标签:
前篇介绍过Logstash的使用,本篇继续深入,介绍下最常用的input插件——file。
这个插件可以从指定的目录或者文件读取内容,输入到管道处理,也算是logstash的核心插件了,大多数的使用场景都会用到这个插件,因此这里详细讲述下各个参数的含义与使用。
在Logstash中可以在 input{} 里面添加file配置,默认的最小化配置如下:
input { file { path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*" } } filter { } output { stdout {} }
当然也可以监听多个目标文件:
input { file { path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"] } } filter { } output { stdout {} }
文件的路径名需要时绝对路径,并且支持globs写法。
另外,处理path这个必须的项外,file还提供了很多其他的属性:
input { file { #监听文件的路径 path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"] #排除不想监听的文件 exclude => "1.log" #添加自定义的字段 add_field => {"test"=>"test"} #增加标签 tags => "tag1" #设置新事件的标志 delimiter => "\n" #设置多长时间扫描目录,发现新文件 discover_interval => 15 #设置多长时间检测文件是否修改 stat_interval => 1 #监听文件的起始位置,默认是end start_position => beginning #监听文件读取信息记录的位置 sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt" #设置多长时间会写入读取的位置信息 sincedb_write_interval => 15 } } filter { } output { stdout {} }
其中值得注意的是:
1 path
是必须的选项,每一个file配置,都至少有一个path
2 exclude
是不想监听的文件,logstash会自动忽略该文件的监听。配置的规则与path类似,支持字符串或者数组,但是要求必须是绝对路径。
3 start_position
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
4 sincedb_path
这个选项配置了默认的读取文件信息记录在哪个文件中,默认是按照文件的inode等信息自动生成。其中记录了inode、主设备号、次设备号以及读取的位置。因此,如果一个文件仅仅是重命名,那么它的inode以及其他信息就不会改变,因此也不会重新读取文件的任何信息。类似的,如果复制了一个文件,就相当于创建了一个新的inode,如果监听的是一个目录,就会读取该文件的所有信息。
5 其他的关于扫描和检测的时间,按照默认的来就好了,如果频繁创建新的文件,想要快速监听,那么可以考虑缩短检测的时间。
6 add_field
就是增加一个字段,例如:
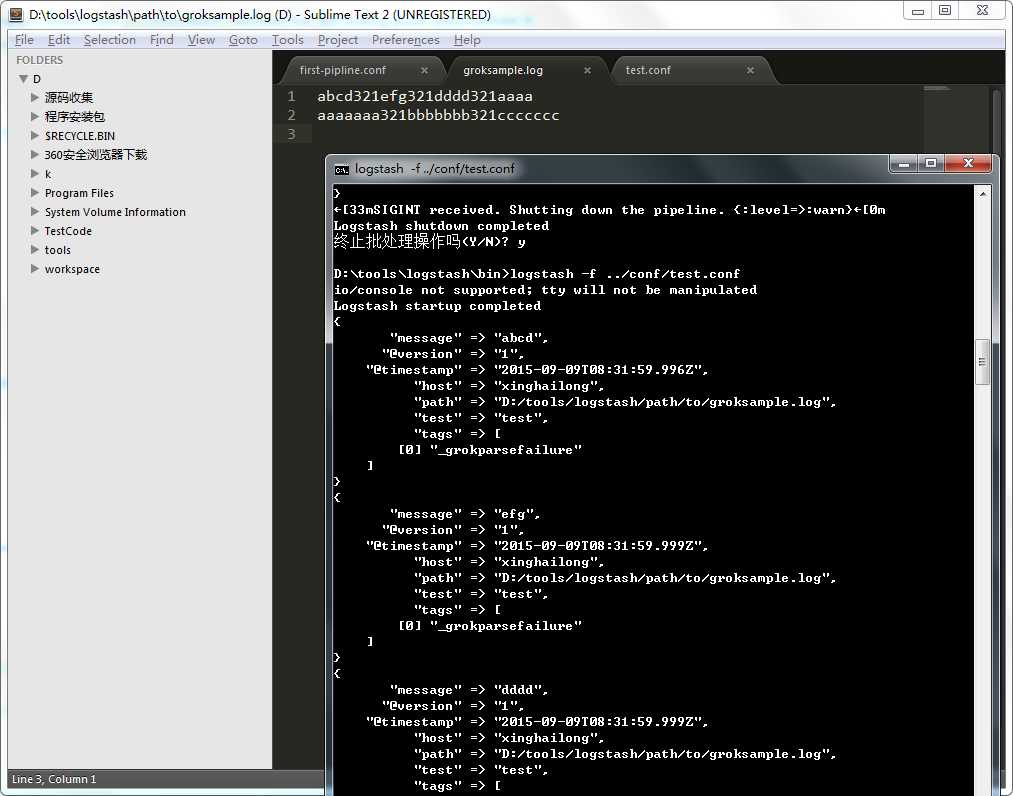
file { add_field => {"test"=>"test"} path => "D:/tools/logstash/path/to/groksample.log" start_position => beginning }
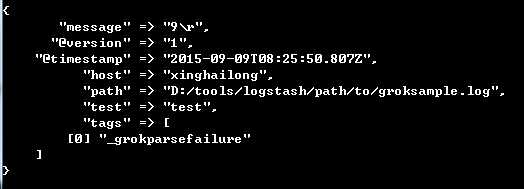
7 tags
用于增加一些标签,这个标签可能在后续的处理中起到标志的作用
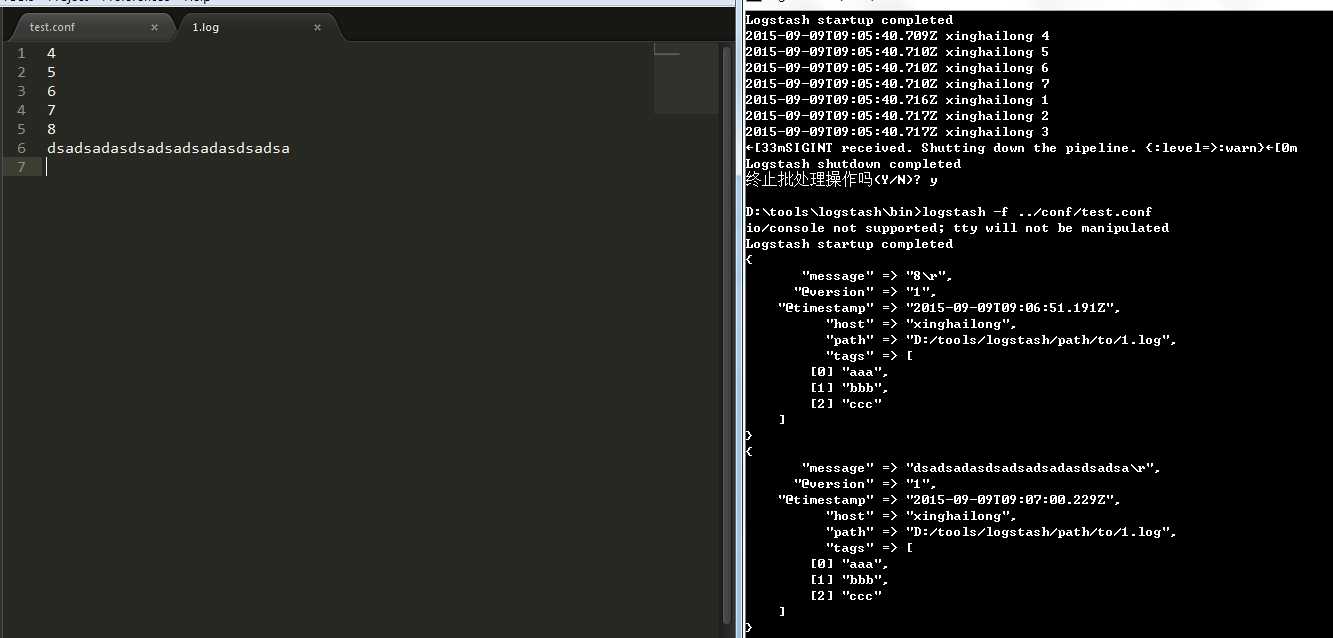
8 delimiter
是事件分行的标志,如果配置成123,那么就会如下所示。这个选项,通常在多行事件中比较有用。
暂时关于file就研究的这么多,后续会深入学习源码,做更多的分享。
【1】logstash官方文档:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-file.html#plugins-inputs-file-sincedb_path
标签:
原文地址:http://www.cnblogs.com/xing901022/p/4805586.html