标签:
libsvm是台湾国立大学的林智仁开发的svm工具箱,有matlab,C++,python,java的接口。本文对exe版本和matlab版本的使用进行说明。
libsvm可以在 http://www.csie.ntu.edu.tw/~cjlin/libsvm/ 官网上进行下载,我下载的是libsvm-3.12
exe 版本
libsvm的exe版本在windows文件夹下,主要包含3个exe, svm-train.exe, svm-scale.exe, svm-predict.exe
(1)第一步,将训练集数据准备成Libsvm的要求格式,train.txt
<label> <index1>:<value1> <index2>:<value2> ...
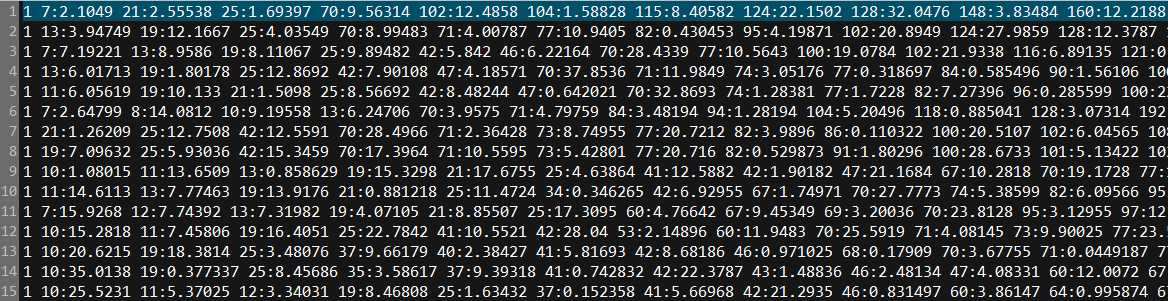
label是样本所属类别,在计算分类的准确率时使用,如果不知道样本label,可随意写一个数,index是第几维特征,一般从1开始(在包含precomputed kernel的时候从0开始),这种格式的好处是如果特征比较稀疏,就不必每一维都表示出来。
(2)第二步,用svm-scale.exe工具将训练数据 scale到[0,1]或者[-1,1]的区间内,这样的好处是对特征进行预处理,避免了数据大小不均衡计算的时候产生的问题,还可以加速。
Usage: svm-scale [options] data_filename options: -l lower : x scaling lower limit (default -1) -u upper : x scaling upper limit (default +1) -y y_lower y_upper : y scaling limits (default: no y scaling) -s save_filename : save scaling parameters to save_filename -r restore_filename : restore scaling parameters from restore_filename
比如我的特征都是正的,在cmd中进入libsvm3.20\windows目录下,svm-scale -l 0 -u 1 -s range train.txt > train.scale
其中range保存了训练数据scale的一些参数,对测试数据进行scale时要 -r 这些参数,使得训练数据和测试数据的scale保持一致。
(3)获得train.scale后,就可以用svm-train.exe 进行训练了
Usage: svm-train [options] training_set_file [model_file]
options:
-s svm_type : set type of SVM (default 0)
0 -- C-SVC (multi-class classification)
1 -- nu-SVC (multi-class classification)
2 -- one-class SVM
3 -- epsilon-SVR (regression)
4 -- nu-SVR (regression)
-t kernel_type : set type of kernel function (default 2)
0 -- linear: u‘*v
1 -- polynomial: (gamma*u‘*v + coef0)^degree
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u‘*v + coef0)
4 -- precomputed kernel (kernel values in training_set_file)
-d degree : set degree in kernel function (default 3)
-g gamma : set gamma in kernel function (default 1/num_features)
-r coef0 : set coef0 in kernel function (default 0)
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB (default 100)
-e epsilon : set tolerance of termination criterion (default 0.001)
-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)
-b probability_estimates : whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1)
-v n: n-fold cross validation mode
-q : quiet mode (no outputs)
The k in the -g option means the number of attributes in the input data.
option -v randomly splits the data into n parts and calculates cross
validation accuracy/mean squared error on them.
obj是svm文件转换为二次规划求解得到的最小值, rho是决策函数中的常数项,nSv和nBSV是连个类别的支持向量数目。
(4)进入测试阶段,测试数据也要按libsvm要求的格式,并且调用 train scale过程中的参数进行scale
svm-scale.exe -r range test.txt test.scale
(5)利用svm-predict.ex
`svm-predict‘Usage: svm-predict [options] test_file model_file output_file
options: -b probability_estimates: whether to predict probability estimates, 0 or 1 (default 0); for one-class SVM only 0 is supported model_file is the model file generated by svm-train. test_file is the test data you want to predict. svm-predict will produce output in the output_file.
svm-predict.exe test.scale train.model output
-b选1时进行概率预测,这样会比较慢, 程序会输出预测正确率accuracy, 并将预测的Label保存在output中
(6) 一些实用技巧:
Tips on Practical Use ===================== * Scale your data. For example, scale each attribute to [0,1] or [-1,+1]. * For C-SVC, consider using the model selection tool in the tools directory. * nu in nu-SVC/one-class-SVM/nu-SVR approximates the fraction of training errors and support vectors. * If data for classification are unbalanced (e.g. many positive and few negative), try different penalty parameters C by -wi (see examples below). * Specify larger cache size (i.e., larger -m) for huge problems.
matlab 版本
一、matlab libsvm的安装
matlab的libsvm首先要进行编译 ,参考rache zhang的博文 http://blog.csdn.net/abcjennifer/article/details/7370177
(1)设置path
File->set path ->add with subfolders->加入libsvm-3.11文件夹的路径
(2)在matlab中编译
在matlab中进入libsvm/matlab目录,
>> make
目的:将libsvm-3.11\matlab 中 libsvmwrite.c 等 C++文件编译成 libsvmread.mexw32 等matlab文件,这样就可以在command window中被直接调用了。
注意:在最外面的Readme中有提到已经有编译好的文件,比如在libsvm-3.12\windows中也会看到libsvmread.mexw32,但这里不要被误导!还是需要你自己再编译一遍的!(还有如果matlab版本太低,如matlab 7.0是不能用VS作为编译器的,只能用VC++ 6.0,这是我劝你给matlab升级吧!别装vc了~我就是这样,升级到Matlab 2011b就可以用VS2008做编译器了)
(3)加载数据集
直接 load heat_scale 时会报错
这是因为heart_scale是libsvm的数据格式,matlab无法读取!按照博客里面改成 libsvmread(heartscale) 工作空间中仍旧仍没出现对应的matlab数据,晕 调了半天才发现是没显示出来。 这时去查libsvmread()的定义,改成
[heart_scale_label, heart_scale_inst] = libsvmread(‘../heart_scale‘);
成功啦,在matlab工作空间中将libsvm要求的格式 label是n*1, inst存的是特征 n*mfea
一、matlab libsvm的使用
matlab> model = svmtrain(training_label_vector, training_instance_matrix [, ‘libsvm_options‘]); -training_label_vector: An m by 1 vector of training labels (type must be double). -training_instance_matrix: An m by n matrix of m training instances with n features. It can be dense or sparse (type must be double). -libsvm_options: A string of training options in the same format as that of LIBSVM. matlab> [predicted_label, accuracy, decision_values/prob_estimates] = svmpredict(testing_label_vector, testing_instance_matrix, model [, ‘libsvm_options‘]); -testing_label_vector: An m by 1 vector of prediction labels. If labels of test data are unknown, simply use any random values. (type must be double) -testing_instance_matrix: An m by n matrix of m testing instances with n features. It can be dense or sparse. (type must be double) -model: The output of svmtrain. -libsvm_options: A string of testing options in the same format as that of LIBSVM.
lib SVM训练得到的model的各个参数的意义,见一篇总结的很好的blog:
http://blog.csdn.net/kobesdu/article/details/8966517
标签:
原文地址:http://www.cnblogs.com/cookcoder-mr/p/4796204.html