标签:
连接建立起来之后,我们就可以通过UDT Socket进行数据的收发了。先来看用来发送数据的几个函数。UDT提供了如下的几个函数用于不同目的下的数据发送:
UDT_API int send(UDTSOCKET u, const char* buf, int len, int flags); UDT_API int sendmsg(UDTSOCKET u, const char* buf, int len, int ttl = -1, bool inorder = false); UDT_API int64_t sendfile(UDTSOCKET u, std::fstream& ifs, int64_t& offset, int64_t size, int block = 364000); UDT_API int64_t sendfile2(UDTSOCKET u, const char* path, int64_t* offset, int64_t size, int block = 364000);
send()用来进行流式的数据发送;sendmsg()用来进行数据报式的数据发送;sendfile()与sendfile2()用来执行文件的发送,流式发送,这两者基本一样,仅有的差异在于,前者接收文件的流来发送,而后者则接收文件的路径。
这里先来看UDT::sendmsg():
int CUDT::sendmsg(UDTSOCKET u, const char* buf, int len, int ttl, bool inorder) {
try {
CUDT* udt = s_UDTUnited.lookup(u);
return udt->sendmsg(buf, len, ttl, inorder);
} catch (CUDTException &e) {
s_UDTUnited.setError(new CUDTException(e));
return ERROR;
} catch (bad_alloc&) {
s_UDTUnited.setError(new CUDTException(3, 2, 0));
return ERROR;
} catch (...) {
s_UDTUnited.setError(new CUDTException(-1, 0, 0));
return ERROR;
}
}
int sendmsg(UDTSOCKET u, const char* buf, int len, int ttl, bool inorder) {
return CUDT::sendmsg(u, buf, len, ttl, inorder);
}
这个API的实现结构与之前看到的listen()、bind()这些略微有点区别,在CUDT的API层,会调用CUDT 对应的实现函数,调用过程:UDT::sendmsg() -> CUDT::sendmsg(UDTSOCKET u, const char* buf, int len, int ttl, bool inorder) -> CUDT::sendmsg(const char* data, int len, int msttl, bool inorder)。直接来看CUDT::sendmsg(const char* data, int len, int msttl, bool inorder)(src/core.cpp):
void CUDT::waitBlockingSending(int space) {
if (!m_bSynSending)
throw CUDTException(6, 1, 0);
else {
// wait here during a blocking sending
#ifndef WIN32
pthread_mutex_lock(&m_SendBlockLock);
if (m_iSndTimeOut < 0) {
while (!m_bBroken && m_bConnected && !m_bClosing
&& ((m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize < space) && m_bPeerHealth)
pthread_cond_wait(&m_SendBlockCond, &m_SendBlockLock);
} else {
uint64_t exptime = CTimer::getTime() + m_iSndTimeOut * 1000ULL;
timespec locktime;
locktime.tv_sec = exptime / 1000000;
locktime.tv_nsec = (exptime % 1000000) * 1000;
while (!m_bBroken && m_bConnected && !m_bClosing
&& ((m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize < space) && m_bPeerHealth
&& (CTimer::getTime() < exptime))
pthread_cond_timedwait(&m_SendBlockCond, &m_SendBlockLock, &locktime);
}
pthread_mutex_unlock(&m_SendBlockLock);
#else
if (m_iSndTimeOut < 0) {
while (!m_bBroken && m_bConnected && !m_bClosing
&& ((m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize < space) && m_bPeerHealth)
WaitForSingleObject(m_SendBlockCond, INFINITE);
} else {
uint64_t exptime = CTimer::getTime() + m_iSndTimeOut * 1000ULL;
while (!m_bBroken && m_bConnected && !m_bClosing
&& ((m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize < space) && m_bPeerHealth
&& (CTimer::getTime() < exptime))
WaitForSingleObject(m_SendBlockCond, DWORD((exptime - CTimer::getTime()) / 1000));
}
#endif
// check the connection status
if (m_bBroken || m_bClosing)
throw CUDTException(2, 1, 0);
else if (!m_bConnected)
throw CUDTException(2, 2, 0);
else if (!m_bPeerHealth) {
m_bPeerHealth = true;
throw CUDTException(7);
}
}
}
int CUDT::sendmsg(const char* data, int len, int msttl, bool inorder) {
if (UDT_STREAM == m_iSockType)
throw CUDTException(5, 9, 0);
// throw an exception if not connected
if (m_bBroken || m_bClosing)
throw CUDTException(2, 1, 0);
else if (!m_bConnected)
throw CUDTException(2, 2, 0);
if (len <= 0)
return 0;
if (len > m_iSndBufSize * m_iPayloadSize)
throw CUDTException(5, 12, 0);
CGuard sendguard(m_SendLock);
if (m_pSndBuffer->getCurrBufSize() == 0) {
// delay the EXP timer to avoid mis-fired timeout
uint64_t currtime;
CTimer::rdtsc(currtime);
m_ullLastRspTime = currtime;
}
if ((m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize < len) {
waitBlockingSending(len);
}
if ((m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize < len) {
if (m_iSndTimeOut >= 0)
throw CUDTException(6, 3, 0);
return 0;
}
// record total time used for sending
if (0 == m_pSndBuffer->getCurrBufSize())
m_llSndDurationCounter = CTimer::getTime();
// insert the user buffer into the sening list
m_pSndBuffer->addBuffer(data, len, msttl, inorder);
// insert this socket to the snd list if it is not on the list yet
m_pSndQueue->m_pSndUList->update(this, false);
if (m_iSndBufSize <= m_pSndBuffer->getCurrBufSize()) {
// write is not available any more
s_UDTUnited.m_EPoll.update_events(m_SocketID, m_sPollID, UDT_EPOLL_OUT, false);
}
return len;
}
CUDT::sendmsg()主要做了如下这样的一些事情:
1. 检查UDT Socket的类型SockType,若为UDT_STREAM则直接抛异常退出,否则继续执行。
2. 检查CUDT的状态,若UDT Socket不处于Connected状态,就抛异常退出,否则继续执行。
3. 检查传入的参数,主要是数据的长度,既不能太大也不能太小。数据长度太小是指,小于等于0;太大是指,超出了CUDT发送缓冲区的最大大小。若参数无效,就返回,否则继续执行。
4. 当CUDT发送缓冲区的已用大小为0时,会将m_ullLastRspTime更新为当前时间。
5. 检查CUDT发送缓冲区中可用大小,若可用大小不足消息的长度时,执行waitBlockingSending()等待有足够大小可用。在waitBlockingSending()中可以看到,它主要处理了这样3中情况:
(1). UDT Socket不是处于同步发送模式。抛异常,结束发送的整个流程。
(2). 发送的超时时间m_iSndTimeOut为一个小于0的无效值,则永久等待,直到UDT Socket被关掉。
(3). 发送的超时时间m_iSndTimeOut为一个大于等于0的有效值,则等待m_iSndTimeOut个ms或UDT Socket被关闭。在CUDT的构造函数中,iSndTimeOut默认是被设置为-1的,但可以通过UDT::setsockopt()进行设置。
对于后两种情况里,若等待过程是由于CUDT状态变得无效而终止,则还将抛出异常以结束发送过程。
6. 检查CUDT发送缓冲区中可用大小,若可用大小不足消息的长度时,则说明waitBlockingSending()可能是因如下的几种情况中的一种出现而结束:
(1). CUDT处于非同步发送模式而直接结束。
(2). CUDT处于同步模式,m_iSndTimeOut为一个有效值,但超市时间到来时仍然没有等到发送缓冲区中有足够的空间。
对于第一种情况的处理是直接返回0。对于第二种情况的处理则是抛出异常。waitBlockingSending()等待过程终结由于UDT Socket而造成的情况,waitBlockingSending()自己会抛出异常的,而不会走到这一步。
7. 当发送缓冲区的已用大小为0时,更新m_llSndDurationCounter为当前时间。
8. 执行m_pSndBuffer->addBuffer(data, len, msttl, inorder)将要发送的数据放入发送缓冲区。
9. 将这个socket加入发送队列SndQueue的发送列表m_pSndUList中。
10. 返回数据长度,也即发送的数据长度。
这也是一个生产与消费的故事。在这里发起发送的线程为生产者,真正将数据发送到网络上的的发送队列RcvQueue的worker线程则为消费者。在UDT::sendmsg()的执行过程中,我们同样只能看到这个故事的一半,生产的那一半。后面会再来分析故事的另一半。
然后来看UDT::send()(src/api.cpp):
int CUDT::send(UDTSOCKET u, const char* buf, int len, int) {
try {
CUDT* udt = s_UDTUnited.lookup(u);
return udt->send(buf, len);
} catch (CUDTException &e) {
s_UDTUnited.setError(new CUDTException(e));
return ERROR;
} catch (bad_alloc&) {
s_UDTUnited.setError(new CUDTException(3, 2, 0));
return ERROR;
} catch (...) {
s_UDTUnited.setError(new CUDTException(-1, 0, 0));
return ERROR;
}
}
int send(UDTSOCKET u, const char* buf, int len, int flags) {
return CUDT::send(u, buf, len, flags);
}
调用用过程:UDT::send() -> CUDT::send(UDTSOCKET u, const char* buf, int len, int) -> CUDT::send(const char* data, int len)。直接来看CUDT::send(const char* data, int len)(src/core.cpp):
int CUDT::send(const char* data, int len) {
if (UDT_DGRAM == m_iSockType)
throw CUDTException(5, 10, 0);
// throw an exception if not connected
if (m_bBroken || m_bClosing)
throw CUDTException(2, 1, 0);
else if (!m_bConnected)
throw CUDTException(2, 2, 0);
if (len <= 0)
return 0;
CGuard sendguard(m_SendLock);
if (m_pSndBuffer->getCurrBufSize() == 0) {
// delay the EXP timer to avoid mis-fired timeout
uint64_t currtime;
CTimer::rdtsc(currtime);
m_ullLastRspTime = currtime;
}
if (m_iSndBufSize <= m_pSndBuffer->getCurrBufSize()) {
waitBlockingSending(1);
}
if (m_iSndBufSize <= m_pSndBuffer->getCurrBufSize()) {
if (m_iSndTimeOut >= 0)
throw CUDTException(6, 3, 0);
return 0;
}
int size = (m_iSndBufSize - m_pSndBuffer->getCurrBufSize()) * m_iPayloadSize;
if (size > len)
size = len;
// record total time used for sending
if (0 == m_pSndBuffer->getCurrBufSize())
m_llSndDurationCounter = CTimer::getTime();
// insert the user buffer into the sening list
m_pSndBuffer->addBuffer(data, size);
// insert this socket to snd list if it is not on the list yet
m_pSndQueue->m_pSndUList->update(this, false);
if (m_iSndBufSize <= m_pSndBuffer->getCurrBufSize()) {
// write is not available any more
s_UDTUnited.m_EPoll.update_events(m_SocketID, m_sPollID, UDT_EPOLL_OUT, false);
}
return size;
}
这个函数与CUDT::sendmsg(const char* data, int len, int msttl, bool inorder)的执行过程极为相似,但还是有如下这样的一些区别:
1. 这个函数的执行要求UDT Socket的类型必须为UDT_STREAM,而不是UDT_DGRAM,这一点与CUDT::sendmsg()正好相反。
2. 要发送的数据的长度,只要大于0就可以了。而在CUDT::sendmsg()中会限制要发送的数据的大小不能超过发送缓冲区的最大大小。
3. 在CUDT::sendmsg()中对数据发送的规则执行的是,要么全部发送,要么一点也不发送。而在这里则是,只要发送缓冲区还没有满,则会将数据尽可能多的加进发送缓冲区以待发送。
其它则完全一样。
来看一下CUDT中用来管理待发送数据的发送缓冲区CSndBuffer,先来看它的定义:
class CSndBuffer {
public:
CSndBuffer(int size = 32, int mss = 1500);
~CSndBuffer();
// Functionality:
// Insert a user buffer into the sending list.
// Parameters:
// 0) [in] data: pointer to the user data block.
// 1) [in] len: size of the block.
// 2) [in] ttl: time to live in milliseconds
// 3) [in] order: if the block should be delivered in order, for DGRAM only
// Returned value:
// None.
void addBuffer(const char* data, int len, int ttl = -1, bool order = false);
// Functionality:
// Read a block of data from file and insert it into the sending list.
// Parameters:
// 0) [in] ifs: input file stream.
// 1) [in] len: size of the block.
// Returned value:
// actual size of data added from the file.
int addBufferFromFile(std::fstream& ifs, int len);
// Functionality:
// Find data position to pack a DATA packet from the furthest reading point.
// Parameters:
// 0) [out] data: the pointer to the data position.
// 1) [out] msgno: message number of the packet.
// Returned value:
// Actual length of data read.
int readData(char** data, int32_t& msgno);
// Functionality:
// Find data position to pack a DATA packet for a retransmission.
// Parameters:
// 0) [out] data: the pointer to the data position.
// 1) [in] offset: offset from the last ACK point.
// 2) [out] msgno: message number of the packet.
// 3) [out] msglen: length of the message
// Returned value:
// Actual length of data read.
int readData(char** data, const int offset, int32_t& msgno, int& msglen);
// Functionality:
// Update the ACK point and may release/unmap/return the user data according to the flag.
// Parameters:
// 0) [in] offset: number of packets acknowledged.
// Returned value:
// None.
void ackData(int offset);
// Functionality:
// Read size of data still in the sending list.
// Parameters:
// None.
// Returned value:
// Current size of the data in the sending list.
int getCurrBufSize() const;
private:
void increase();
private:
pthread_mutex_t m_BufLock; // used to synchronize buffer operation
struct Block {
char* m_pcData; // pointer to the data block
int m_iLength; // length of the block
int32_t m_iMsgNo; // message number
uint64_t m_OriginTime; // original request time
int m_iTTL; // time to live (milliseconds)
Block* m_pNext; // next block
}*m_pBlock, *m_pFirstBlock, *m_pCurrBlock, *m_pLastBlock;
// m_pBlock: The head pointer
// m_pFirstBlock: The first block
// m_pCurrBlock: The current block
// m_pLastBlock: The last block (if first == last, buffer is empty)
struct Buffer {
char* m_pcData; // buffer
int m_iSize; // size
Buffer* m_pNext; // next buffer
}*m_pBuffer; // physical buffer
int32_t m_iNextMsgNo; // next message number
int m_iSize; // buffer size (number of packets)
int m_iMSS; // maximum seqment/packet size
int m_iCount; // number of used blocks
private:
CSndBuffer(const CSndBuffer&);
CSndBuffer& operator=(const CSndBuffer&);
};
在这个结构中,似乎在用几个单链表来管理发送缓冲区的数据存储区,struct Buffer的链表,和struct Block的链表,但这些结构究竟如何组织,每个链表的意义是什么,还是要看下几个成员函数的定义。首先是构造函数:
CSndBuffer::CSndBuffer(int size, int mss)
: m_BufLock(),
m_pBlock(NULL),
m_pFirstBlock(NULL),
m_pCurrBlock(NULL),
m_pLastBlock(NULL),
m_pBuffer(NULL),
m_iNextMsgNo(1),
m_iSize(size),
m_iMSS(mss),
m_iCount(0) {
// initial physical buffer of "size"
m_pBuffer = new Buffer;
m_pBuffer->m_pcData = new char[m_iSize * m_iMSS];
m_pBuffer->m_iSize = m_iSize;
m_pBuffer->m_pNext = NULL;
// circular linked list for out bound packets
m_pBlock = new Block;
Block* pb = m_pBlock;
for (int i = 1; i < m_iSize; ++i) {
pb->m_pNext = new Block;
pb->m_iMsgNo = 0;
pb = pb->m_pNext;
}
pb->m_pNext = m_pBlock;
pb = m_pBlock;
char* pc = m_pBuffer->m_pcData;
for (int i = 0; i < m_iSize; ++i) {
pb->m_pcData = pc;
pb = pb->m_pNext;
pc += m_iMSS;
}
m_pFirstBlock = m_pCurrBlock = m_pLastBlock = m_pBlock;
#ifndef WIN32
pthread_mutex_init(&m_BufLock, NULL);
#else
m_BufLock = CreateMutex(NULL, false, NULL);
#endif
}
在这个构造函数中会做如下这样一些事情:
1. 在成员初始化列表中初始化所有的成员变量。注意,m_iNextMsgNo被初始化为了1,表示已用blocks数量的m_iCount被初始化为了0。
初始化物理buffer,即分配一个Buffer结构m_pBuffer,为这个Buffer结构分配一块大小为m_iSize * m_iMSS的内存,初始化Buffer结构的m_iSize为m_iSize。m_iSize和m_iMSS的值来自于传入的两个参数size和mss。在connect成功(无论是主动发起连接的UDT Socket,还是由Listening的UDT Socket创建的都一样),创建CSndBuffer时,size值为32,而mss值为m_iPayloadSize。在前面 UDT协议实现分析——连接的建立 一文中我们有仔细地分析过m_iPayloadSize这个值的计算过程。
2. 创建一个Block结构的循环链表,m_pBlock指向链表头。链表的长度同样为m_iSize,也就是32。
3. 初始化前一步创建的链表。使每个Block结构的m_pcData指向m_pBuffer->m_pcData的不同位置,相邻的两个Block结构,所指位置的距离为m_iMSS。
由此不难猜测,Buffer用于实际保存要发送的数据。而Block结构则用于将Buffer的数据缓冲区分段管理。
4. 将m_pFirstBlock、m_pCurrBlock和m_pLastBlock的值都初始化为m_pBlock的值。
5. 初始化用于同步缓冲区操作的m_BufLock。
这里我们弄清了struct Buffer和struct Block,但还是有许多问题还没有弄清楚。m_pBlock,m_pFirstBlock,m_pCurrBlock和m_pLastBlock这几个指针的含义是什么?struct Buffer链表的扩展与收缩,MsgNo的意义等。
接着就来看一下CSndBuffer的其它一些成员函数。来看向CSndBuffer中添加数据的CSndBuffer::addBuffer():
void CSndBuffer::addBuffer(const char* data, int len, int ttl, bool order) {
int size = len / m_iMSS;
if ((len % m_iMSS) != 0)
size++;
// dynamically increase sender buffer
while (size + m_iCount >= m_iSize)
increase();
uint64_t time = CTimer::getTime();
int32_t inorder = order;
inorder <<= 29;
Block* s = m_pLastBlock;
for (int i = 0; i < size; ++i) {
int pktlen = len - i * m_iMSS;
if (pktlen > m_iMSS)
pktlen = m_iMSS;
memcpy(s->m_pcData, data + i * m_iMSS, pktlen);
s->m_iLength = pktlen;
s->m_iMsgNo = m_iNextMsgNo | inorder;
if (i == 0)
s->m_iMsgNo |= 0x80000000;
if (i == size - 1)
s->m_iMsgNo |= 0x40000000;
s->m_OriginTime = time;
s->m_iTTL = ttl;
s = s->m_pNext;
}
m_pLastBlock = s;
CGuard::enterCS(m_BufLock);
m_iCount += size;
CGuard::leaveCS(m_BufLock);
m_iNextMsgNo++;
if (m_iNextMsgNo == CMsgNo::m_iMaxMsgNo)
m_iNextMsgNo = 1;
}
这个函数的执行过程大体如下:
1. 向CSndBuffer中添加数据总是以整块Block为单位的,对于最后不满整块Block的数据仍然占用整块Block。在这个函数中做的第一件事情就是,计算添加所有的数据需要的Block的个数。
2. 如果CSndBuffer中的可用空间不足,则扩展CSndBuffer空间的大小,直到能满足添加的数据的需求为止。
3. 计算inorder。
4. 通过一个循环将数据复制到CSndBuffer中。
在这段code中,我们不难想到m_pLastBlock指向的是最后一块已用Block之后的那块Block。
关于UDT的Msg,Msg指的是一次UDT::send()或UDT::sendmsg()所发的全部数据。一个Msg中所有的Block共用了相同的一个m_iNextMsgNo。
这里可以看到UDT中Msg的开始与结束的表示方法:Block的m_iMsgNo的最高两位被用来指示Msg的开始和结束,最高位为1表示Msg的开始,第二高位为1则表示Msg的结束。
5. 更新表示一用Block数的m_iCount。
6. 更新m_iNextMsgNo,达到最大值时会重新回到1。
再来看一个与CSndBuffer::addBuffer()类似的函数CSndBuffer::addBufferFromFile():
int CSndBuffer::addBufferFromFile(fstream& ifs, int len) {
int size = len / m_iMSS;
if ((len % m_iMSS) != 0)
size++;
// dynamically increase sender buffer
while (size + m_iCount >= m_iSize)
increase();
Block* s = m_pLastBlock;
int total = 0;
for (int i = 0; i < size; ++i) {
if (ifs.bad() || ifs.fail() || ifs.eof())
break;
int pktlen = len - i * m_iMSS;
if (pktlen > m_iMSS)
pktlen = m_iMSS;
ifs.read(s->m_pcData, pktlen);
if ((pktlen = ifs.gcount()) <= 0)
break;
// currently file transfer is only available in streaming mode, message is always in order, ttl = infinite
s->m_iMsgNo = m_iNextMsgNo | 0x20000000;
if (i == 0)
s->m_iMsgNo |= 0x80000000;
if (i == size - 1)
s->m_iMsgNo |= 0x40000000;
s->m_iLength = pktlen;
s->m_iTTL = -1;
s = s->m_pNext;
total += pktlen;
}
m_pLastBlock = s;
CGuard::enterCS(m_BufLock);
m_iCount += size;
CGuard::leaveCS(m_BufLock);
m_iNextMsgNo++;
if (m_iNextMsgNo == CMsgNo::m_iMaxMsgNo)
m_iNextMsgNo = 1;
return total;
}
这个函数的执行过程,与CSndBuffer::addBuffer()的执行过程极为相似,仅有的差别在于,在这个函数,是将文件的数据逐步的read进CSndBuffer,而在addBuffer()中则是memcpy。
在CSndBuffer::addBuffer()与CSndBuffer::addBufferFromFile()中有这么多的重复code,实在是很有进一步进行抽象的空间。在循环中拷贝数据时,每次计算剩余了多少字节,然后和m_iMSS进行比较以确定到底要复制多少数据。这种计算和比较在大多数情况下都比较多余,只有在循环的最后一次执行时才真正需要这样的操作。可以通过特殊处理最后一块数据的复制,并将循环的退出条件值改为(size -1)来提升性能。
我们前面提到了CSndBuffer容量的扩展,那这里就来看一下执行单次扩展的increase():
void CSndBuffer::increase() {
int unitsize = m_pBuffer->m_iSize;
// new physical buffer
Buffer* nbuf = NULL;
try {
nbuf = new Buffer;
nbuf->m_pcData = new char[unitsize * m_iMSS];
} catch (...) {
delete nbuf;
throw CUDTException(3, 2, 0);
}
nbuf->m_iSize = unitsize;
nbuf->m_pNext = NULL;
// insert the buffer at the end of the buffer list
Buffer* p = m_pBuffer;
while (NULL != p->m_pNext)
p = p->m_pNext;
p->m_pNext = nbuf;
// new packet blocks
Block* nblk = NULL;
try {
nblk = new Block;
} catch (...) {
delete nblk;
throw CUDTException(3, 2, 0);
}
Block* pb = nblk;
for (int i = 1; i < unitsize; ++i) {
pb->m_pNext = new Block;
pb = pb->m_pNext;
}
// insert the new blocks onto the existing one
pb->m_pNext = m_pLastBlock->m_pNext;
m_pLastBlock->m_pNext = nblk;
pb = nblk;
char* pc = nbuf->m_pcData;
for (int i = 0; i < unitsize; ++i) {
pb->m_pcData = pc;
pb = pb->m_pNext;
pc += m_iMSS;
}
m_iSize += unitsize;
}
可以看下执行单次容量扩充的含义及过程:
1. 获取CSndBuffer中已有的Block的总数量unitsize。
2. 创建一个Buffer结构,并为它分配数据缓冲区,数据缓冲区的大小为unitsize个Block。由此可见,每一次CSndBuffer的扩展,都会使它的容量加倍。
3. 将前一步创建的Buffer插入到已有的Buffer单链表的尾部。
4. 为前面创建的Buffer,创建对应的Block结构链表,nblk指向这个单链表的头节点,而pb指向这个单链表的尾节点。
5. 如我们前面提到的CSndBuffer中的Block结构是一个循环单向链表,这一步即是将前一步创建的Block单向链表插入CSndBuffer的Block循环链表中。
6. 设置前面创建的所有Block,使它们指向前面创建的Buffer的数据部分的适当位置。
7. 更新表示CSndBuffer中总的Block大小的m_iSize。
如我们前面了解到的,发送数据也是一个生产与消费的故事,UDT::send()和UDT::sendmsg()讲的是生产的故事,至此我们基本上将生产的故事都理清了,接着就来看下消费的故事,也就是CSndQueue中的实际数据发送。
接着来讲数据发送这个生产-消费故事的另一半,也就是消费的那一半,发送队列CSndQueue中实际的数据发送。先来瞅一下CSndQueue的定义(src/queue.h):
class CSndQueue {
friend class CUDT;
friend class CUDTUnited;
public:
CSndQueue();
~CSndQueue();
public:
// Functionality:
// Initialize the sending queue.
// Parameters:
// 1) [in] c: UDP channel to be associated to the queue
// 2) [in] t: Timer
// Returned value:
// None.
void init(CChannel* c, CTimer* t);
// Functionality:
// Send out a packet to a given address.
// Parameters:
// 1) [in] addr: destination address
// 2) [in] packet: packet to be sent out
// Returned value:
// Size of data sent out.
int sendto(const sockaddr* addr, CPacket& packet);
private:
#ifndef WIN32
static void* worker(void* param);
#else
static DWORD WINAPI worker(LPVOID param);
#endif
pthread_t m_WorkerThread;
private:
CSndUList* m_pSndUList; // List of UDT instances for data sending
CChannel* m_pChannel; // The UDP channel for data sending
CTimer* m_pTimer; // Timing facility
pthread_mutex_t m_WindowLock;
pthread_cond_t m_WindowCond;
volatile bool m_bClosing; // closing the worker
pthread_cond_t m_ExitCond;
private:
CSndQueue(const CSndQueue&);
CSndQueue& operator=(const CSndQueue&);
};
这个class,不管是成员变量,还是成员函数,看上去基本都还比较亲切,其作用不会让人完全无感,但唯独一个成员变量,也就是CSndUList的m_pSndUList。因而这里就先来看一下这个类。先来看CSndUList的定义:
struct CSNode {
CUDT* m_pUDT; // Pointer to the instance of CUDT socket
uint64_t m_llTimeStamp; // Time Stamp
int m_iHeapLoc; // location on the heap, -1 means not on the heap
};
class CSndUList {
friend class CSndQueue;
public:
CSndUList();
~CSndUList();
public:
// Functionality:
// Insert a new UDT instance into the list.
// Parameters:
// 1) [in] ts: time stamp: next processing time
// 2) [in] u: pointer to the UDT instance
// Returned value:
// None.
void insert(int64_t ts, const CUDT* u);
// Functionality:
// Update the timestamp of the UDT instance on the list.
// Parameters:
// 1) [in] u: pointer to the UDT instance
// 2) [in] resechedule: if the timestampe shoudl be rescheduled
// Returned value:
// None.
void update(const CUDT* u, bool reschedule = true);
// Functionality:
// Retrieve the next packet and peer address from the first entry, and reschedule it in the queue.
// Parameters:
// 0) [out] addr: destination address of the next packet
// 1) [out] pkt: the next packet to be sent
// Returned value:
// 1 if successfully retrieved, -1 if no packet found.
int pop(sockaddr*& addr, CPacket& pkt);
// Functionality:
// Remove UDT instance from the list.
// Parameters:
// 1) [in] u: pointer to the UDT instance
// Returned value:
// None.
void remove(const CUDT* u);
// Functionality:
// Retrieve the next scheduled processing time.
// Parameters:
// None.
// Returned value:
// Scheduled processing time of the first UDT socket in the list.
uint64_t getNextProcTime();
private:
void insert_(int64_t ts, const CUDT* u);
void remove_(const CUDT* u);
private:
CSNode** m_pHeap; // The heap array
int m_iArrayLength; // physical length of the array
int m_iLastEntry; // position of last entry on the heap array
pthread_mutex_t m_ListLock;
pthread_mutex_t* m_pWindowLock;
pthread_cond_t* m_pWindowCond;
CTimer* m_pTimer;
private:
CSndUList(const CSndUList&);
CSndUList& operator=(const CSndUList&);
};
从这个类的定义中,我们大概能感觉到这是一个CSNode的容器,但容器的许多组织的细节则仍然是一头雾水,那就从它的构造函数和成员函数中来厘清这些细节。来看它的构造函数(src/queue.cpp):
CSndUList::CSndUList()
: m_pHeap(NULL),
m_iArrayLength(4096),
m_iLastEntry(-1),
m_ListLock(),
m_pWindowLock(NULL),
m_pWindowCond(NULL),
m_pTimer(NULL) {
m_pHeap = new CSNode*[m_iArrayLength];
#ifndef WIN32
pthread_mutex_init(&m_ListLock, NULL);
#else
m_ListLock = CreateMutex(NULL, false, NULL);
#endif
}
在这个函数中做的事情就是分配了一个CSNode指针的数组,并初始化了一个mutex m_ListLock,但这似乎也无法透漏出太多的讯息。然后来看向其中插入元素的insert():
void CSndUList::insert(int64_t ts, const CUDT* u) {
CGuard listguard(m_ListLock);
// increase the heap array size if necessary
if (m_iLastEntry == m_iArrayLength - 1) {
CSNode** temp = NULL;
try {
temp = new CSNode*[m_iArrayLength * 2];
} catch (...) {
return;
}
memcpy(temp, m_pHeap, sizeof(CSNode*) * m_iArrayLength);
m_iArrayLength *= 2;
delete[] m_pHeap;
m_pHeap = temp;
}
insert_(ts, u);
}
m_iLastEntry是数组中已经被占用的最后一个位置。在这个函数中,做了两件事:
1. 检查m_iLastEntry是否等于m_iArrayLength - 1,若是,则表明数组中所有的位置都被占用了此时则需要扩充容量,这里的做法就是创建一个长度为之前数组长度2倍的新数组,将之前数组中的内容拷贝到新数组里,更新m_iArrayLength,删除之前的数组,更新m_pHeap只想新数组。
2. 执行CSndUList::insert_()进行实际的插入动作。
再来看CSndUList::insert_():
void CSndUList::insert_(int64_t ts, const CUDT* u) {
CSNode* n = u->m_pSNode;
// do not insert repeated node
if (n->m_iHeapLoc >= 0)
return;
m_iLastEntry++;
m_pHeap[m_iLastEntry] = n;
n->m_llTimeStamp = ts;
int q = m_iLastEntry;
int p = q;
while (p != 0) {
p = (q - 1) >> 1;
if (m_pHeap[p]->m_llTimeStamp > m_pHeap[q]->m_llTimeStamp) {
CSNode* t = m_pHeap[p];
m_pHeap[p] = m_pHeap[q];
m_pHeap[q] = t;
t->m_iHeapLoc = q;
q = p;
} else
break;
}
n->m_iHeapLoc = q;
// an earlier event has been inserted, wake up sending worker
if (n->m_iHeapLoc == 0)
m_pTimer->interrupt();
// first entry, activate the sending queue
if (0 == m_iLastEntry) {
#ifndef WIN32
pthread_mutex_lock(m_pWindowLock);
pthread_cond_signal(m_pWindowCond);
pthread_mutex_unlock(m_pWindowLock);
#else
SetEvent(*m_pWindowCond);
#endif
}
}
在这个函数中主要做了这样一些事:
1. 检查要插入的元素是否已经插入了,主要是根据CUDT的CSNode n的HeapLoc字段是否大于0来判断的。若已经插入,则直接返回。
2. 将CSNode放在数组的尾部。
3. 调整CSNode n在数组中的位置,以使它处于适当的位置。要厘清这个地方的调整过程,可能要复习一下我们曾经学习过的堆数据结构了。可以将堆理解为一个用数组表示的二叉树,如下图所示:
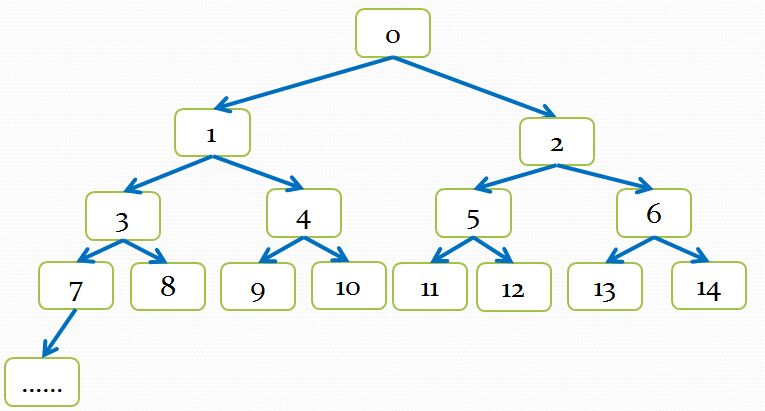
如上图,每个框框中的数字表示该节点在数组中的位置。可以看到一个节点的位置与它的两个子节点及父节点的位置之间的关系:
假设一个节点的位置,也就是该节点在数组中的index为n,则它的父节点的位置为((n -1)/2),而它的两个子几点的位置分别为(2×N+1)和(2×n+2)。
回到CSndUList::insert_()的节点CSNode n的位置调整过程。可以看到,这个过程主要是根据CSNode n的m_llTimeStamp值,若CSNode n的m_llTimeStamp值比它的父节点的m_llTimeStamp小的话就把CSNode n往二叉树的上层浮,而把它的父节点向二叉树的下层沉,依次类推,直到找到某个位置,其父节点的m_llTimeStamp值比它的m_llTimeStamp值小,或者浮到二叉树的最顶层。
由此可见m_pHeap是一个根据CSNode的m_llTimeStamp值建的堆,越往上层,该值越小。而m_pHeap[0]则是整个堆中所有CSNode元素m_llTimeStamp值最小的那个。
4. 更新CSNode n的m_iHeapLoc指向它在数组m_pHeap中的索引。
5. CSNode n被浮到堆的顶部时,唤醒发送队列的worker线程。
6. 插入的如果是堆中的第一个元素的话,唤醒等待在m_pWindowCond上的线程。
看完了插入元素,再来看移除元素也就是CSndUList::remove():
void CSndUList::remove(const CUDT* u) {
CGuard listguard(m_ListLock);
remove_(u);
}
void CSndUList::remove_(const CUDT* u) {
CSNode* n = u->m_pSNode;
if (n->m_iHeapLoc >= 0) {
// remove the node from heap
m_pHeap[n->m_iHeapLoc] = m_pHeap[m_iLastEntry];
m_iLastEntry--;
m_pHeap[n->m_iHeapLoc]->m_iHeapLoc = n->m_iHeapLoc;
int q = n->m_iHeapLoc;
int p = q * 2 + 1;
while (p <= m_iLastEntry) {
if ((p + 1 <= m_iLastEntry) && (m_pHeap[p]->m_llTimeStamp > m_pHeap[p + 1]->m_llTimeStamp))
p++;
if (m_pHeap[q]->m_llTimeStamp > m_pHeap[p]->m_llTimeStamp) {
CSNode* t = m_pHeap[p];
m_pHeap[p] = m_pHeap[q];
m_pHeap[p]->m_iHeapLoc = p;
m_pHeap[q] = t;
m_pHeap[q]->m_iHeapLoc = q;
q = p;
p = q * 2 + 1;
} else
break;
}
n->m_iHeapLoc = -1;
}
// the only event has been deleted, wake up immediately
if (0 == m_iLastEntry)
m_pTimer->interrupt();
}
CSndUList::remove()是直接调用了CSndUList::remove_(),而在CSndUList::remove_()主要做了如下这样一些事情:
1. 先检查要移除的CSNode n是否存在与堆中,主要根据CSNode n的HeapLoc字段是否大于0来判断的。若没有插入,则跳到第5步,否则继续执行。
2. 将m_pHeap中的最末尾的元素放进原本由要移除的CSNode n所占用的位置,更新m_iLastEntry,及被改变了位置的原来的最末尾元素CSNode的m_iHeapLoc指向它当前被放置的位置。
3. 如果被调整了位置的CSNode的新位置不是最末尾的位置,则调整该节点的位置。这里主要是在这个节点的m_llTimeStamp值比它的子节点的m_llTimeStamp值更大时,将这个节点向二叉树层次结构的下层沉,而将它的字节点向上浮的过程。一个节点总是有两个字节点,也就是两棵子树,那它又会向哪一棵那边沉呢?可以看到是字节点中m_llTimeStamp值更小的那一边。
总觉得这里应该再有一个节点上浮的过程。如果移除的节点是最末尾节点的直系父节点,这当然没有问题,但如果不是,则关系还是有许多不确定的地方。
4. 更新CSNode n的m_iHeapLoc指向-1。
5. 如果m_iLastEntry为0,即表示堆中不再有元素了,则还会执行唤醒。
回头看我们前面分析的CUDT::send()和CUDT::sendmsg(),它们都通过m_pSndQueue->m_pSndUList->update(this, false)将CUDT插入CSndUList m_pSndUList,这里再来看一下CSndUList::update():
void CSndUList::update(const CUDT* u, bool reschedule) {
CGuard listguard(m_ListLock);
CSNode* n = u->m_pSNode;
if (n->m_iHeapLoc >= 0) {
if (!reschedule)
return;
if (n->m_iHeapLoc == 0) {
n->m_llTimeStamp = 1;
m_pTimer->interrupt();
return;
}
remove_(u);
}
insert_(1, u);
}
reschedule参数表示的是,如果之前的已经有发送任务,且还没有执行完,则将新的发送任务放在老的之后。
可以看到在这个函数中,如果CSNode还没有被插入堆中,则尽可能将CSNode放如堆的顶部以便于发送任务尽快执行。若已经插入,且reschedule为false,则直接返回。若已经插入,且reschedule为true,则检查一下CSNode当前是否已经在堆的顶部了,若是就退出。若不是,则先将CSNode从堆中移除,然后再尽可能将CSNode插入堆的顶部。
对发送队列CSndQueue所用的数据结构做这么多分析之后,我们再来看它的worker线程,也就是CSndQueue::worker():
CSndQueue::CSndQueue()
: m_WorkerThread(),
m_pSndUList(NULL),
m_pChannel(NULL),
m_pTimer(NULL),
m_WindowLock(),
m_WindowCond(),
m_bClosing(false),
m_ExitCond() {
#ifndef WIN32
pthread_cond_init(&m_WindowCond, NULL);
pthread_mutex_init(&m_WindowLock, NULL);
#else
m_WindowLock = CreateMutex(NULL, false, NULL);
m_WindowCond = CreateEvent(NULL, false, false, NULL);
m_ExitCond = CreateEvent(NULL, false, false, NULL);
#endif
}
CSndQueue::~CSndQueue() {
m_bClosing = true;
#ifndef WIN32
pthread_mutex_lock(&m_WindowLock);
pthread_cond_signal(&m_WindowCond);
pthread_mutex_unlock(&m_WindowLock);
if (0 != m_WorkerThread)
pthread_join(m_WorkerThread, NULL);
pthread_cond_destroy(&m_WindowCond);
pthread_mutex_destroy(&m_WindowLock);
#else
SetEvent(m_WindowCond);
if (NULL != m_WorkerThread)
WaitForSingleObject(m_ExitCond, INFINITE);
CloseHandle(m_WorkerThread);
CloseHandle(m_WindowLock);
CloseHandle(m_WindowCond);
CloseHandle(m_ExitCond);
#endif
delete m_pSndUList;
}
void CSndQueue::init(CChannel* c, CTimer* t) {
m_pChannel = c;
m_pTimer = t;
m_pSndUList = new CSndUList;
m_pSndUList->m_pWindowLock = &m_WindowLock;
m_pSndUList->m_pWindowCond = &m_WindowCond;
m_pSndUList->m_pTimer = m_pTimer;
#ifndef WIN32
if (0 != pthread_create(&m_WorkerThread, NULL, CSndQueue::worker, this)) {
m_WorkerThread = 0;
throw CUDTException(3, 1);
}
#else
DWORD threadID;
m_WorkerThread = CreateThread(NULL, 0, CSndQueue::worker, this, 0, &threadID);
if (NULL == m_WorkerThread)
throw CUDTException(3, 1);
#endif
}
#ifndef WIN32
void* CSndQueue::worker(void* param)
#else
DWORD WINAPI CSndQueue::worker(LPVOID param)
#endif
{
CSndQueue* self = (CSndQueue*) param;
while (!self->m_bClosing) {
uint64_t ts = self->m_pSndUList->getNextProcTime();
if (ts > 0) {
// wait until next processing time of the first socket on the list
uint64_t currtime;
CTimer::rdtsc(currtime);
if (currtime < ts)
self->m_pTimer->sleepto(ts);
// it is time to send the next pkt
sockaddr* addr;
CPacket pkt;
if (self->m_pSndUList->pop(addr, pkt) < 0)
continue;
self->m_pChannel->sendto(addr, pkt);
} else {
// wait here if there is no sockets with data to be sent
#ifndef WIN32
pthread_mutex_lock(&self->m_WindowLock);
if (!self->m_bClosing && (self->m_pSndUList->m_iLastEntry < 0))
pthread_cond_wait(&self->m_WindowCond, &self->m_WindowLock);
pthread_mutex_unlock(&self->m_WindowLock);
#else
WaitForSingleObject(self->m_WindowCond, INFINITE);
#endif
}
}
#ifndef WIN32
return NULL;
#else
SetEvent(self->m_ExitCond);
return 0;
#endif
}
CSndQueue::worker()中的while循环几乎就是CSndQueue的worker线程执行的全部任务了,这个循环的循环体中主要做了如下这样的一些事情:
1. 调用self->m_pSndUList->getNextProcTime(),来查看最近的一次发送任务所需要执行的时间ts。这里来看一下CSndUList::getNextProcTime()的定义:
uint64_t CSndUList::getNextProcTime() {
CGuard listguard(m_ListLock);
if (-1 == m_iLastEntry)
return 0;
return m_pHeap[0]->m_llTimeStamp;
}
若返回值小于等于0,就表示当前没有需要发送的数据,没有需要执行的发送任务。则进入等待状态。在CSndQueue::init()的定义中,CSndUList m_pSndUList的m_pWindowLock和m_pWindowCond会分别指向CSndQueue的m_WindowLock和m_WindowCond,因而可见,这个地方的等待,是被CSndUList::insert_()唤醒的。
若返回值大于0,则表明存在着需要执行的发送任务。此时则执行下一步。
2. 获取当前的时间currtime。比较currtime与ts,若前者较小,则表明最近需要执行的发送任务它请求的执行时间还没到,则休眠等待直到ts的到来。如我们前面的分析,并根据CSndQueue::init()的定义可见,向m_pSndUList中插入、移除或更新元素,都可能会唤醒这里的等待。若前者较大,或者等待的时刻到了则执行下一步。
3. 执行self->m_pSndUList->pop(addr, pkt),从CSndUList m_pSndUList中抓一个CPacket出来。若没抓到,则进入下一次循环,否则发送抓到的CPacket。来看CSndUList::pop():
int CSndUList::pop(sockaddr*& addr, CPacket& pkt) {
CGuard listguard(m_ListLock);
if (-1 == m_iLastEntry)
return -1;
// no pop until the next schedulled time
uint64_t ts;
CTimer::rdtsc(ts);
if (ts < m_pHeap[0]->m_llTimeStamp)
return -1;
CUDT* u = m_pHeap[0]->m_pUDT;
remove_(u);
if (!u->m_bConnected || u->m_bBroken)
return -1;
// pack a packet from the socket
if (u->packData(pkt, ts) <= 0)
return -1;
addr = u->m_pPeerAddr;
// insert a new entry, ts is the next processing time
if (ts > 0)
insert_(ts, u);
return 1;
}
可以看到CSndUList::pop()做了这样一些事情:
1. 检查m_iLastEntry是否为-1,若为-1,表明没有要执行发送的任务,因而直接返回-1。否则继续执行。
2. 检查当前时间是否小于堆顶元素的m_llTimeStamp,若小于则表明,最近一次发送任务的发送时间还没到,则返回-1,否则继续执行。
3. 获取堆顶元素的CUDT对象u,也就是发送任务的请求者,并将堆顶元素先从对中移除。
4. 检查u的状态,若不处于有效的连接状态,则返回-1,否则继续执行。
5. 执行u->packData(pkt, ts)打出一个数据包来。
6. 使传进来的addr只想CUDT u的PeerAddr,CSndQueue会将这个地址作为包的发送目的地址。
7. 将CUDT u重新插入堆中,时间戳为当前时间,这也就意味着,如果可以的话,就在下一个循环中继续发送CUDT u的数据。
8. 返回1。
在发送队列CSndQueue的worker线程中,最最需要的是尽可能快的获得最近需要执行的发送任务的一些信息。CSndUList::getNextProcTime()和CSndUList::pop()中获取的最主要的信息也是堆顶元素的一些信息。一个严格依照请求的执行时间进行排列的列表意义并不是很大,为了保证这种有序性反倒可能需要消耗不少的时间,采用堆却可以想CSndQueue的worker线程尽可能快的返回最近将要执行的发送任务请求执行的时间。
Done。
标签:
原文地址:http://my.oschina.net/wolfcs/blog/506021