标签:
机器学习从学习方式上来讲,可以分为两类:
监督学习(Supervised Learning),简而言之就是“有标签”学习
无监督学习(Unsupervised Learning),简而言之就是“无标签”学习
为了便于今后的机器学习,吴恩达先生(Andrew Ng)特别提出了一些notation(汉语译作“记法”,搞IT的最好渐渐熟悉这些基础单词)
use x(i) to denote "input" variable·········“feature”
use y(i) to denote "output" variable·······“target”
(x(i),y(i)) is called a training example·····“training example”
{(x(i),y(i));i=1,2,3,···,m} is called a “training set”
Note that the superscript "(i)" has nothing to do with exponatiation but simply an index into the training set.
请注意,(i)和指数没什么关系,仅仅是训练集的标号罢了。
所谓机器学习,其真正目的是训练一个函数h,使得任意x都有我们期待的y与之对应,如下图所示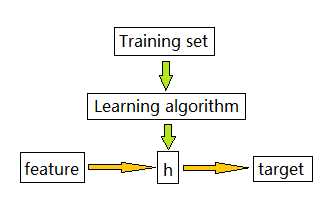
下面有两个重要的概念,分别是回归问题和分类问题,为了保证原意不失真,两个定义以英文格式给出:
When the target variable that we‘ll trying to predict is continuous,we call the learning problem a regression problem.
When y can take on only a small number of discrete values,we call it a classification problem.
当了解了以上基本概念后,我们正式进入机器学习课程,为了保证无论你是科研人员或者是工程技术人员,本博客都能对你起到作用,机器学习板块的任何一节课都会被分为两个部分:(1)理论推导部分(2)基于MATLAB的算法实践部分。并被分别予以阐述。如果你有志于立足科研,那么请您“知其所以然”去读理论推导部分。如果您急于进行工程设计,可以选择“快餐式”的读取算法实践部分。
下面开始正课。
标签:
原文地址:http://www.cnblogs.com/hdu-zsk/p/4805092.html