
def Html(url):
h = urllib.urlopen(url)
m = h.read()
return m
def Img(html):
reg = r‘src="(.+?\.jpg)" pic_ext‘
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for i in imglist:
urllib.urlretrieve(i,‘%s.jpg‘ % x)
x+=1
html = Html("http://tieba.baidu.com/p/2460150866")
print Img(html)
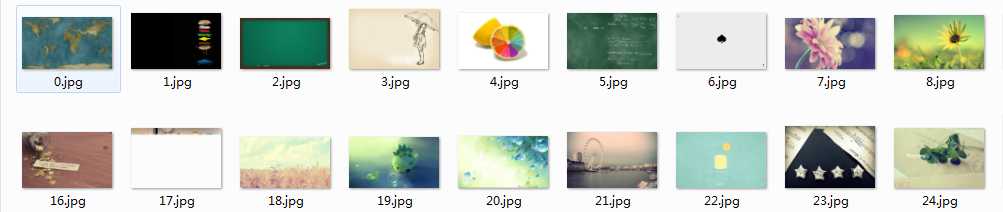
#这里的核心是用到了urllib.urlretrieve()方法,直接将远程数据下载到本地
#通过一个for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1
#保存的位置默认为程序的存放目录,程序运行完成,将在目录下看到下载到本地的文件
标签:
原文地址:http://www.cnblogs.com/vforbox/p/4791778.html