标签:
前言:
哈希表(Hash Table)也叫散列表,是一种用于快速存取的数据结构。其内部实现是通过把键(key)码映射到表中的一个位置来访问记录,其中的“映射”也就是哈希函数,而“表”即哈希表。本文将重点介绍实现哈希表的2种方法:拉链法和线性探测法。
1.实验数据
A 2
C 1
B 6
B 11
H 1
J 3
数据说明:为了跟前面博文保持一致,本文的数据依然采用键值对(Key-Value)的形式。哈希表中主要有"存"和"取"操作。前者为:void put(Key key,Value);后者为: Value get(Key key);执行put操作时,如果数据已经存在则更新为新数据。
2.HashMap实现
实现哈希表主要分以下两步:
step1:定义哈希函数
哈希函数的实现不唯一,在此我们以java自带的hashCode()为基础进行修改。(对hashCode()底层实现感兴趣的朋友可另找资料进行了解~)
public int hash(Key key){ return (key.hashCode() & 0x7fffffff)%M; }
step2:解决哈希冲突
当出现 hash(k1)== hash(k2)时,即产生冲突。
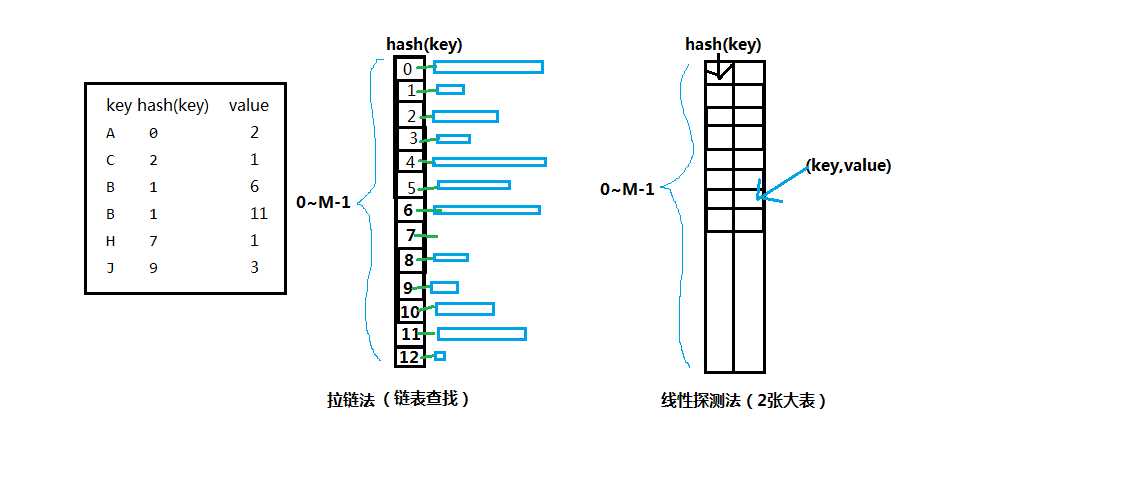
解决方法一(拉链法):因为哈希值相等,我们可以将k1,k2利用链表 st 进行存储。即,凡是hash(x)相等的x都存入同一链表。当要进行查找操作时,先利用hash(x)定位到链表st[hash(x)],再通过顺序链表遍历进行查找。
解决方法二(线性探测法):利用两张足够大的哈希表 keys[M]和Values[M](其中,M>=2*N),当出现冲突之后,顺势循环向下遍历查找还没有存放 key 的keys[hash(key)],直到找到keys[hash(key)]==null为止。
------------
拉链法与线性探测法的存储比较:
3.Java代码实现
a.拉链法code:
1 package com.gdufe.hash; 2 3 import java.io.File; 4 import java.util.Scanner; 5 6 public class SequenceChain<Key,Value>{ 7 8 private int N; 9 private int M; 10 private SequentialSearch<Key, Value> []st; 11 12 public SequenceChain() { 13 this(997); 14 } 15 String s; 16 public SequenceChain(int M){ 17 this.M = M; //赋值M 18 st = (SequentialSearch<Key,Value>[]) new SequentialSearch[M]; 19 for(int i=0;i<M;i++) 20 st[i] = new SequentialSearch(); //初始化 21 } 22 23 public int hash(Key key){ //自定义哈希,防止哈希值为负 24 return (key.hashCode() & 0x7fffffff) % M; 25 } 26 public void put(Key key,Value value){ 27 st[hash(key)].put(key, value); 28 } 29 public Value get(Key key){ 30 return st[hash(key)].get(key); 31 } 32 33 public static void main(String[] args) throws Exception{ 34 Scanner input = new Scanner(new File("data_hash.txt")); 35 SequenceChain<String, Integer> sequence = new SequenceChain<String, Integer>(); 36 while(input.hasNext()){ 37 String key = input.next(); 38 int value = input.nextInt(); 39 sequence.put(key, value); 40 } 41 input.close(); //关闭控制台输入 42 System.out.println("-----output----"); 43 System.out.println(sequence.get("H")); 44 System.out.println(sequence.get("B")); 45 46 } 47 48 }
辅助数据结构---顺序链表code:
1 package com.gdufe.hash; 2 3 import java.io.File; 4 import java.util.Scanner; 5 6 public class SequentialSearch<Key,Value> { 7 8 private Node root; //顺序链表的根root 9 class Node{ 10 Key key; 11 Value value; 12 Node next; 13 public Node(Key key,Value value){ 14 this.key=key; 15 this.value=value; 16 } 17 } 18 //在表头新增结点 19 public void put(Key key,Value value){ 20 if(get(key)!=null){ //更新即可 21 for(Node x=root;x!=null;x=x.next){ 22 if(x.key.equals(key)){ 23 x.value=value; 24 return; 25 } 26 } 27 } 28 Node h = new Node(key,value); 29 h.next=root; 30 root = h; 31 } 32 33 public Value get(Key key){ 34 for(Node x=root;x!=null;x=x.next){ 35 if(x.key.equals(key)){ 36 return x.value; 37 } 38 } 39 return null; 40 } 41 42 }
b.线性探测法code:
1 package com.gdufe.hash; 2 3 import java.io.File; 4 import java.util.Scanner; 5 6 public class LinearIndex<Key,Value> { 7 8 int N=0; 9 int M=16; //初始大小 10 Key[] keys; 11 Value[] values; 12 13 public LinearIndex() { 14 keys = (Key[]) new Object[M]; //强制转型 15 values = (Value[]) new Object[M]; 16 } 17 public void put(Key key,Value value){ 18 if(N*2>=M) resize(); //扩大哈希表 19 int i; 20 for(i=hash(key);keys[i]!=null;i=(i+1)%M){ 21 if(keys[i].equals(key)){ // 更新value 22 values[i]=value; 23 return; 24 } 25 } 26 keys[i]=key; 27 values[i]=value; 28 N++; 29 } 30 31 private void resize() { //扩大一倍 32 Key[] keyTemp = (Key[]) new Object[2*keys.length]; 33 System.arraycopy(keys, 0, keyTemp, 0, keys.length); 34 keys = keyTemp; 35 Value[] valueTemp = (Value[]) new Object[2*values.length]; 36 System.arraycopy(values, 0, valueTemp, 0, values.length); 37 values = valueTemp; 38 39 M = M*2; //shouldn‘t be neglected! 40 } 41 public Value get(Key key){ 42 for(int i=hash(key);keys[i]!=null;i=(i+1)%M){ 43 if(keys[i].equals(key)) 44 return values[i]; 45 } 46 return null; 47 } 48 public int hash(Key key){ 49 return (key.hashCode() & 0x7fffffff)%M; 50 } 51 52 public static void main(String[] args) throws Exception { 53 Scanner input = new Scanner(new File("data_BST.txt")); 54 LinearIndex<String, Integer> li = new LinearIndex<String, Integer>(); 55 while(input.hasNext()){ 56 String key = input.next(); 57 int value = input.nextInt(); 58 li.put(key, value); 59 } 60 input.close(); 61 System.out.println("-----output----"); 62 System.out.println(li.get("H")); 63 System.out.println(li.get("B")); 64 } 65 }
4.测试结果
-----output---- 1 11
注意:
(1)Java底层实现HashMap采用的是上述介绍的拉链法。关于HashMap的底层实现在Java面试中是面试官喜欢问的问题之一。
(2)关于拉链法采用的辅助结构为什么选择顺序链表而不采用高效的“二叉查找树“是因为,当哈希表较大而每张链表存储的数据不多时,顺序链表的效率反而更高一些。
结语:
同之前介绍的红黑树一样,哈希表也是一种高效的存储于查找的数据结构,特别适用于大数据的场合。至于在何时使用哈希表何时使用红黑树这个不一而论。因为,存储的效率还更数据本身相关。不过,由于哈希一向擅长处理跟字符串相关的存储,所以对于大量的字符串存储与查找可以优先考虑哈希表。
标签:
原文地址:http://www.cnblogs.com/SeaSky0606/p/4805012.html