标签:
教程地址:http://ufldl.stanford.edu/tutorial/supervised/SoftmaxRegression/
logstic regression是二分类的问题,如果想要多分类,就得用softmax regression。
理论部分参考这位博主的博文:http://www.cnblogs.com/tornadomeet/archive/2013/03/22/2975978.html
要注意logistic regression和softmax regression之间的不同,在不同场合用不同的方法。
实验部分看了好久,一直不明白,一是因为matlab不熟悉,还有一方面是变量的维数一直没搞明白。
这位博主给出了代码的详细解释,终于能看懂了:http://www.cnblogs.com/happylion/p/4225830.html
他的字体不容易看,我重新整理下,并加些注释。
我们首先展示下我们训练样本部分的图片和label:
1: images = loadMNISTImages(‘train-images.idx3-ubyte‘);%得到的images是一个784*60000的矩阵,意思是每一列是一幅28*28的图像展成了一列,
2: %一共有60000幅图像。
3: labels = loadMNISTLabels(‘train-labels.idx1-ubyte‘);
4: display_network(images(:,1:100)); % Show the first 100 images
5: disp(labels(1:10));
下面我们进行训练,首先我们定义一些softmax模型常量:
1: inputSize = 28 * 28; % Size of input vector (MNIST images are 28x28)
2: inputSize =inputSize +1;% softmx的输入还要加上一维(x0=1),也是θj向量的维度
3: numClasses = 10; % Number of classes (MNIST images fall into 10 classes)
4: lambda = 1e-4; % Weight decay parameter
导入训练样本数据
1: images = loadMNISTImages(‘train-images.idx3-ubyte‘);%得到的images是一个784*60000的矩阵,意思是每一列是一
2: %幅28*28的图像展成了一列,一共有60000幅图像。
3: labels = loadMNISTLabels(‘train-labels.idx1-ubyte‘);
4: labels(labels==0) = 10; % 因为这里类别是1,2..k,从0开始的,所以这里把labels中的0映射成10
5:
6: inputData = images;
7: inputData = [ones(1,60000); inputData];%每个样本都要增加一个x0=1
初始化模型参数:
1: theta = 0.005 * randn(inputSize*numClasses, 1);
接下来也是最重要的一步就是:给定模型参数的情况下,求训练样本的softmax的cost function和梯度,即
1: [cost, grad] = softmax_regression_vec(theta,inputData ,labels,lambda );
接下来我们就要写softmax_regression_vec函数:
1: function [f,g] = softmax_regression_vec(theta, X,y,lambda )
2: %下面的n和inputSize指数据有多少维(包括新加的x0=1这一维),也是θj向量的维度
3: %这里y是1,2....到k,从1开始的
4: m=size(X,2);%X每一列是一个样本,m是指有m个样本
5: n=size(X,1); %n指代的前面说了
6: theta=reshape(theta, n, []); %也就是把theta设置成这样矩阵:有inputSize行也就是n行,每一列是一个θj,有k列。这样的θ矩阵跟前面理论部分的θ矩阵不一样,存在
%转置关系,为什么这样呢?这样这样的话在后面的reshape和矩阵A(:)这样的操作,方便,都是按列进行的,还原也方便。所以只好程序中出现的θ矩阵都是这样的,k列,跟理论部分的相反。
7: % initialize objective value and gradient.
8: f = 0;
9: g = zeros(size(theta));
10: h = theta‘*X;%h是k行m列的矩阵,见图1.(之前一直不理解h矩阵是什么样的,看下图就明白了)
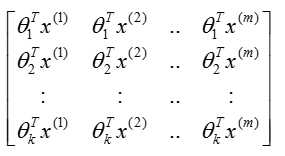
1: a = exp(h);
2: p = bsxfun(@rdivide,a,sum(a)); % sum(a)是一个行向量,每个元素是a矩阵的每一列的和。然后运用bsxfun(@rdivide,,)
3: %是a矩阵的第i列的每个元素除以 sum(a)向量的第i个元素。得到的p矩阵大小和图1一样,每个元素如图2.
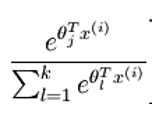
1: i = sub2ind(size(c), y‘,1:size(c,2)); %y‘,1:size(c,2)这两个向量必须同时是行向量或列向量
2: %因为我们接下来每一个样本xi对应的yi是几,就去找到p的每一列中,所对应的第几个元素就是要找的,如图4.首先使用sub2ind
3: %sub2ind: 在matlab中矩阵是按一列一列的存储的,比如A=[1 2 3;4 5 6]
4: %那么A(2)=4,A(3)=2...而这个函数作用就是比如 sub2ind(size(A),2,1)就是返回A的第2行第一列的元素存储的下标,因为
5: %A(2)=4,所以存储的下标是2,所以这里返回2.这里sub2ind(size(A),2,1)的2,1也可以换成向量[a1,a2..],[b1,b2..]但是注意
6: %这两个向量必须同时是行向量或列向量,而不能一个是行向量一个是列向量。所以返回的
7: %第一个元素是A的第a1行第b1列的元素存储的下标,返回的第,二个元素是A的第a2行第b2列的元素存储的下标...i是一个向量,c(i)得到的
8: %向量的每一个元素就是p中每一列你前面要找的的元素。
注:sub2ind(size(A),m,n)是得到A中m行n列这个元素的标号,具体参考:http://blog.csdn.net/djh512/article/details/6785975
在上面的代码中,得到的是y(i)=j的元素所对应的标号。
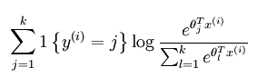
1: values = c(i);
2: f = -(1/m)*sum(values)+ lambda/2 * sum(theta(:) .^ 2); %这个就是cost function
最后求梯度:
1: d = full(sparse(1:m,y,1)); %d为一个稀疏矩阵,有m行k列(k是类别的个数),这个矩阵的(1,y(1))、(2,y(2))
2: %....(m,y(m))位置都是1。
3: g = (1/m)*X*(p‘-d)+ lambda * theta; %这个g和theta矩阵的结构一样。
4: g=g(:); % 再还原成向量的形式,这里(:)和reshape都是按列进行的,所以里面位置并没有改变。
注:sparse(i,j,s,m,n)构成一个稀疏矩阵,full则是把稀疏矩阵转为全矩阵。具体参考:http://blog.csdn.net/meng4411yu/article/details/8840612
下面这段话我没看明白:
我们想求梯度矩阵g,这里的g和θ=[θ1,θ2,…,θk]矩阵大小size一样(跟博客中的θ矩阵存在转置关系,之所有代码中这么做,是因为这样再把参数矩阵转成一个向量或转回去利用g(:)或reshape函数按列比较方面),
是n行k列的矩阵。n是θj或一个样本xi(包括截距1这一维)的维度大小,k是类别个数。m是样本个数。
我们想用矢量编程来求g矩阵:
我们有样本X(代码中每一列是一个样本,也即X为n行m列),那么g = (1/m).*X*(p‘-d)即是。比如,X的第 i 行乘以(p‘-d)的第 j 列就是X(i,j)的值。(正是这种行向量乘以列向量是对应元素相乘再相加就 完成了公式里的Σ,这也是矢量编程的核心)
ok,现在我们这个函数写完了,我们想验证下,我们写的这个求导数或着说梯度的这个公式正确不正确,我们还是用之前博客提到的用求导公式来验证,因为你求softmax模型某个参数的导数跟你输入的数据是什么、多少都没有关系,所以我们这有用一些简单的随意写得数据和label,然后随意取一个参数进行验证是不是正确,这些程序在前面已经有了,就不进行讲解了。
这段程序没跑过,有空跑跑看。
1: % DEBUG = true; % Set DEBUG to true when debugging.
2: DEBUG = false;
3: if DEBUG
4: inputSize = 9;
5: inputData = randn(8, 100);
7: inputData = [ones(1,100);inputData];
8: labels = randi(10, 100, 1);%从[1,100]中随机生成一个100*1的列向量
10: end
12: % Randomly initialise theta
13: theta = 0.005 * randn(inputSize*numClasses, 1);
1: [cost, grad] = softmax_regression_vec(theta,inputData ,labels,lambda );
2:
3: if DEBUG
4: numGrad = computeNumericalGradient( @(theta) softmax_regression_vec(theta,inputData ,labels,lambda) ,theta);
5:
6: % Use this to visually compare the gradients side by side
7: disp([numGrad grad]);
8:
9: % Compare numerically computed gradients with those computed analytically
10: diff = norm(numGrad-grad)/norm(numGrad+grad);
11: disp(diff);
12: % The difference should be small.
13: % In our implementation, these values are usually less than 1e-7.
14:
15: % When your gradients are correct, congratulations!
16: end
标签:
原文地址:http://www.cnblogs.com/573177885qq/p/4803264.html