标签:
hadoop伪分布安装
?
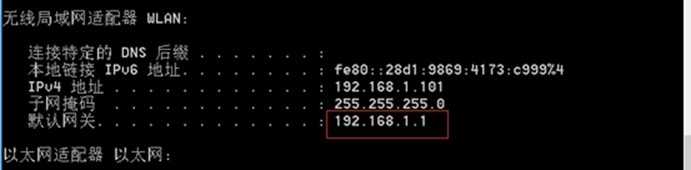
1.1(桥接模式)设置静态IP ,,修改配置文件,虚拟机IP192.168.1.99重启网卡,网关192.168.1.1是物理机下面的默认网关,
执行命令
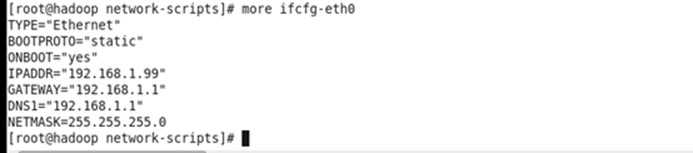
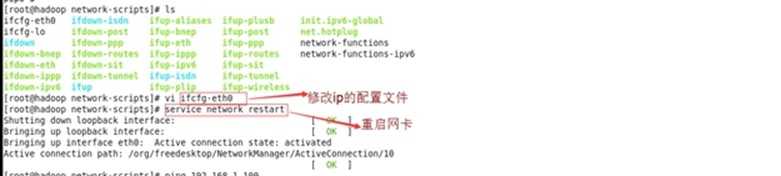
vi /etc/sysconfig/network-scripts/ifcfg-eh0
?
修改内容:
TYPE="Ethernet"
BOOTPROTO="static"
ONBOOT="yes"
IPADDR="192.168.1.99"
GATEWAY="192.168.1.1"
DNS1="192.168.1.1"
NETMASK=255.255.255.0
?
重启网卡,执行命令service network restart
?
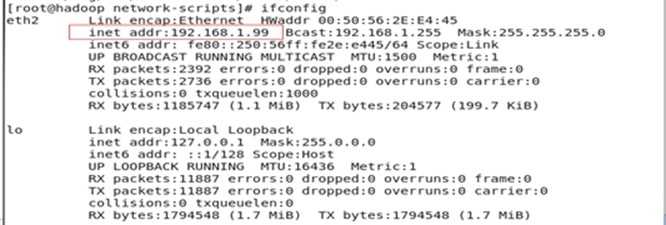
验证:执行命令 ifconfig
?
1.2修改主机名(主机名类似于域名(baidu.com))
<1>修改当前会话中的主机名,执行命令hostname hadoop
<2>修改配置文件中的主机名,执行命令vi /etc/sysconfig/network
验证:重启机器reboot -h now
命令vi三种模式 只读,不能写
????????????编辑,能读,也能写(敲击键盘a或i)
命令,需要执行命令(按Esc键,然后按Shift+:组合键,输入wq保存退出)
编辑文件强退时会产生(没保存时vi就自动保存成.a.swp)交换分区缓存文件(.a.swp) 查看隐藏文件使用命令ls -a
1.3把hostname和IP绑定
执行命令vi /etc/hosts,增加一行内容,如下
192.168.1.99 hadoop (虚拟机的IP地址)
保存退出。
验证:ping hadoop
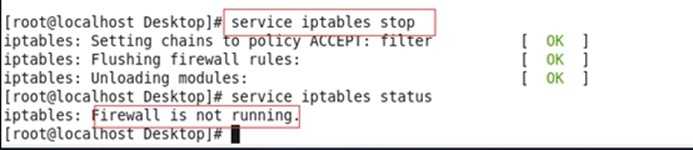
1.4关闭防火墙
执行命令 service iptables stop
验证:service iptables status
1.5关闭防火墙的自动运行(防火墙重启后可能会自动启动)
执行命令 chkconfig iptables off
验证:chkconfig --list | grep iptables(chkconfig是检查自动运行的配置项,--list是显示所有结果)
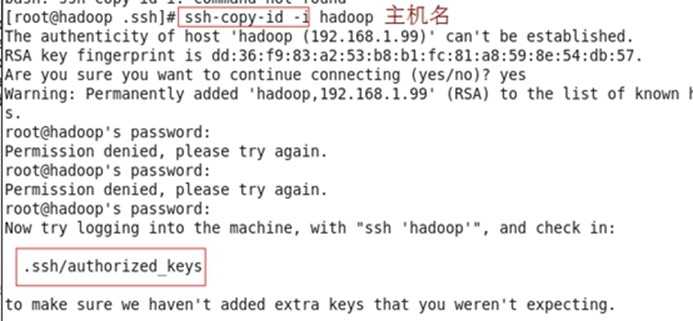
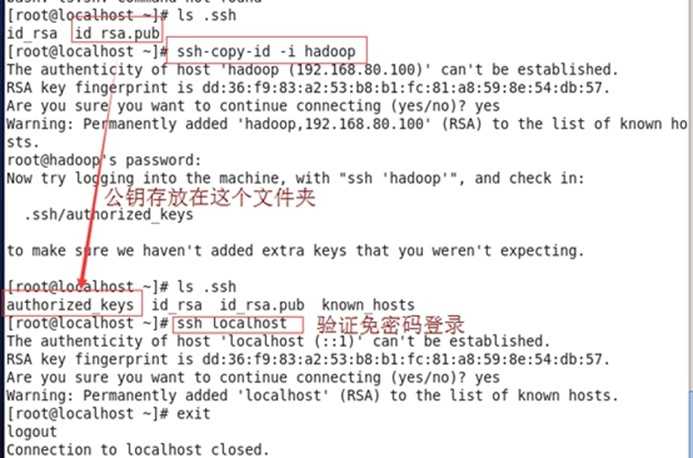
1.6 ssh免密码登录(类似与telnet命令,是明文传输包括密码,不安全。ls /root/.shh/查看(重启命令service shhd restart)A要免密码登录B,A、B的自身shh是可以运行,A将公钥文件复制给B中的authorized_keys文件,A向B发送登录请求,B向A发送随机的字符串,A用私钥加密字符串后的数据发回B,B自身将公钥加密之前的字符串,然后对比加密后的数据,如果比对匹配则可通信,反之不可通信)
<1>执行命令ssh-keygen -t rsa(-t指定加密类型,rsa是加密的算法一种)产生密钥,位于~/.shh文件夹中(id_rsa.pub是公钥文件id_rsa是私钥文件)
<2>执行命令(将自己的公钥文件拷贝到其他机器)ssh-copy-id -i hadoop ((不安全偷懒)或者将crxy2的密钥文件拷贝到hadoop在crxy2执行命令scp /root/.ssh/* crxy1:/root/.shh/) (cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys)
验证:ssh localhost
?
主节点->(公钥)子节点,子节点->(字符串)主节点,主节点->(密钥加密字符串)自己公钥加密字符串配对
公钥到了对方那里会放到authorized_keys文件夹中,ssh验证的时候会读取authorized_keys文件夹的内容
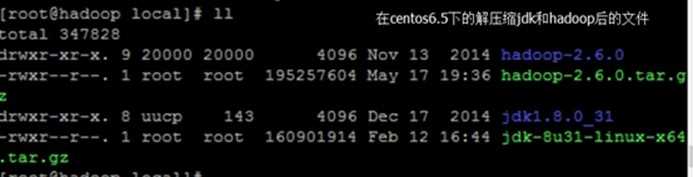
2.7安装jdk
<1>执行命令rm -rf/usr/local/*删除所有内容(r是递归删除,f是强制删除*是全部)
<2>使用winscp把jdk文件从windows复制到/usr/local目录下
<3>执行命令 chmod u+x jdk-8u31-linux-x64.tar.gz 赋予执行权限
<4>执行命令(当前目录/usr/local/) tar -zxvf jdk-8u31-linux-x64.tar.gz(./jdk-6u24-linux-i586.bin 解压缩)
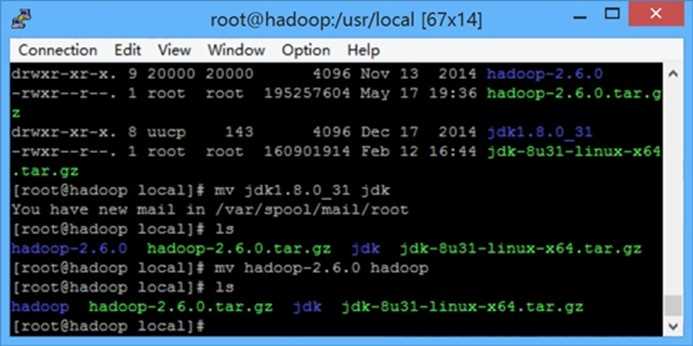
<5>执行命令 mv jdk-8u31 jdk 重命名
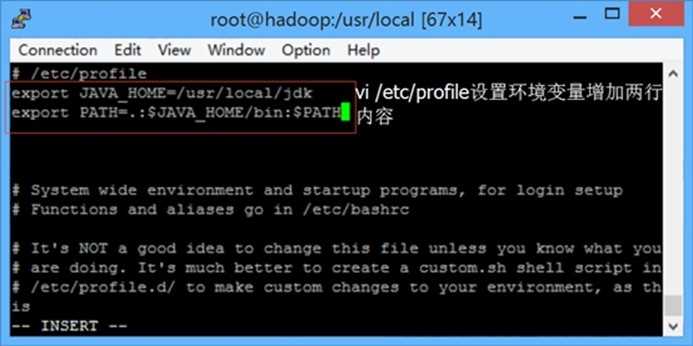
<6>执行命令 vi /etc/profile 设置环境变量,增加了2行内容
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
保存退出
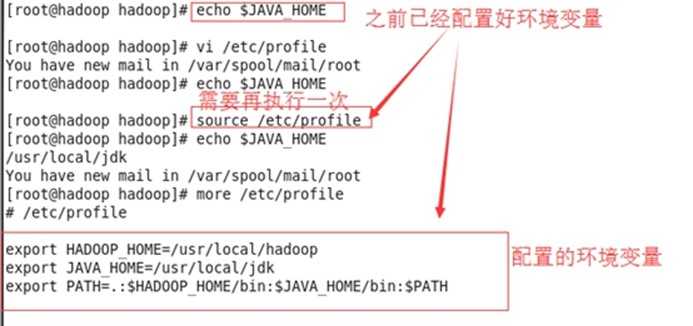
执行命令 source /etc/profile 让该设置立即生效
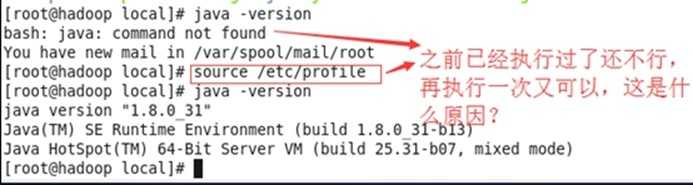
验证:java -version
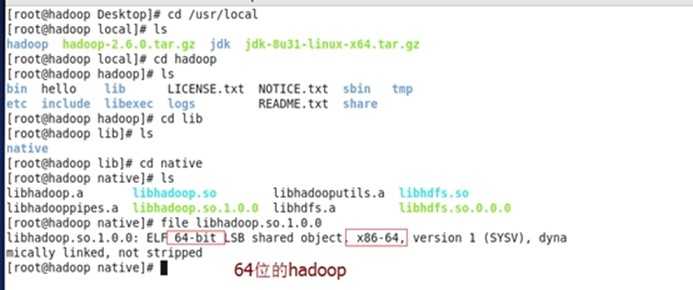
安装hadoop(注意是64位的,如果是32位需要编译)
<1>执行命令 tar -zxvf(z是压缩格式,x是解压,f是文件) hadoop-2.6.0.tar.gz进行解压缩
<2>执行命令 mv hadoop-2.6.0 hadoop 重命名
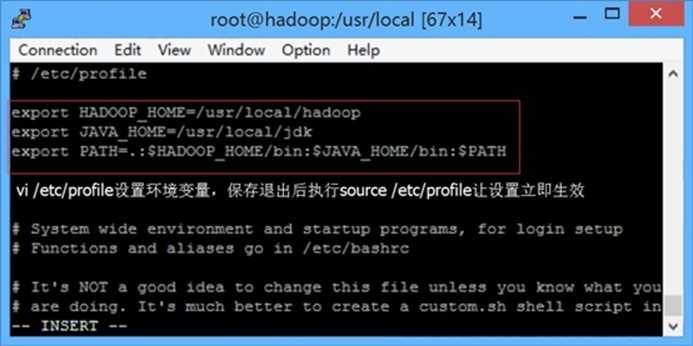
<3>执行命令 vi /etc/profile 设置环境变量,增加了1行内容
export HADOOP_HOME=/usr/local/hadoop
修改了1行内容
export PATH=.:$HADOOP_HOME:$JAVA_HOME/bin:$PATH
保存退出
执行命令 source /etc/profile 让该设置立即生效
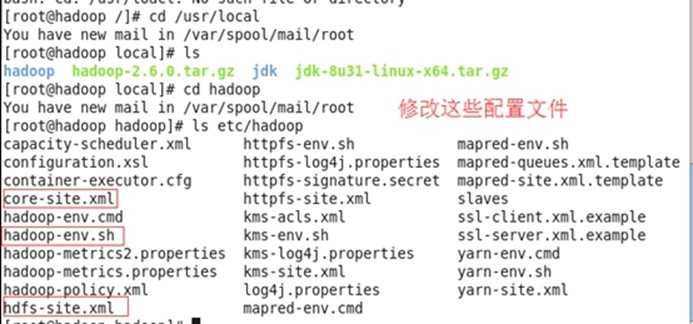
<4>修改hadoop的配置文件,位于$HADOOP_HOME/etc/hadoop 目录下的
修改3个配置文件,分别是hadoop-env.sh、core-site.xml、hdfs-site.xml
注意:查看hadoop版本:进入$hadoop_home/lib/native,执行file libhadoop.so.1.0.0(我们知道在64位机器上需要编译源码,可是为什么要编译源码,编译源码后,会有什么效果。
1.为什么需要编译Java文件?
你写出来的都是*.JAVA文件,JVM能执行的都是*.CLASS文件,所以需要编译
2.为什么要编译hadoop文件?
只有编译后的hadoop,才能被就jvm执行,才能被安装
3.hadoop是Java文件,Java文件不是一处编译,处处运行的吗?为什么还要编译?
处处运行是有前提条件的,就是有虚拟机执行,虚拟机分为两种32位,64位。
如果是32虚拟机编译的文件,只能运行于32虚拟机
如果是64虚拟机编译的文件,只能运行于64虚拟机)
?
?
?
关闭防火墙
?
?
参考一下

疑问:老师操设置完环境变量后并没有source /etc/profile就可以echo $JAVA_HOME,而我操作时却需要source /etc/profile才能echo $JAVA_HOME

?

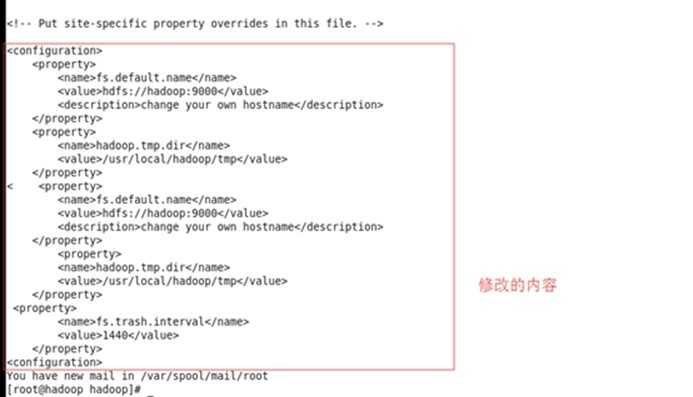
注意细节,最后是</configuration>,不然就会报错。
HDFS伪分布搭建
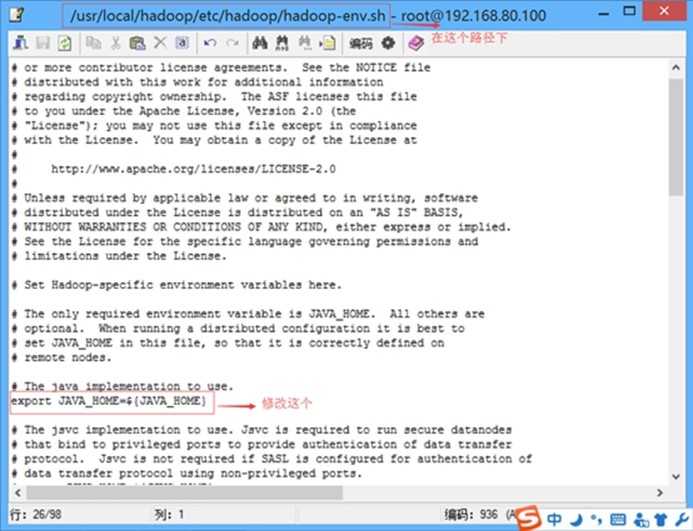
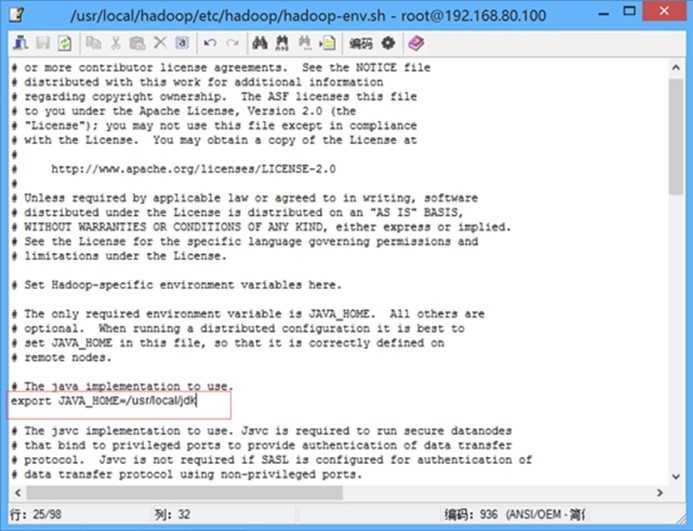
修改配置文件etc/hadoop/hadoop-env.sh
JAVA_HOME=/usr/local/jdk(安装jdk所在的路径)
修改配置文件etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
????<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
?
</configuration>
?
//备注:<value>/usr/local/hadoop/tmp</value>(备注hadoop运行时产生的数据文件所存在的目录,具有读写权限)
?
?
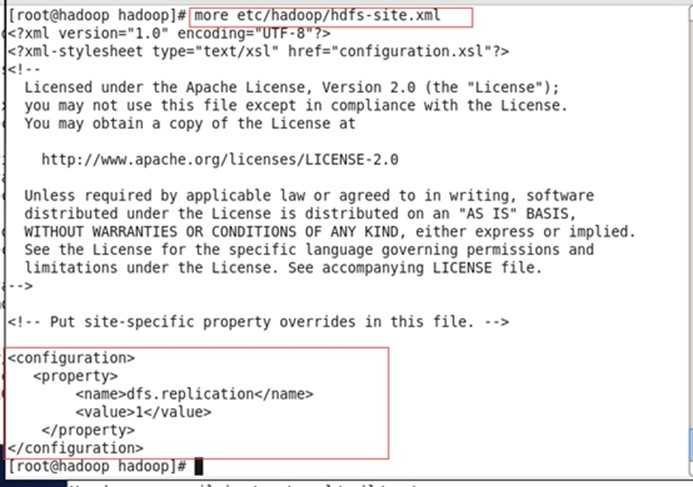
修改配置文件etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>(指的是副本数)
</property>
</configuration>
?
格式化文件系统
$ bin/hdfs namenode -format(格式化)
启动hdfs集群:

$ sbin/start-dfs.sh
访问web浏览器:
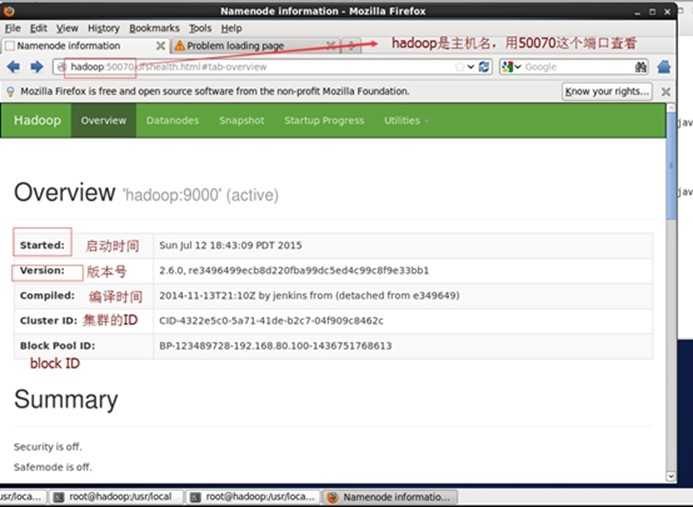
(NameNode ) http://localhost:50070/
练习:
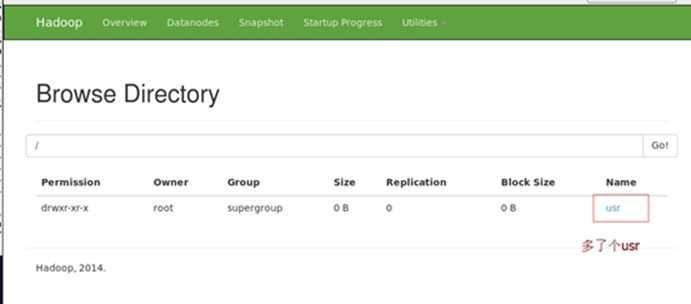
创建目录:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/root
复制文件:
$ bin/hdfs dfs -put /etc/profile input
关闭集群:
$ sbin/stop-dfs.sh
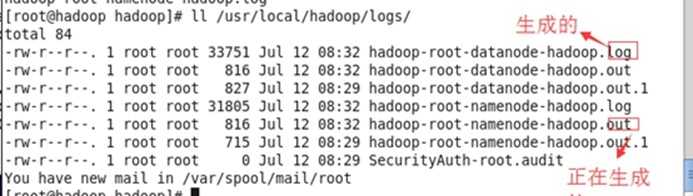
启动不成功查看日志文件
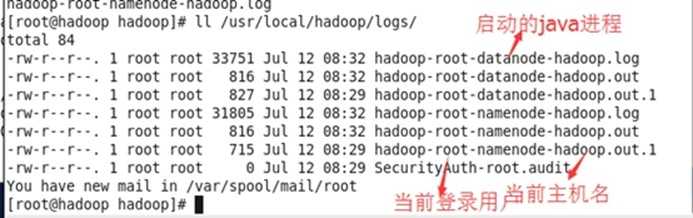
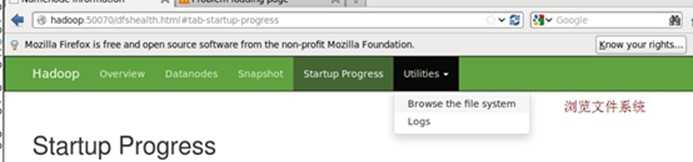
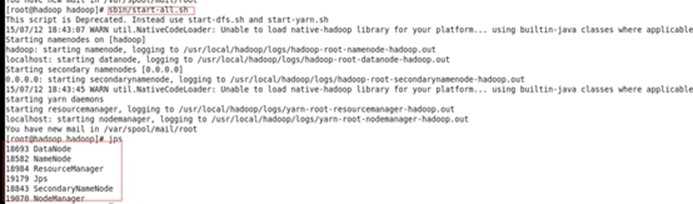
用浏览器查看hdfs(http://hadoop:50070/)(能查看就说明HDFS已启动成功啦!恭喜恭喜!)
?
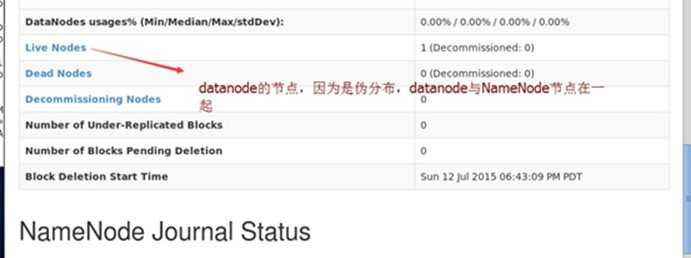
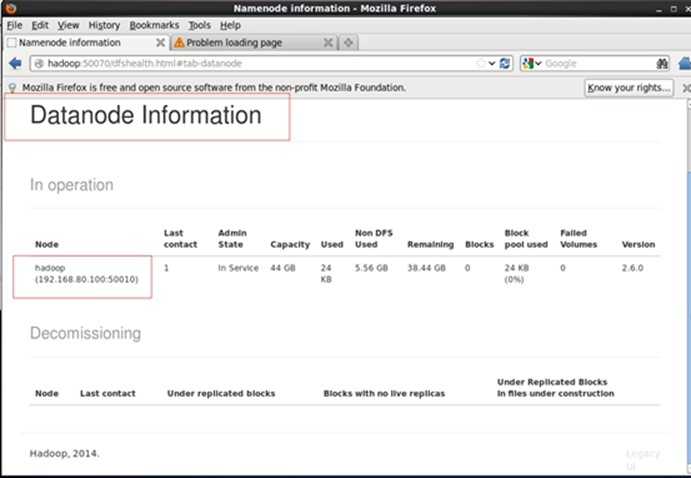
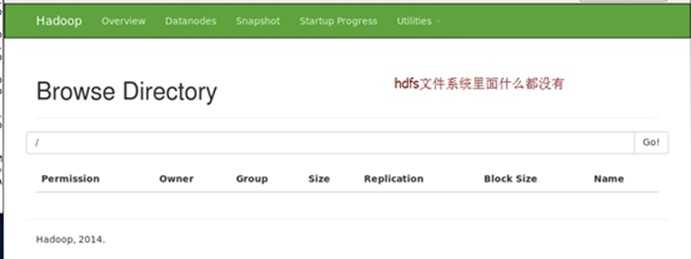
试验(验证hdfs是启动成功)



?
?
?
?
?
?
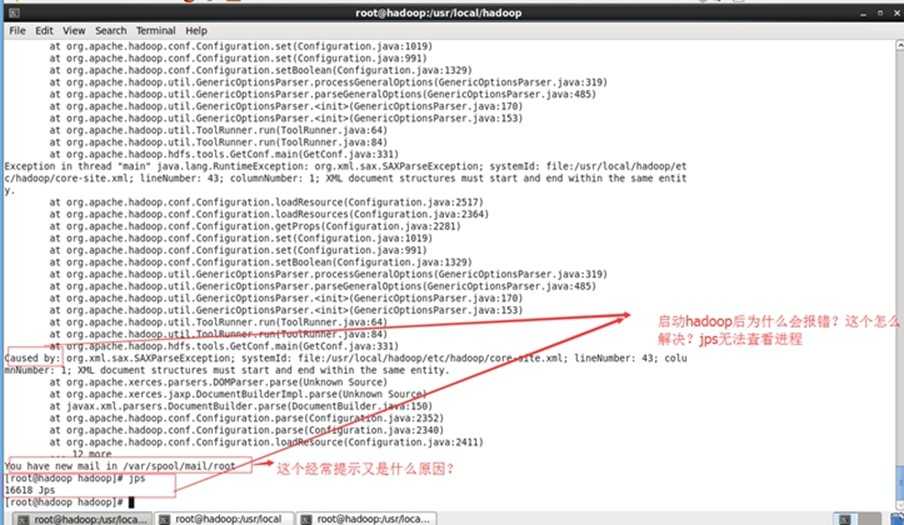
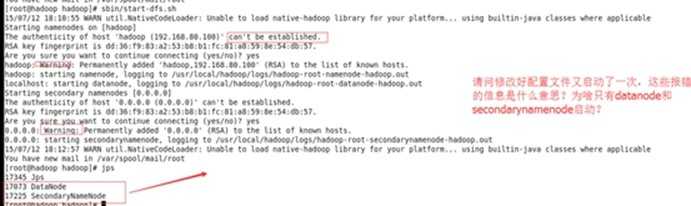
报错情况与解决办法:
?
配置文件修改错了!重新修改一次!
?


?
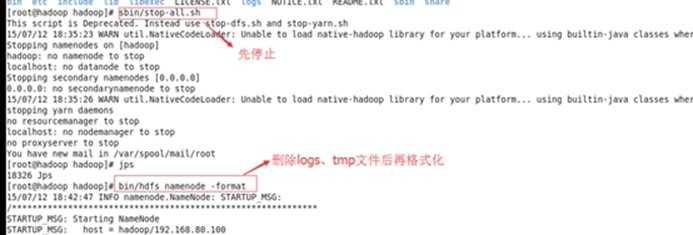
先停止hdfs(sbin/stop-all.sh),删除hadoop下的logs文件夹,然后再删除tmp文件夹,再格式化NameNode(bin/hdfs namenode -format),最后启动hdfs(sbin/start-all.sh)
?
?
标签:
原文地址:http://www.cnblogs.com/liuyifeng/p/4802868.html