一:问题
基于LAN或WAN的网络应用之间进行数据传输或者同步非常普遍,比如远程数据镜像、备份、复制、同步,数据下载、上传、共享等等
二:简单解决
简单复制会带来较大的带宽,同步或传输时间也会较长
三:RSYNC和RDC是两种常见算法,仅仅传输差异数据,并节省带宽
四:Rsync算法
假设现在有两台计算机Alpha和Beta ,计算机Alpha能够访问A文件,计算机Beta能够访问B文件,文件A和B非常相似,计算机Alpha和Beta通过低速网络互联
1、Beta将文件B分割成连续不重叠的固定大小数据块S,最后一个数据块可能会小于S字节
2、Beta对于每一个数据块,计算出两个校验值,一个32位的弱滚动校验和一个128位的MD4校验;
3、Beta将校验值发送给Alpha;
4、Alpha通过搜索文件A的所有大小为S的数据块(偏移量可以任意,不一定非要是S的倍数),来寻找与文件B的某一块有着相同的弱校验码和强校验码的数据块。这主要由滚动校验Rolling checksum快速完成;
5、Alpha给Beta发送重构A文件的指令,每一条指令是一个文件B数据块引用(匹配)或者是文件A数据块(未匹配)。
五:不足
1、Rolling checksum虽然可以节省大量checksum校验计算量,也对checksum搜索作了优化,但多出一倍以上的hash查找,这个消耗不小;
2、Rsync算法中,Alpha和Beta计算量是不对等的,Alpha计算量非常大,而Bete计算量非常小。通常Alpha是服务器,因此压力较大;
3、Rsync中数据块大小是固定的,对数据变化的适应能力有限。
六:RDC算法
RDC算法要求Alpha和Beta通过一致的规则对File-New和File-Old分别进行分块,然后对每个块计算 SH, Beta把每个块的SH值发给Alpha , Alpha对两组SH进行diff,就可以知道有哪些块不同,哪些块被删掉了,哪些块被添加了。 RDC的关键在于分块规则,也使用WH,要让同一规则应用于File-Old和File-New的时候,分出来的块能够尽量体现出区别。
七:举例
File-Old包含"I Love Playing Basketball”,
File-New是"I Like Playing Football"。
RSync算法
Host-A能够计算出准确的差别,"I Like Playing Football" 黄色部分修改了,绿色部分是增加的,精确到每个字符,Host-A主要告诉Host-B:"把第4-6号字符换成‘ike‘,把16-21号字符去掉,插 入‘Foot‘”。
RDC算法
File-Old分块的结果,分成3块。
"I Love Playing Basketball”
File-New分块的结果,分成3块。
"I Like Playing Football"
Host-A经过比对,发现只有File-Old的第2块和File-New的第2块匹配,于是就告诉Host-B:"把你的第一块换成‘I Like’,把你的第3块换成‘Football’”
RDC相对而言比较浪费,相比RSync,要多传输一些数据,但是Host-A和Host-B的计算量比较平均。为了让RDC发挥 好的性能,一定要制定一个好的分块机制,让包含Diff的块尽量少包含没有Diff的数据,怎么做到这一点呢,还要靠WH,通过rolling checksum来从数据中快速挖掘出数据的性质。
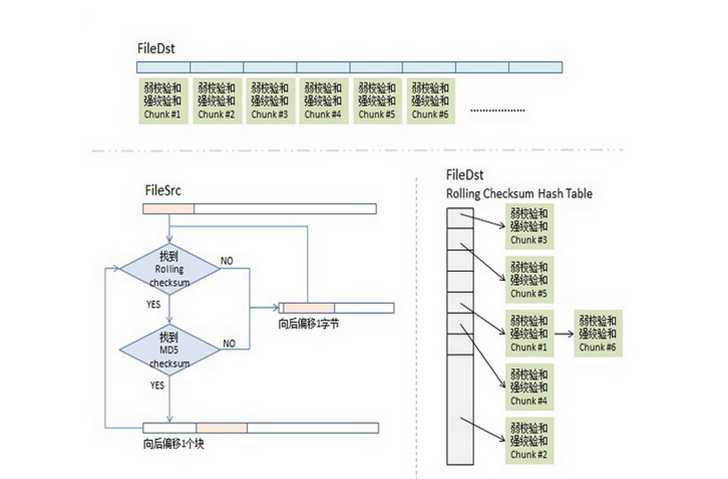
八:RSync算法详细
同步目标端会把fileDst的一个checksum列表传给同步源,这个列表里包括了三个东西,rolling checksum(32bits),md5 checksume(128bits),文件块编号。
为了实现查找的O(1)的查找复杂度,会将checksum 放入到一个hashtable中
1、取fileSrc的第一个文件块(我们假设的是512个长度),也就是从fileSrc的第1个字节到第512个字节,取出来后做rolling checksum计算。计算好的值到hash表中查。
2、如果查到了,说明发现在fileDst中有潜在相同的文件块,于是就再比较 md5的checksum,因为rolling checksume太弱了,可能发生碰撞。于是还要算md5的128bits的checksum,这样一来,我们就有 2^-(32+128) = 2^-160的概率发生碰撞,这太小了可以忽略。如果rolling checksum和md5 checksum都相同,这说明在fileDst中有相同的块,我们需要记下这一块在fileDst下的文件编号。
3、如果fileSrc的rolling checksum 没有在hash table中找到,那就不用算md5 checksum了。表示这一块中有不同的信息。总之,只要rolling checksum 或 md5 checksum 其中有一个在fileDst的checksum hash表中找不到匹配项,那么就会触发算法对fileSrc的rolling动作。于是,算法会住后step 1个字节,取fileSrc中字节2-513的文件块要做checksum,go to (1) -
现在你明白什么叫rolling checksum了吧。
4这样,我们就可以找出fileSrc相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
最后再来一张 从别处借过来的图,地址为http://coolshell.cn/articles/7425.html
原文地址:http://www.cnblogs.com/glories/p/3845306.html