标签:
最近开始接触和使用JMeter进行性能测试,也是因为工作需要,不得不学习更多新技能,在此之前一直使用LR进行WEB系统的压力测试,但是在ZK开发的WEB系统,我选择使用JMeter。
主要是因为ZK脚本安全性在代码中产生的随机值太多,LR关联起来太麻烦。JMeter就不同了, ZK官方针对这个问题,专门为JMeter工具写了测试插件,所有生成的随机码(dtid、uuid)都能自动关联上。既然官方已有插件的支持,为何要盯着代码在LR中做体力活呢(还不一定有效果至少目前在网上能搜到的成功案例寥寥无几),因此选择JMeter。
下面我将自己对JMeter的一些认识和使用做小结,以备学习之用,部分概念内容摘自于网络多个文档,只取其精华。
JMeter是Apache组织的开放源代码项目,100%的用java实现应用。用于压力测试和性能测量。它最初被设计用于Web应用测试但后来扩展到其它测试领域。
JMeterFAQ: http://wiki.apache.org/jmeter/JMeterFAQ
l 下载安装JDK
下载地址: http://www.oracle.com/technetwork/java/javase/downloads/index.html
l 下载解压JMeter压缩包
下载地址: http://jmeter.apache.org/download_jmeter.cgi
l 单机部署
下载JMeter源码包,解压之后即可使用,无需安装。 进入安装目录bin文件夹中点击“JMeter.bat”文件启动工具窗口。
l 多台机器分布式部署 (通常在模拟大批量用户一台机器资源不够用时使用分布式部署)
实现步骤如下:
1. 在所有机子上装上JMETER
2. 在Agent机子上运行bin目录下的JMeter-server.bat
3. 在Controller找到bin目录里的文件JMeter.properties,用记事本打开
4. 在文件中查找”remote_hosts=”,你会看到这样一行”remote_hosts=127.0.0.1”.其中的 127.0.0.1表示运行JMeter Agent的机器,这里需要修改为”remote_hosts=192.168.0.1:1099,192.168.0.2:1099,192.168.0.3:1099”——其中1099为 JMeter的Controller和Agent之间进行通讯的默认RMI端口号,不写也行,总之默认会用1099;
5.
保存文件,并重新启动Controller机器上的JMeter.bat,在菜单Run下的Remote Start菜单项,你将可以看到所有能连接的Agent。
? JMeter支持的协议
? Web(HTTP/ HTTPS),SOAP,FTP,Database(JDBC), LDAP, JMS, Mail(POP3/IMAP),JAVA
? JMeter支持的协议相对Loadrunner较少,但是可以通过二次开发来实现
? Loadrunner支持的协议
? WEB(Http/Html)、FTP、LDAP、Palm、Web/WinsocketDual Protocol
? SQL Server、 MS ODBC、 Oracle、 DB2、 Sybase CTlib、 Sybase DBlib、 Domain Name Resolution(DNS)、Windows Socket
? COM/DCOM、Corba-Java、Rmi_Java EJB、Rmi_Java
? Oracle
NCA、SAP-Web、SAPGUI、SAPGUI/SAP-Web Dual Protocol、 PropleSoft_Tuxedo、Siebel Web、Siebel-DB2 CLI、Sieble-MSSQL、Sieble Oracle
? ……
功能对比:
|
对比项 |
JMeter |
Loadrunner |
|
支持的协议 |
少 |
多 |
|
结果报表 |
少 |
丰富 |
|
测试场景 |
灵活 |
灵活 |
|
运行环境 |
Windows/Unix/Linux
|
Windows/Linux(部分支持) |
|
IP欺骗功能 |
无 |
有 |
使用对比:
|
对比项 |
JMeter |
Loadrunner |
|
安装 |
简单 |
复杂 |
|
脚本录制 |
很好 |
较好 |
|
脚本语言 |
C,JAVA,VB |
XML |
|
编辑方式 |
图形界面/脚本 |
图形界面修改 |
|
成本 |
免费 |
昂贵 |
|
学习资料 |
较少(逐渐丰富) |
很多 |
Jmeter工具和LR性能工具在原理上完全一致,包含4个部分:
(1)负载发生器:用于产生负载,通常以多线程或是多进程的方式模拟用户行为。
(2)用户运行器:通常是一个脚本运行引擎,用户运行器附加在线程或进程上,根据脚本要求模拟指定的用户行为。
(3)资源生成器:用于生成测试过程中服务器、负载机的资源数据。
(4)报表生成器:根据测试中获得的数据生成报表,提供可视化的数据显示方式
用来描述一个性能测试,包含与本次性能测试所有相关的功能。也就说本的性能测试的所有内容是于基于一个计划的。
下面看一下一个计划下面都有哪些主要的功能模块(右键单击“测试计划”弹出菜单)。
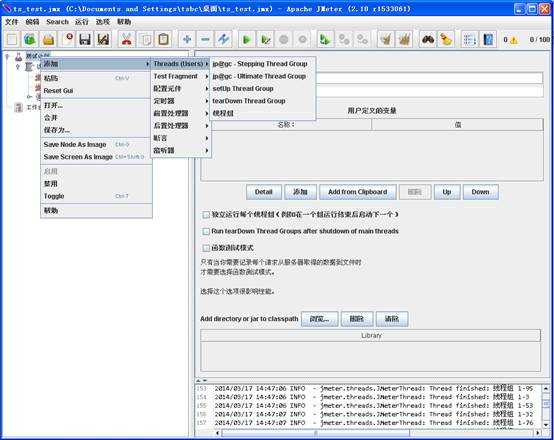

默认有三个添加线程组的选项,名字不一样, 创建之后,其界面是完全一样的。之前的版本只有一个线程组的名字。现在多一个setUp theread Group 与terDown Thread Group
1) setup thread group
一种特殊类型的ThreadGroup的,可用于执行预测试操作。这些线程的行为完全像一个正常的线程组元件。不同的是,这些类型的线程执行测试前进行定期线程组的执行。
2) teardown thread group.
一种特殊类型的ThreadGroup的,可用于执行测试后动作。这些线程的行为完全像一个正常的线程组元件。不同的是,这些类型的线程执行测试结束后执行定期的线程组。
可能你还是不太理他们与普通的线程组有什么不同。 如 果您用过junit,想必你不会对setup ,teardown这2个字眼陌生。 即使没用过,也没关系。 熟悉loadrunner的应该知道,loadrunner的脚本除了action里是真正的脚本核心内容,还有初始化“环境”的初始化脚本和测试完毕后对应的清除信息的脚本块。
那么这里 setup thread group 和 teardown thread group 就是分别指这两部分。 其实从本质上来看,他们并没有什 么不同。
3) thread group(线程组).
这个就是我们通常添加运行的线程。通俗的讲一个线程组,,可以看做一个虚拟用户组,线程组中的每个线程都可以理解为一个虚拟用户。线程组中包含的线程数量在测试执行过程中是不会发生改变的。

测试片段元素是控制器上的一个种特殊的线程组,它在测试树上与线程组处于一个层级。它与线程组有所不同,因为它不被执行,除非它是一个模块控制器或者是被控制器所引用时才会被执行。
控制器
JMeter有两种类型的控制器:取样器(sample)和逻辑控制器(Logic Controller),用这些元件来驱动处理一个测试。
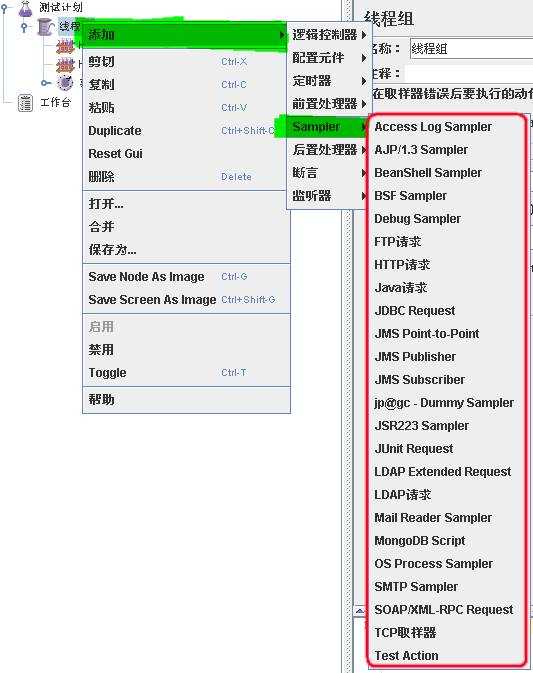
取样器(Sample)是性能测试中向服务器发送 请求,记录响应信息,记录响应时间的最小单元,JMeter 原生支持多种不同的sampler , 如 HTTP Request Sampler 、 FTP Request Sample 、TCP Request Sample 、 JDBC Request Sampler 等,每一种不同类型的 sampler 可以根据设置的参数向服务器发出不同类型的请求。(在 jmeter 的所有sampler 中,Java Request Sampler 和 Beanshell Request Sampler 是两种 特殊的可定制的 Sampler ,后面会深入讨论。)
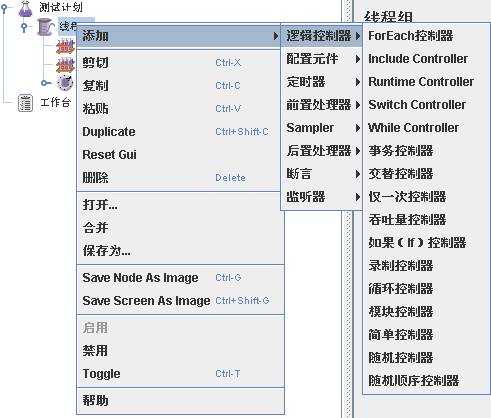
逻辑控制器,包括两类无件,一类是用于控制 test plan 中 sampler 节点发送请求的逻辑顺序的控制器,常用的有 如果(If)控制器 、switch Controller 、 Runtime Controller、循环控制器等。另一类是用来组织可控制 sampler 来节点的,如 事务控制器、吞吐量控制器。
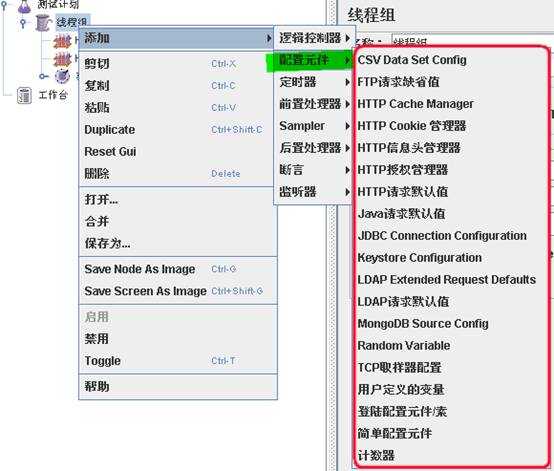
配置元件(config element)用于提供对 静态数据配置的支持。CSV Data Set config 可以将本地数据文件形成数据池(Data Pool),而对应于 HTTP Request Sampler和 TCP Request Sampler等类型的配制无件则可以修改Sampler的默认数据。(例 如,HTTP Cookie Manager 可以用于对 HTTP Request Sampler 的cookie 进行管理)
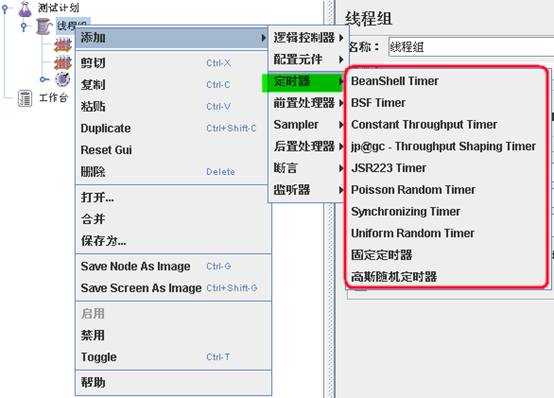
定时器(Timer)用于操作之间设置等待时间,等 待时间是性能测试中常用的控制客户端QPS的手端。类似于LoadRunner里面的“思考时间”。JMeter 定义了 Bean Shell Timer、Constant Throughput Timer、固定定时器等不同类型的Timer。
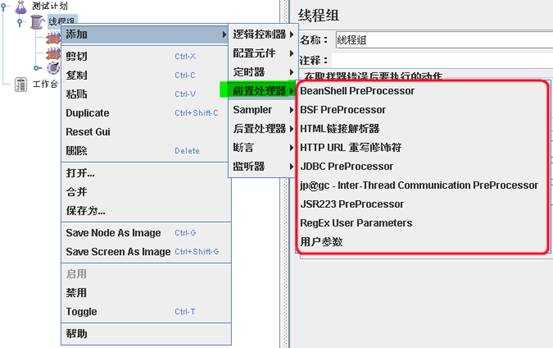
用于在实际的请求发出之前对即将发出的请求进行特殊处理。例如,HTTP URL重写修复符则可以实现URL重写,当RUL中有sessionID 一类的session信息时,可以通过该处理器填充发出请求的实际的sessionID 。
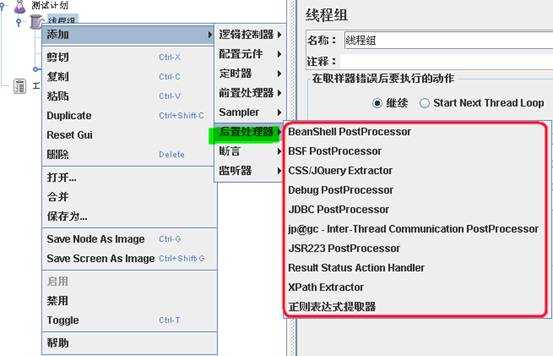
用于对Sampler 发出请求后得到的服务器响应进行处理。一般用来提取响应中的特定数据(类似LoadRunner测试工具中的关联概念)。例如,XPath Extractor 则可以用于提取响应数据中通过给定XPath 值获得的数据。
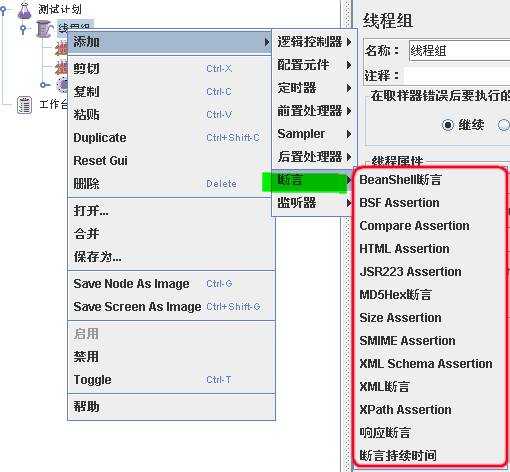
断言用于检查测试中得到的相应数据等是否符合预期,断言一般用来设置检查点,用以保证性能测试过程中的数据交互是否与预期一致,类似于LR中的检查点。
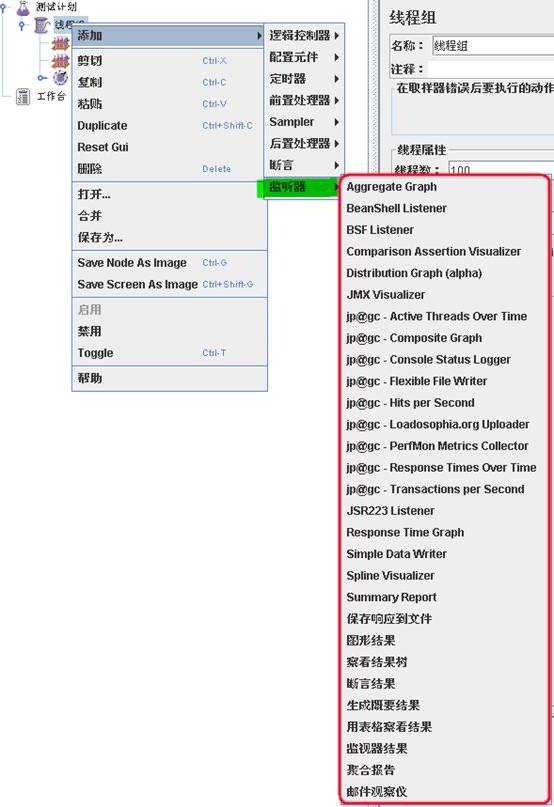
这个监听器可不是用来监听系统资源的元件。它是用来对测试结果数据进行处理和可视化展示的一系列元件。 图行结果、查看结果树、聚合报告。都是我们经常用到的元件。
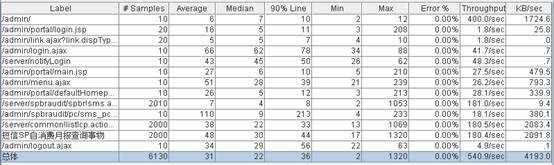
聚合报告:
Label:这里对应一个HTTP Request ,显示的就是 Name 属性的值;
#Samples: 表示你这次测试中一共发出了多少个请求;
Average: 平均响应时间 , 默认情况下是单个 Request 的平均响应时间,当使用了 “事务控制器”时,以事务为单位为单位显示平均响应时间
Median: 中位数,也就是 50 %用户的响应时间
90% Line: 90 %用户的响应时间
Min: 最小响应时间
Max:最大响应时间
Error%: 本次测试中出现错误的请求的数量 / 请求的总数
Throughput: 吞吐量 ,默认情况下表示每秒完成的请求数。
KB/Sec: 每秒从服务器端接收到的数据量
使用Badboy工具进行录制,导出JVM格式,使用jmeter打开,适合纯JSP站点。我一开始选择用这个进行录制,觉得简单即录即用,但是后来发现,对于ZK平台,使用它录制那么ZK的自动关联插件就完全没作用了(所有优缺点一下子体现出来了),后来还是使用HTTP代理录制。
优点:不用手动创建元件,不用设置代理,即录即用
缺点:不支持插件自动关联。
下载地址:http://www.badboy.com.au/
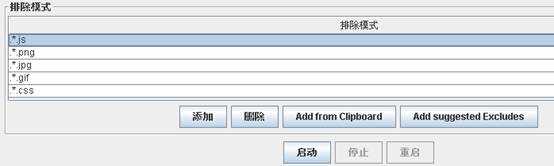
1. 在工作台可以使用排除模式提前优化录制脚本,将录制过程中请求的图片、样式、js等连接给排除出去。如下图要排除录制中请求js ,png,gif,jpg,css等链接。使用 .*.[后缀名]的格式进行排除。
2.或者也可以使用包含模式,将录制过程中需要保留的请求给保留下来。添加方法也可以使用后缀方法进行区分,原理同1.
? 通常录制脚本中会提交一些参数,使用不同的参数值来模拟才更接近实际情况(如不同的登录用户名、密码等)。
? 参数定义后, 使用${paramName}既可以使用

下面主要介绍介绍下文件参数化和函数参数化。
1. 新建用户名、密码存放文件 (E:\UserPass.csv)如下:
admin,admin
test1,111111
test2,111111
test3,111111
说明:这里用英文逗号为分隔符,也可以用其他为分隔符,在CSV Data Set Config中可以设置。
2.
右键点击Jmeter中需要参数化的某个请求,选择添加——配置原件——CSV Data Set Config,会添加一个CSV Data Set Config,需要设置相关的一些内容,具体如下:
Filename --- 参数项文件,填写文件路径和名称(默认路径读取脚本文件jmx同级目录)
File Encoding --- 文件的编码,一般为空
Vaiable Names --- 文件中各列所表示的参数项;各参数项之间利用逗号分隔;参数项的名称应该与HTTP Request中的参数项一致。
Delimiter --- 如文件中使用的是逗号分隔,则填写逗号;如使用的是TAB,则填写\t;
Recycle on EOF? --- True=当读取文件到结尾时,再重头读取文件
False=当读取文件到结尾时,停止读取文件
Stop thread on EOF? --- 当Recycle on EOF?一项为False时起效;True=当读取文件到结尾时,停止进程
Share mode --- 参数共享模式,ALL threads 所有线程可用
如下图参数配置: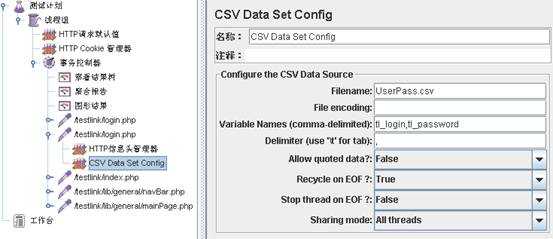
引用参数:
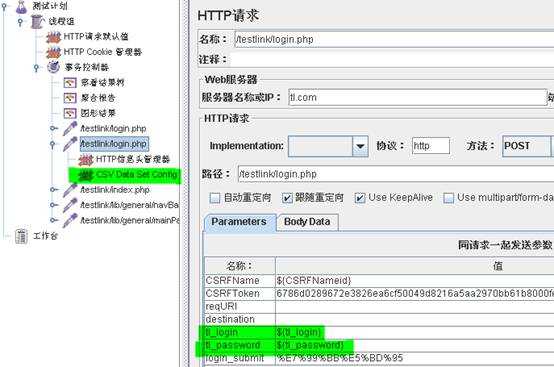
1. 新建用户名、密码存放文件 (E:\UserPass.csv)如下:
admin,admin
test1,111111
test2,111111
test3,111111
2. 构建函数,点击JMeter的“选项”——“函数助手对话框”打开函数助手,选择_CSVRead功能
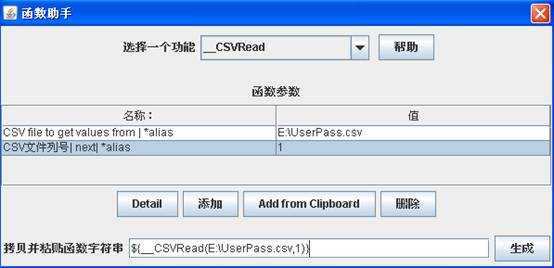
第一行值输入文件的路径
第二行值输入要参数化变量在文件中的列数(从0开始)
完成后,点击“生成”按钮,生成函数字符串,拷贝字符串到要参数化变量的位置。
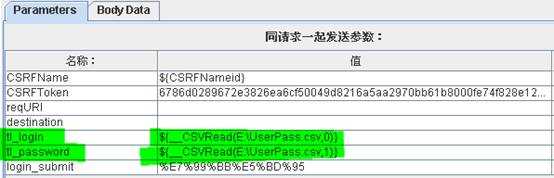
_Random
打开“函数助手”对话框,在“选择一个功能”的下拉框中选择“_Random”,然后在“函数参数”中会出现三个参数让用户来设置。
第一个参数是“一个范围内的最小值”,即所要取的随机数的最小值,我们设置成1
第二个参数是“一个范围内的最大值”,即所要取的随机数的最大值,我们设置成100
第三个参数是“函数名称”,即用于存储在测试计划中其他的方式使用的值,我们设置成Random。
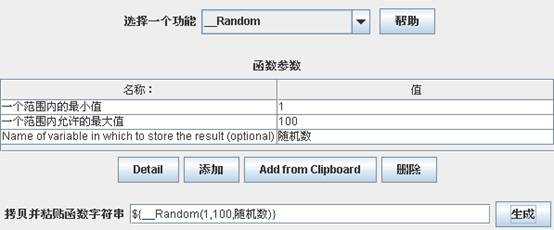
设置好上面的三个参数后,点击“生成”按钮,这样就会在对话框的最下面生成一个字符串“${__Random(1,100,随机数)}”,然后我们找到要替换的参数,把它的值换成前面生成的字符串就可以了,然后每次运行的时候,这个参数会变成一个1到100之间的随机数。
_threadNum
它用于得到当前运行的线程编号,获取值的方式:${__threadNum}这个函数没有任何参数,
_StringFromFile
这个函数是从文件中读取字符串,一次读取一行。有一下四个参数值。
第一个参数:文件的完整路径,即文件路径+文件名.扩展名
第二个参数:函数名称
第三和第四个参数的用途有两个,如果一起使用可以从多个文件中读取字符串。如果只 使用第四个参数则表示对同一个文件读取多次。
例如:${__StringFromFile(E:\User.dat,,1,2)}可以读取User1.dat和 User2.dat,从User1.dat的第一行记录开始读取,User1的记录读取完成后,自 动从User2.dat的第一行继续读取。
${_StringFromFile(E:\User.dat,,,2)} 读取User.dat两次
如用户名文件
User.dat
admin
test1
test2
test3
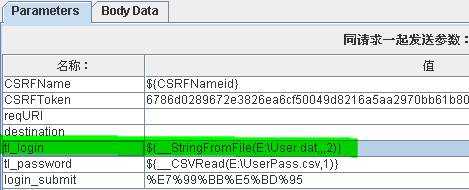
上图,所示可以读取两次User.dat文件中内容。
_javaScript
这个函数是很好用的函数,通过它能使用JavaScript所支持的所有函数,比如当前的系统日期,系统时间等,它的参数也有两个,第一个是“JavaScript expression to evaluate”,这个参数是JavaScript的语句表达式,我们可以输入任何的JavaScript支持语句,调用JavaScript自带的函数。
可以通过JS来判断脚本执行状态,读取文件,操作文件等功能。(更多用法需要摸索)
参数关联,与LR中的关联功能作用基本相同,关联脚本中的一些动态参数,使的脚本可以正确运行。
从前一个请求中取,用正则表达式提取器。
具体方法,在需要获得数据的请求上右击添加一个“后置处理器”-->“正则表达式提取器”
引用名称即下一个请求要引用的参数名称,如填写ticketid,则可用${ticketid}引用它。
正则表达式中()括起来的部分就是要提取的。.代表任意字符,*代表出现任意次。
模板,用$$引用起来,如果在正则表达式中有多个正则表达式(多个括号括起来的内容),则可以是$2$,$3$等等,表示解析到的第几个值给ticketid。
匹配数字,0代表随机,-1代表所有,其余正整数代表将在检查的内容中,第几个匹配的内容提取出来。
例如:
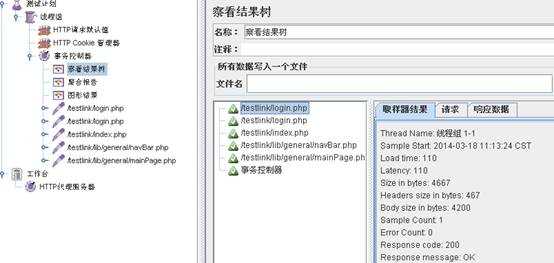
下面图登录脚本中用户需要使用ticket认证,ticket为随机生成的动态变量
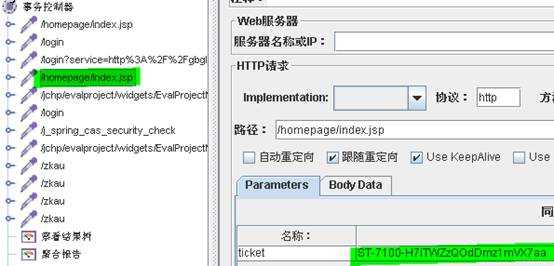
要对ticket进行关联,对它的前一个请求,添加“后置处理器”-->“正则表达式提取器”如:
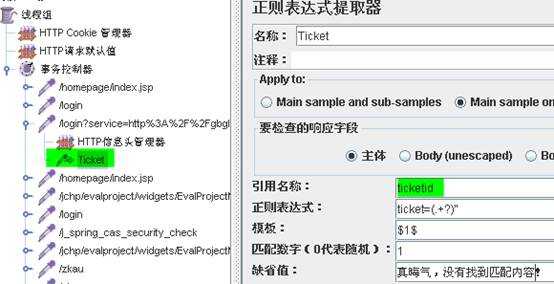
正则表达如何去匹配,此处跟LR的原理几乎相同,括号中的内容是要关联的内容,括号左右两边内容为参数在响应数据源码中的匹配内容。
如:ticket=(.+?)"
括号左边:ticket=
括号右边:”
括号中(.+?):表示任意内容
运行一次脚本,通过结果树查看响应数据中ticket内容:
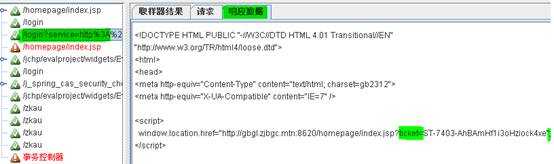
这种形式比较适合于返回为xml、HTML片段的情况。
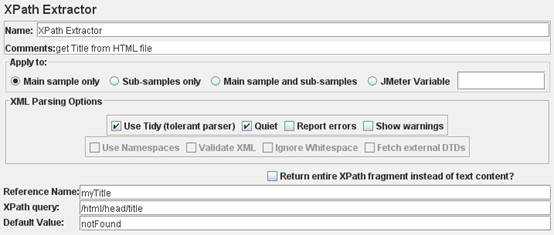
在需要获得数据的请求上右击添加一个“后置处理器”-->“xPath
Extractor”。
如下图所示,获取获取当前请求HTML中的title。(这个只是个简单的例子,更高级的功能,需要介绍可看Jmeter的用户手册)
http://jmeter.apache.org/usermanual/component_reference.html#XPath_Extractor
断言就类似LoadRunner中的检查点。对上一个请求返回的信息,做字符串、数据包大小、HTML、XML、图片等做判断,确保返回的信息的准确性。
添加断言
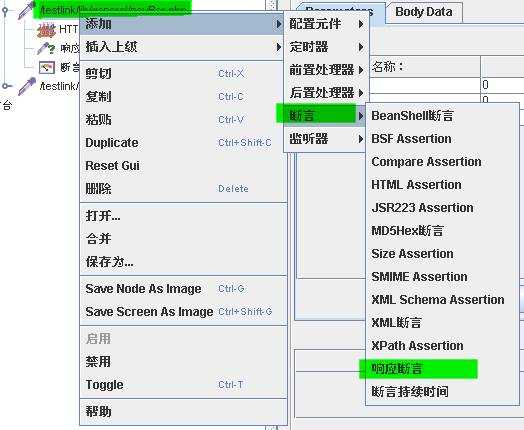
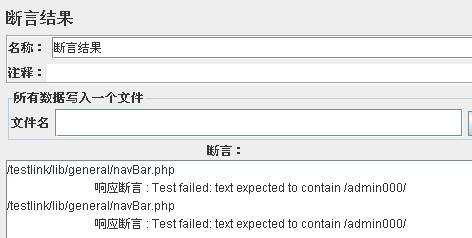
添加响应断言:${tl_login} 登录后页面显示的用户名是否存在。这里使用参数化,动态判断,直接写固定文本也是可以的。
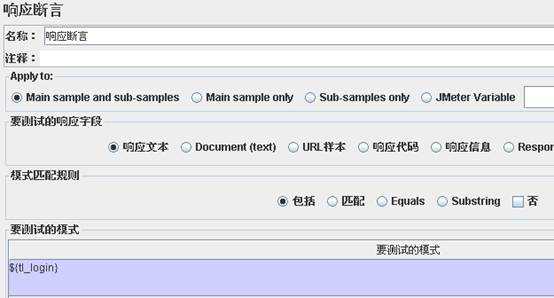
响应代码中位置:
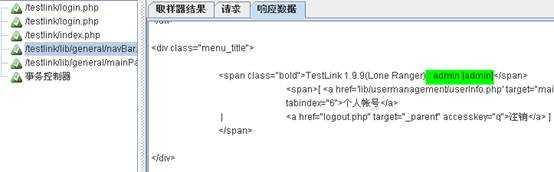
添加断言结果:右键单击请求,添加——“监听器”——“断言结果”,运行脚本:
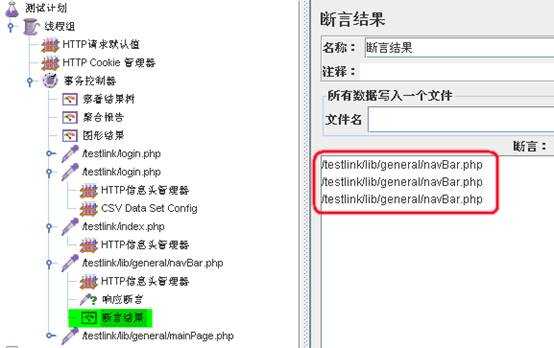
运行结束后,找到文本,则返回文本所在文件路径。如未匹配到文本则结果树显示红色。断言返回如下:
? JMeter的逻辑控制器提供了一系列的组件,可以实现多样化的场景控制。
? 常用的逻辑控制器有:循环控制器,事务控制器
模拟用户并发运行场景主要通过线程组属性进行设置:
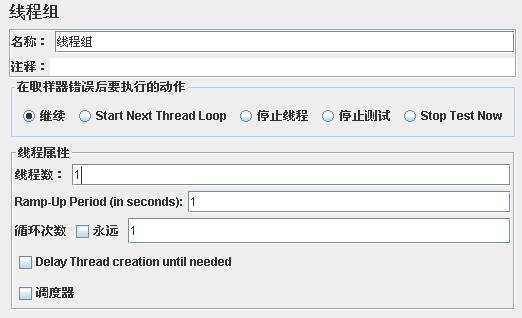
线程数:可看做模拟用户数量
Ramp-Up Period:告诉JMeter 达到最大线程数需要多长时间。假定共有10 个线程,Ramp-Up Period 为100 秒,那么JMeter 就会在100 秒内启动所有10 个线程,并让它们运转起来。如果有30 个线程和一个120秒的ramp-up period,那么每个连续的线程会延迟4秒。
循环次数:设置执行测试的次数
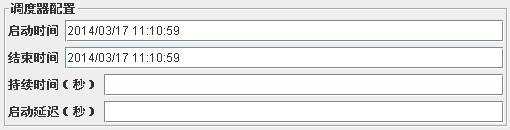
调度器:在里面你可以输入启动和结束时间。当测试启动时,如果必须JMeter会等待启动时间到达。在每个周期 结束,JMeter检验结束时间是否到达,如果是,运行停止,如果不是测试被允许继续,直到迭代限制到达。
用过LoadRunner的人都知道,LoadRunner本身提供了很多函数可以对收集回来的结果进行一些初步的分析。例如可以做到判断返回的结果是否正确;判断request的response time是否大于x秒之类的。相比起LoadRunner,Jmeter在这方面没有那么强大,但是个人认为,对于一些编程基础不是太好的测试人员来说,Jmeter比LoadRunner易用性上面做得更出色。
用过LoadRunner的人应该都知道,LoadRunner会为我们提供一大堆图标和曲线。但是在Jmeter里,我们只能找到几个可怜的Listener来方便我们查看测试结果。但是,对于初学者来说,一些简单的结果分析工具可以使我们更容易理解性能测试结果的分析原理。所以,千万别小看这几个简单的Listener啊。

通过这份报告我们就可以得到通常意义上性能测试所最关心的几个结果了。
Label:每个
JMeter 的
element(例如 HTTP
Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个
Request 的平均响应时间,当使用了
Transaction Controller 时,也可以以Transaction
为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
Note:关于 90% 并发用户数的含义,通过查看官方啰嗦的解释
我觉得可以简单总结为:
有90%用户没有超过显示的响应时间。
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request
per Second),当使用了
Transaction Controller 时,也可以表示类似
LoadRunner 的
Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
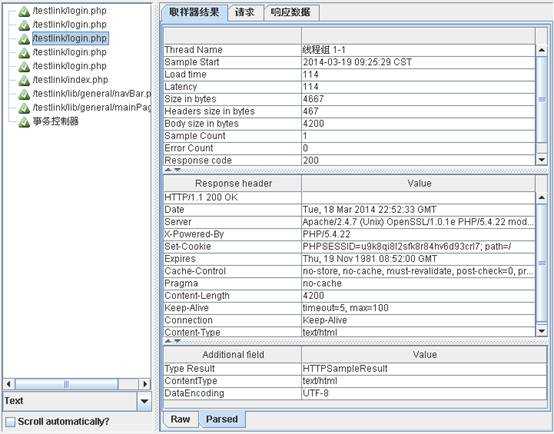
通过这个Listener,我们可以看到很详细的每个transaction它所返回的结果,其中红色是指出错的transaction,绿色则为通过的。
如果你测试的场景会有很多的transaction完成,建议在这个Listener中仅记录出错的transaction就可以了。要做到这样,你只需要将Log/Display:中的Errors勾中就可以了。
在性能测试过程中,我们往往需要将测试结果保存在一个文件当中,这样既可以保存测试结果,也可以为日后的性能测试报告提供更多的素材。
Jmeter中,结果都存放在.jtl或.csv文件。我是把文件保存到.jtl中,进行编码转换后,再将其改成.csv文件格式记录,这样做是因为csv文件格式看起来比较方便,更重要的是这样做可以为二次分析提供很多便利。
我这里所说的二次分析是指除了使用Listener之外,我们还可以对.jtl文件进行再次分析。
选择某个Listener,点击页面中的configure按钮。此时,一个设置界面就会弹出来,建议多勾选如下项:Save
Field Name,Save
Assertion Failure Message。
经过了以上设置,此时保存下来的jtl文件会有如下项:
timeStamp,elapsed,label,responseCode,responseMessage,threadName,dataType,success,failureMessage,bytes,Latency
请求发出的绝对时间,响应时间,请求的标签,返回码,返回消息,请求所属的线程,数据类型,是否成功,失败信息,字节,响应时间
其中聚合报告中的,吞吐量=完成的transaction数/完成这些transaction数所需要的时间;平均响应时间=所有响应时间的总和/完成的transaction数;失败率=失败的个数/transaction数。
————————————————————————————————————————————————————————————
尊重原创转载请说明来源。
Ray
tsbc@vip.qq.com
标签:
原文地址:http://www.cnblogs.com/tsbc/p/4806731.html